

Il est impossible de ne pas avoir remarqué le changement fondamental qui s'est opéré ces dernières années dans la manière dont le contenu est produit et consommé sur le Web. Quelle que soit votre opinion sur le sujet, l'IA semble être un thème de conversation omniprésent, avec d'un côté les maximalistes de l'IA, les évangélistes de l'AGI et les passionnés, et de l'autre les sceptiques, les détracteurs et les adeptes de la théorie de l'apocalypse robotique.
La vérité se trouve probablement quelque part au milieu. Mais une chose est sûre : le débat sur le rôle des Scrapers (bots d'exploration) et des Crawlers (bots d'indexation) et sur l'utilisation des données qu'ils collectent est indéniable.
Tout d’abord, il y a la question très légitime de la violation du droit d’auteur. Dans quelle mesure les grands modèles de langage sont-ils une source de transformation ? Comme l'a dit un jour Pablo Picasso avec humour, « les bons artistes copient, les grands artistes volent », et il est difficile de nier que l'histoire de l'art a été alimentée par la réinvention et la réinterprétation des inspirations de nos prédécesseurs. Retracer la lignée de toute forme d'art montre une évolution constante au fil des générations. Et, à plus petite échelle, combien de jeunes artistes ont commencé par copier leurs images ou bandes dessinées préférées ? Combien de groupes ont commencé en faisant des reprises de leurs chansons préférées ?
Cependant, cela reste distinct. Récupérer du contenu pour le transformer mécaniquement et mathématiquement en une copie conforme ne ressemble pas à un hommage ; cela s'apparente davantage, d'un point de vue émotionnel, à du vol.
Par ailleurs, ces mêmes bots d'indexation ont souvent un comportement inapproprié : ils ignorent les normes bien établies telles que robots.txt, prennent des mesures pour dissimuler leurs adresses IP et soumettent les sites à des requêtes répétées [1, 2, 3]. De plus, le trafic est plus coûteux : Wikipédia indique que, bien que les bots représentent 35 % de l'ensemble du trafic, ils consomment 65 % de toutes les ressources.
Cela semble inéquitable et injuste, et de nombreuses personnes, même celles qui sont enthousiastes à l'égard de l'IA, estiment qu'il est nécessaire de prendre des mesures pour rétablir l'équilibre.
Découvrez la norme RSL (Really Simple Licensing). Il s'agit d'un format de document ouvert, basé sur XML, permettant de définir les conditions d'utilisation et de licence des contenus lisibles par machine pour les ressources numériques, notamment les sites Web, les pages Web, les livres, les vidéos, les images, la musique et les données propriétaires.
Elle est conçue pour fournir un format standard lisible par machine permettant aux éditeurs, auteurs et développeurs d'applications de définir facilement les conditions de licence et d'utilisation afin que les utilisateurs et les robots puissent utiliser les ressources numériques pour la formation en IA, la recherche sur le Web et d'autres applications à l'aide d'accords de licence et de redevances standardisés, ainsi qu'un mécanisme permettant aux clients d'obtenir automatiquement une licence et de payer pour un accès légal aux ressources numériques.
Comment cela fonctionne-t-il ?
Au fond, la norme RSL est très simple et ne nécessite que deux composants, dont l'un est facultatif.
Le premier est un fichier de licence, défini en XML. Vous pouvez ensuite indiquer le fichier soit dans votre robots.txt
License: https://your-website.com/license.xmlSoit en tant qu'en-tête de réponse HTTP
Link: https://your-website.com/license.xml; rel="license";
type="application/rsl+xml"
Soit en l'intégrant ou en le liant à divers formats de fichiers.
Le fichier de licence vous donne ensuite un contrôle total sur la manière dont votre contenu est consommé. Cela peut être aussi simple que de demander une attribution via Creative Commons
<rsl xmlns="https://rslstandard.org/rsl">
<content url="/">
<license>
<payment type="attribution">
<standard>https://creativecommons.org/licenses/by/4.0/</standard>
</payment>
</license>
</content>
</rsl>
Ou vous pouvez autoriser les bots d'IA à s'entraîner gratuitement sur votre contenu
<rsl xmlns="https://rslstandard.org/rsl">
<content url="/">
<license>
<permits type="usage">ai</permits>
</license>
</content>
</rsl>
Ou, inversement, l'interdire
<prohibits type="usage">ai</prohibits>Ou si vous souhaitez facturer l'accès, c'est là que le deuxième composant optionnel entre en jeu et que les choses se compliquent quelque peu.
Montrez-moi l'argent
Autoriser ou refuser aux bots l'accès à votre contenu est une chose, mais que faire si vous souhaitez que votre contenu soit indexé, tout en étant rémunéré pour cela ? RSL vous offre la solution.
Vous avez trois options : abonnement, achat ou redevance, et vous bénéficiez d'une grande flexibilité dans la manière dont celles-ci sont négociées. Encore une fois, tout est géré à partir du fichier de licence.
Par exemple, vous pourriez exiger une souscription provenant d'un formulaire de contact sur votre site.
<license>
<permits type="usage">ai</permits>
<payment type="subscription">
<custom>https://your-website.com/contact-form.html</custom>
</payment>
</license>Ou vous pouvez indiquer au bot combien le contenu va lui coûter
<content url="/videos" server="https://example-server.org/api">
<license>
<payment type="purchase">
<amount currency="USD">10</amount>
</payment>
</license>
</content>Cela nécessite un serveur de licences. Ils peuvent être hébergés n'importe où ou fournis par le RSL Internet Collective. Les serveurs de licences permettent également d'obtenir une clé de décryptage pour toute personne disposant d'une licence.
<content url="https://example.com/books/example_book.epub.aes"
encrypted="true" server="https://example-server.org/api">
<license>
<permits type="usage">ai</permits>
<payment type="royalty">
<standard>https://rslcollective.org/license</standard>
</payment>
</license>
</content>Est-il déjà possible de l'intégrer à Fastly ?
Bien sûr !
Vous trouverez ci-dessous la procédure pour implémenter une version très simple en VCL, mais cela devrait être tout aussi facile à réaliser sur Compute en JavaScript, Go et Rust.
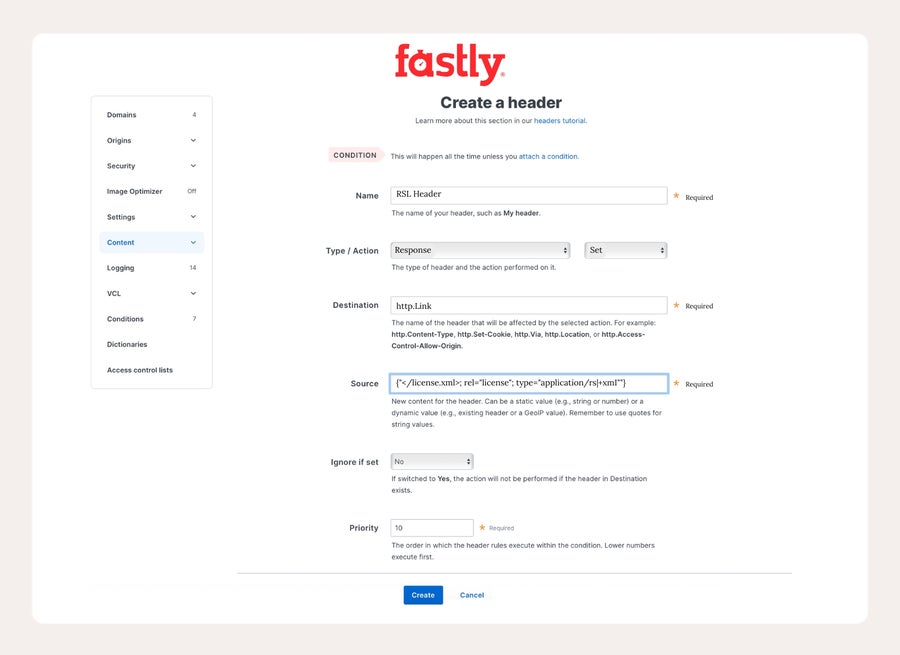
Tout d'abord, dans le menu Contenu, veuillez créer un nouvel en-tête de réponse qui fournit un lien vers votre fichier de licence.
Pas le {" "} autour de Source. Il s'agit de la syntaxe VCL permettant d'utiliser des guillemets dans les chaînes.
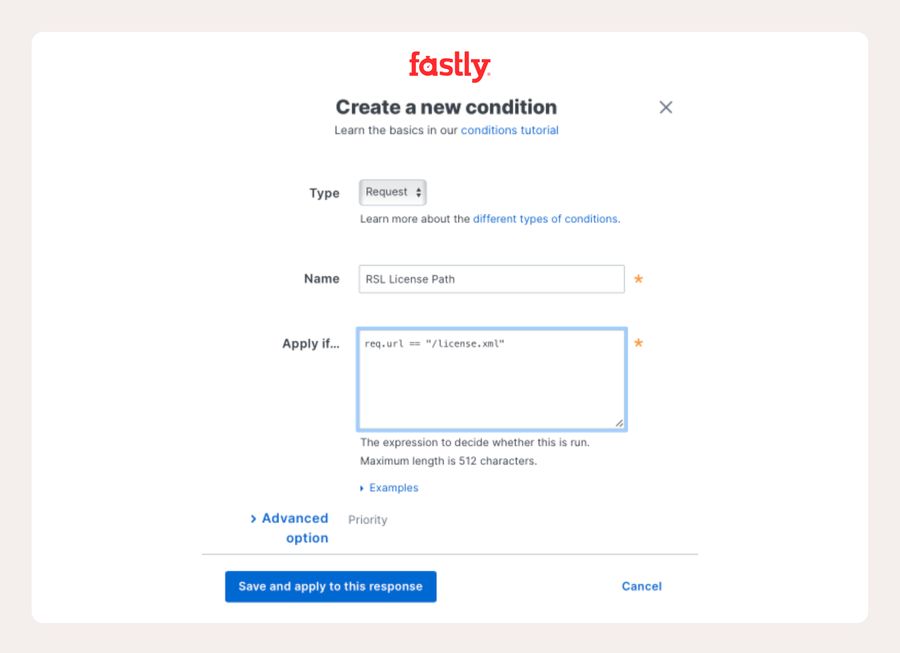
Ensuite, toujours dans Contenu, créez une réponse (vous devrez cliquer sur « Définir une réponse avancée »). Dans ce panneau, créez une condition qui vérifie si l'URL est license.xml.
Veuillez ensuite remplir le reste de la réponse avec la licence que vous souhaitez. Ici, j'ai choisi une licence d'attribution.
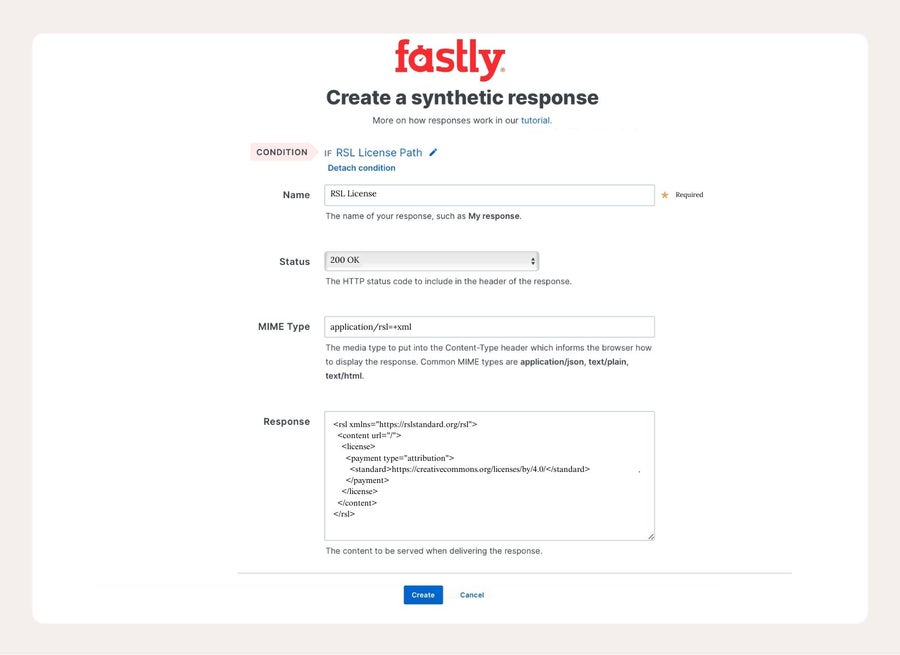
Et le tour est joué. Enregistrez cela et déployez votre service.
Pour approfondir
À l'avenir, nous allons renforcer l'intégration afin de faciliter encore davantage son utilisation. Cependant, nous souhaitons vous offrir la possibilité de l'essayer par vous-même.
Il convient de noter. Il existe diverses autres normes qui sont proposées à différents stades d'achèvement et d'ouverture. En général, nous préférons travailler avec un processus de normes ouvertes plutôt que de proposer des mécanismes similaires mais propriétaires, mais nous fournirons également de la documentation et des intégrations avec d'autres fournisseurs si ceux-ci s'avèrent populaires.
Pour en savoir plus sur la manière dont la rémunération s'intègre dans l'avenir des droits sur le contenu, consultez notre blog : Why Paying Copyright Holders for AI Training is Essential (Pourquoi il est essentiel de rémunérer les détenteurs de droits d'auteur pour l'entraînement de l'IA).