

Es ist unmöglich, die grundlegende Veränderung in der Art und Weise, wie Inhalte im Internet produziert und konsumiert werden, in den letzten Jahren übersehen zu haben. Unabhängig von Ihrer Meinung zu diesem Thema scheint KI ein allgegenwärtiges Gesprächsthema zu sein, mit KI-Maximalisten, AGI-Befürwortern und Enthusiasten auf der einen Seite und Skeptikern, Miesmachern und Weltuntergangspropheten auf der anderen Seite.
Die Wahrheit liegt wahrscheinlich irgendwo in der Mitte. Aber eines ist unbestreitbar: die Debatte über die Rolle von Scrapern und Crawlern und die Verwendung der von ihnen erfassten Daten.
Zunächst einmal gibt es das sehr legitime Problem der Urheberrechtsverletzung. Wie transformativ sind Large Language Models? Wie Pablo Picasso einmal scherzte: „Gute Künstler kopieren; großartige Künstler stehlen“, und es ist schwer zu leugnen, dass die Kunstgeschichte durch Neuerfindungen und Neuinterpretationen von Inspirationen der Vorfahren angetrieben wurde. Die Rückverfolgung der Abstammung einer Kunstform zeigt eine konstante Evolution über Generationen hinweg. Und wie viele junge Künstler haben im kleineren Maßstab angefangen, ihre Lieblingsbilder oder -comics zu kopieren? Wie viele Bands haben mit Coverversionen ihrer Lieblingslieder angefangen?
Und dennoch fühlt sich das hier immer noch anders an. Das Scrapen von Inhalten, um sie mechanisch und mathematisch zu einem Faksimile zusammenzufügen, wirkt nicht wie eine Hommage, sondern fühlt sich aus dem Bauch heraus eher wie Diebstahl an.
Gleichzeitig verhalten sich dieselben Crawler häufig unangemessen – sie ignorieren etablierte Standards wie robots.txt, unternehmen erhebliche Anstrengungen, um ihre IP-Adressen zu verbergen, und belasten Websites wiederholt[1, 2, 3]. Schlimmer noch, der Traffic ist teurer – Wikipedia berichtet, dass Bots zwar 35 % des gesamten Traffics ausmachen, aber 65 % aller Ressourcen beanspruchen.
Es fühlt sich ungleich und ungerecht an, und viele Menschen, selbst KI-Enthusiasten, sind der Meinung, dass etwas getan werden muss, um das Gleichgewicht wiederherzustellen.
Hier kommt der RSL-Standard (Really Simple Licensing) ins Spiel. Es handelt sich um „ein offenes, XML-basiertes Dokumentformat zur Definition maschinenlesbarer Lizenz- und Nutzungsbedingungen für digitale Assets wie Websites, Webseiten, Bücher, Videos, Bilder, Musik und proprietäre Daten“.
Es wurde entwickelt, um ein standardisiertes, maschinenlesbares Format bereitzustellen, mit dem Publisher, Autoren und Anwendungsentwickler auf einfache Weise Lizenz- und Nutzungsbedingungen definieren können, sodass Nutzer und Bots digitale Assets für KI-Schulung, Websuchen und andere Anwendungen unter Verwendung standardisierter Lizenz- und Lizenzgebührenvereinbarungen sowie eines Mechanismus nutzen können, mit dem Kunden automatisch Lizenzen erwerben und für den legalen Zugriff auf digitale Assets bezahlen können.
Wie funktioniert das?
Im Kern ist RSL sehr einfach und benötigt nur zwei Komponenten, von denen eine optional ist.
Die erste ist eine Lizenzdatei, die in XML definiert ist. Sie können dann in Ihrer robots.txt auf die Datei verweisen.
License: https://your-website.com/license.xmlOder als HTTP-Antwort-Header
Link: https://your-website.com/license.xml; rel="license";
type="application/rsl+xml"
Oder es kann in verschiedene Dateiformate eingebettet oder verlinkt werden.
Die Lizenzdatei gibt Ihnen dann die vollständige Kontrolle darüber, wie Ihre Inhalte konsumiert werden. Dies kann so einfach sein wie die Bitte um Namensnennung über Creative Commons.
<rsl xmlns="https://rslstandard.org/rsl">
<content url="/">
<license>
<payment type="attribution">
<standard>https://creativecommons.org/licenses/by/4.0/</standard>
</payment>
</license>
</content>
</rsl>
Oder Sie können KI-Bots kostenlos mit Ihren Inhalten trainieren lassen.
<rsl xmlns="https://rslstandard.org/rsl">
<content url="/">
<license>
<permits type="usage">ai</permits>
</license>
</content>
</rsl>
Oder, im Gegenteil, verbieten Sie es
<prohibits type="usage">ai</prohibits>Wenn Sie für den Zugang Gebühren erheben möchten, kommt die zweite, optionale Komponente ins Spiel, und die Angelegenheit wird etwas komplexer.
Zeigen Sie mir das Geld
Bots das Lesen Ihrer Inhalte zu erlauben oder zu verweigern ist eine Sache, aber was ist, wenn Sie möchten, dass Ihre Inhalte gecrawlt werden, jedoch auch dafür bezahlt werden möchten? RSL hat die Lösung für Sie.
Sie haben drei Möglichkeiten: Abonnement, Kauf oder Lizenzgebühren, und es gibt Flexibilität bei der Aushandlung dieser Optionen. Erneut wird alles über die Lizenzdatei abgewickelt.
Sie könnten beispielsweise ein Abonnement verlangen, das über ein Kontaktformular auf Ihrer Site erfolgt.
<license>
<permits type="usage">ai</permits>
<payment type="subscription">
<custom>https://your-website.com/contact-form.html</custom>
</payment>
</license>Oder Sie können dem Bot mitteilen, wie viel der Inhalt kosten wird.
<content url="/videos" server="https://example-server.org/api">
<license>
<payment type="purchase">
<amount currency="USD">10</amount>
</payment>
</license>
</content>Hierfür ist ein Lizenz-Server erforderlich. Diese können überall gehostet werden oder das RSL Internet Collective stellt einen zur Verfügung. Lizenzserver bieten Personen mit einer Lizenz zudem die Möglichkeit, einen Entschlüsselungscode zu erhalten.
<content url="https://example.com/books/example_book.epub.aes"
encrypted="true" server="https://example-server.org/api">
<license>
<permits type="usage">ai</permits>
<payment type="royalty">
<standard>https://rslcollective.org/license</standard>
</payment>
</license>
</content>Können Sie es schon mit Fastly integrieren?
Natürlich!
Nachfolgend erfahren Sie, wie Sie eine wirklich einfache Version in VCL implementieren. Es sollte jedoch genauso einfach sein, dies auf Compute in JavaScript, Go und Rust zu tun.
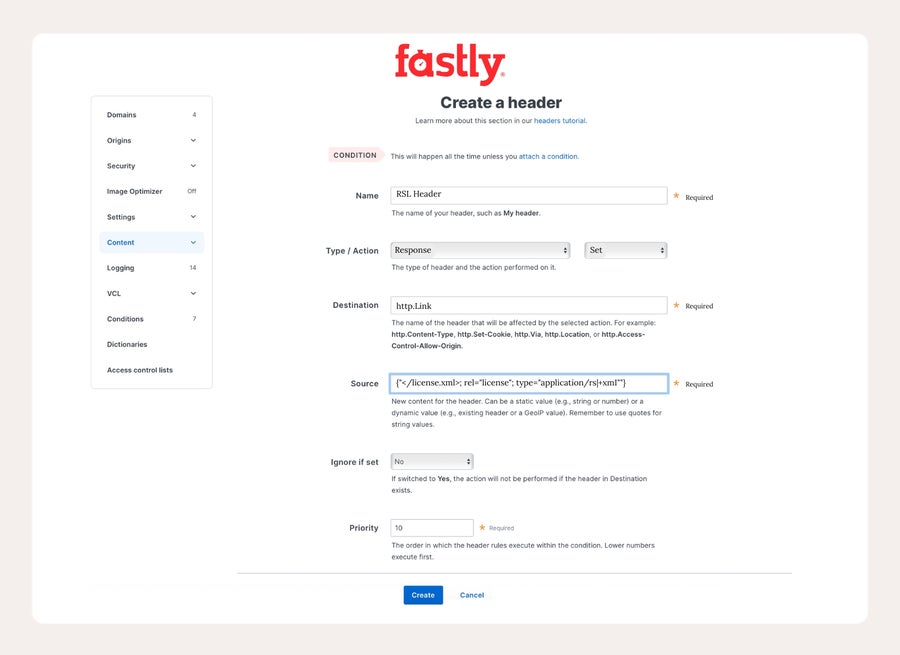
Erstellen Sie zunächst im Menü „Content“ einen neuen Antwort-Header, der einen Link zu Ihrer Lizenzdatei enthält.
Nicht die {" "} um die Quelle. Dies ist die VCL-Syntax, um wörtliche Anführungszeichen in Strings zuzulassen.
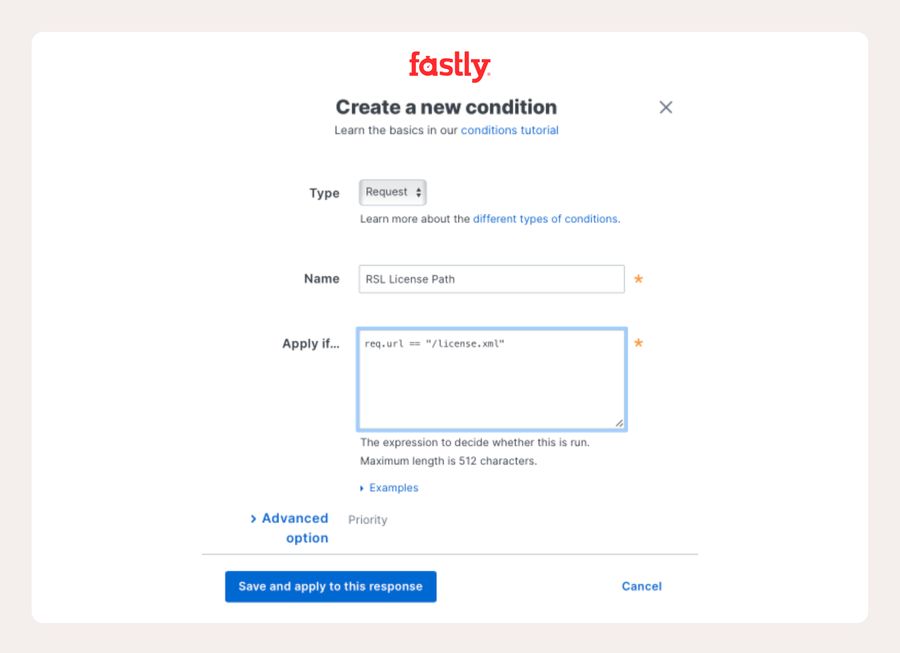
Erstellen Sie dann, weiterhin im Menü „Content“, eine Antwort (Sie müssen auf „Set up advanced response“ klicken). Erstellen Sie in diesem Panel eine Bedingung, die überprüft, ob die URL license.xml ist.
Füllen Sie dann den Rest der Antwort mit der gewünschten Lizenz aus. Hier habe ich eine Attribution-Lizenz gewählt.
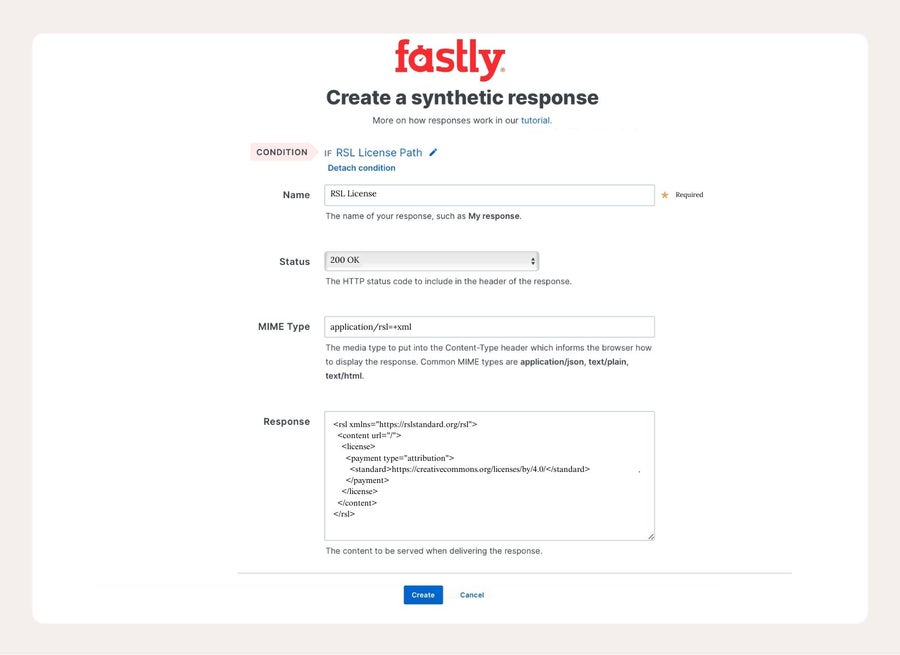
Und das war's. Speichern Sie das und stellen Sie Ihren Service bereit.
Was kommt als Nächstes?
In Zukunft werden wir eine noch engere Integration vornehmen, um es noch einfacher zu machen, aber in der Zwischenzeit wollten wir Ihnen die Möglichkeit geben, es selbst auszuprobieren.
Folgendes sollte beachtet werden. Es gibt verschiedene andere Standards, die in unterschiedlichen Stadien der Fertigstellung und Offenheit vorgeschlagen werden. Im Allgemeinen ziehen wir es vor, mit offenen Standards zu arbeiten, anstatt ähnliche, aber proprietäre Mechanismen vorzuschlagen, aber wir werden auch Dokumentation und Integrationen mit anderen Anbietern bereitstellen, wenn sie sich als beliebt erweisen.
Lesen Sie mehr darüber, wie die Vergütung in die Zukunft der Inhaltsrechte passt, in unserem Blog: Warum es unerlässlich ist, Urheberrechtsinhaber für das Training von KI zu bezahlen.