

Die Verarbeitung von KI-Workloads auf Fastly Compute ist nicht nur möglich, sondern auch äußerst effektiv, da die niedrige Latenz der Edge und die strikte Isolierung unserer Umgebung genutzt werden. In diesem Beitrag werden wir verschiedene Vorgehensweisen zur Erweiterung Ihrer Fastly Compute-Dienste um Agentenfunktionen mithilfe von LLM-APIs erläutern. Außerdem erklären wir, wie unsere Compute-Plattform, die Code in WebAssembly-Sandboxes ausführt, eine optimale Geschwindigkeit und Sicherheit auf Unternehmensniveau für Ihren Agenten gewährleistet.
Die Gestaltung von Feedbackschleifen für einen KI-Agenten
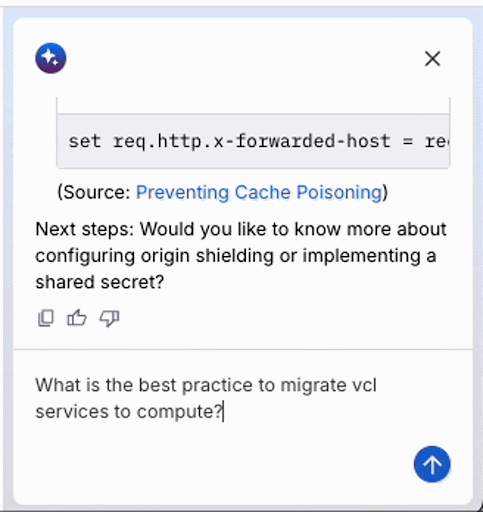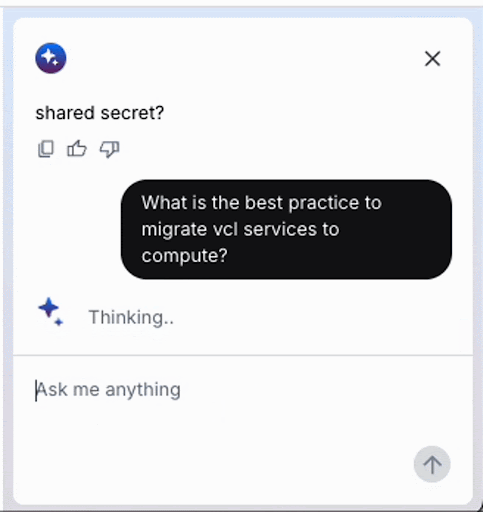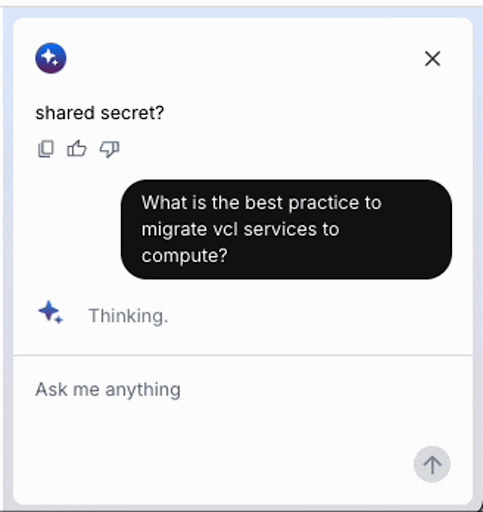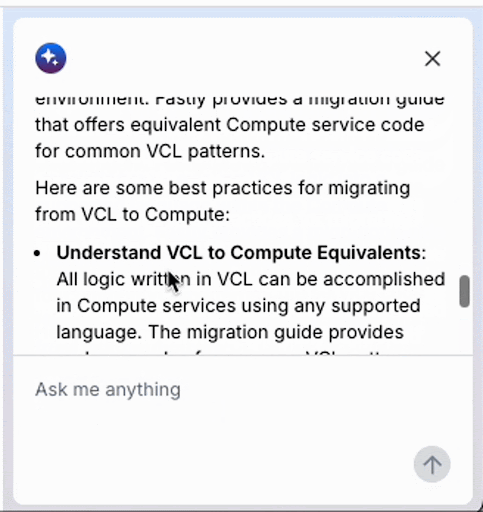
Dieses animierte GIF zeigt einen kürzlich gestarteten KI-Assistenten, der im Fastly Control Panel ausgeführt wird. Wenn Sie in einem KI-basierten Chat wie diesem eine Eingabe machen, sind Sie es wahrscheinlich gewohnt, zu warten, während der KI-Agent „denkt“. Anstatt die Testzeitberechnung (TTC) des Modells selbst zu verwenden, bei der das Modell „tiefer nachdenkt“, bevor es eine Antwort gibt, können Sie diesen Denkprozess implementieren, indem Sie einen Agenten erstellen, der die Ergebnisse von LLM-API Calls als Feedback nutzt, um ein Ziel zu erreichen. Diese Methode wird häufig als „Agent Loop“ bezeichnet. Dieser Prozess wiederholt kontinuierlich eine Abfolge von Schritten – wie Denken, Planen, Handeln mit Werkzeugen und Beobachten der Ergebnisse –, bis das Ziel erfolgreich erreicht ist.
Der Ablauf dieser Feedback-Schleife ist unten dargestellt. Es kommt häufig vor, dass ein einzelner Austausch, bei dem ein LLM sofort eine Antwort auf eine Eingabe generiert, nicht das gewünschte Ergebnis liefert. Dieser Mechanismus ermöglicht es dem Agenten jedoch, die Schritte (1) bis (3) selbstständig wiederholt auszuführen und zu bewerten, wodurch die Genauigkeit verbessert und das Endergebnis erzielt wird.
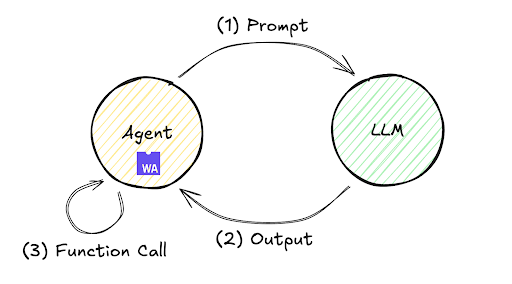
Diese Schleife kann in verschiedenen Umgebungen bereitgestellt werden, von der lokalen Infrastruktur bis hin zu Remote-Servern. Schauen wir uns den Verarbeitungsablauf in einer Remote-Umgebung mit Fastly Compute anhand einer minimalen Implementierung an. Das Fastly Compute JavaScript SDK ermöglicht beispielsweise diese Implementierung, wie unten gezeigt. Beachten Sie, dass dieser Code validiert werden kann, indem Sie ein TypeScript Starter Kit mit $npx fastly compute init initialisieren und src/index.ts durch den folgenden Code ersetzen.
addEventListener("fetch", (event) => event.respondWith(handleRequest(event)));
async function handleRequest(event: FetchEvent) {
let payload = {
model: 'gpt-5.2',
messages: [{role: "user", content: "what's the weather today?"}],
tools: [{ "type": "function", "function": {
"name": "get_weather",
"description": "retrieve weather forecast",
"parameters": {}}}]}
while(true){ // Agent loop begins
let res = await (await fetch("https://<LLM_API_ENDPOINT>/chat/completion", {
method: "POST",
headers: new Headers({
"Content-Type": "application/json",
"Authorization" : "Bearer <YOUR_ACCESS_TOKEN>",
}),
body: JSON.stringify(payload)
})).json();
if (res.choices[0].finish_reason != "tool_calls") {
return new Response(JSON.parse(res.choices[0].message.content))
}
if (res.choices[0].message.tool_calls != undefined) {
for (const toolCall of res.choices[0].message.tool_calls ) {
if (toolCall.type === "function") {
payload.messages.push({
role: "user",
content: "{\"weather\":\"windy and rainy\"}" // pseudo result
});
}
}
}
}
}Die Ausführung dieses Codes folgt diesem übergeordneten Ablauf:
Senden Sie die Anfrage „Wie ist das Wetter heute?“ an die LLM-API.
Die LLM-API gibt eine Anweisung zur Ausführung des Tools
get_weatherzurück.Fügen Sie einen Platzhalterwert
„windig und regnerisch“als vorläufiges Ergebnis der Eingabe hinzu und rufen Sie die LLM-API (Agent Loop) erneut auf.Empfangen Sie ein Abschlusssignal von der LLM-API (d. h. Stopp wird als
finish_reasonzurückgegeben) und zeigen Sie das Endergebnis an.
Die Ausführung dieses Programms in meiner Laborumgebung unter Verwendung des gpt-5.2-Modells ergab für Schritt 4 folgendes Ergebnis:
„Heute ist es windig und regnerisch. Wenn Sie Rausgehen, nehmen Sie eine wasserdichte Jacke und einen Regenschirm mit, und achten Sie auf glatte Straßen und starke Böen. Möchten Sie eine stündliche Aufschlüsselung oder Tipps zum Pendeln oder für Pläne im Freien?“
Das Ergebnis dieses iterativen Agent Loop veranschaulicht die zuvor besprochene Feedback-Schleife – eine Verarbeitungstechnik, die häufig hinter der Anzeige „Denke nach …“ in modernen Chat-Oberflächen zum Einsatz kommt.
Die sich ständig weiterentwickelnde Agenten-Schleife
Agent Loops ziehen schon seit einiger Zeit Aufmerksamkeit auf sich, aber in diesem Jahr haben die Schnittstellen zu externen Tools wie MCP (z. B. Fastly MCP Server) und Tool-Calls sie verstärkt. Diese Entwicklung ist im folgenden Diagramm vereinfacht dargestellt.
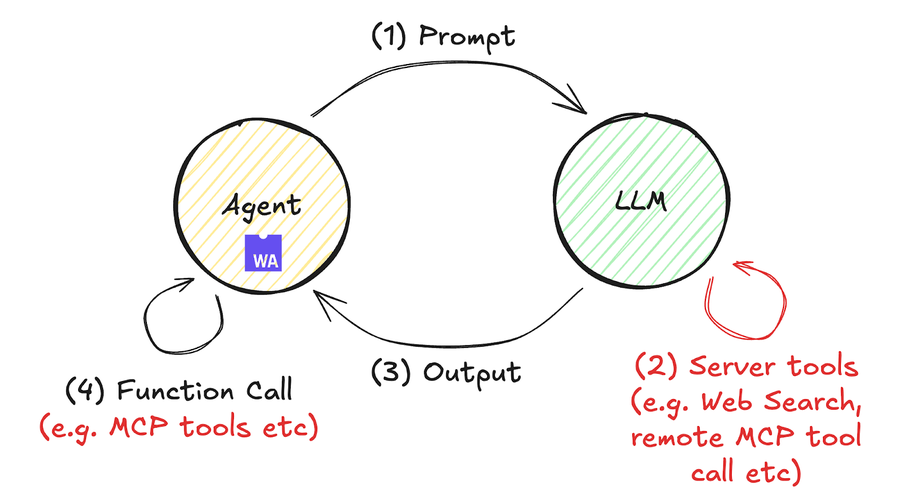
Ein konkretes Beispiel für die Verarbeitung von Compute-Code, der auch Remote-Tool-Aufrufe umfasst, finden Sie hier. In diesem Beispiel verwenden wir die Antwort- API von OpenAI (angekündigt im Mai) als Beispiel, die Remote-Tool-Aufrufe ermöglicht, obwohl ähnliche Operationen auch mit der Messages-API von Anthropic und anderen möglich sind. Sie können diesen Code ausführen, indem Sie die folgenden Schritte befolgen. In etwa 60 Zeilen JavaScript-Code fassen wir Best Practices zur Migration von Fastly VCL-Services zu Compute basierend auf Dokumentensuchergebnissen zusammen und geben letztlich eine editierbare PowerPoint-Datei (keine PDF-Datei) aus.
$ mkdir compute-agent-demo && cd compute-agent-demo
$ npx fastly compute init -l javascript -i
$ npm install pptxgenjs openai hono @fastly/hono-fastly-compute abortcontroller-polyfill
$ curl -s "https://gist.githubusercontent.com/remore/25a1638a3a2183daa609044cfa1ce6f9/raw/818322d634d59c10950878932517c4173b746dd3/index.js" > src/index.js
$ vi src/index.js # Put your API Token and rmeote MCP server address
$ fastly compute serveEin Beispiel für die tatsächliche Ausgabe der PowerPoint-Datei sieht wie folgt aus. Durch die Nutzung der Fähigkeit des LLM, Informationen zusammenzufassen und Code zu generieren, können wir nun eine editierbare PowerPoint-Binärdatei (.pptx) mit überzeugenden Inhalten erstellen, die das Ziel erfüllen.

Ein großer Unterschied zwischen diesem Codebeispiel und dem vorherigen ist, dass das Programm keine 2while ()-Anweisung enthält. Da die KI-Schleife des Agenten diesmal auf der LLM-API-Seite ausgeführt wird, implementiert der Compute-Code (der als Agent fungiert) keinen „while()“-Loop. Dies verbessert die Programmlesbarkeit und zeigt, wie jüngste Fortschritte eine Umgebung geschaffen haben, in der KI-Workflows deutlich leichter implementierbar sind.
const bestPractices = await callLLM(
'What are the best practices to migrate a fastly vcl service to compute? Outline ten practices and give each a summary of at least 300 characters.',
[{
"type": "mcp",
"server_label": "fastly-doc-search",
"server_url": "https://xxxxxxx.edgecompute.app/mcp",
"require_approval": "never",
}]
)Als Randbemerkung: Wir haben diese Demo implementiert, indem wir einen Remote-MCP-Server integriert haben, der auf Compute unter der Domain edgecompute.app läuft, wenn die Funktion callLLM() aufgerufen wird, wie im obigen Code gezeigt. Obwohl jeder entfernte MCP-Server kompatibel ist, habe ich einen auf Fastly Compute implementierten MCP-Server verwendet, um die Vorteile der Edge-Serverless-Plattform zu nutzen, die immer von dem Rechenzentrum aufgerufen wird, das der LLM-API am nächsten ist. Dies minimiert die Latenzzeit für Tool-Aufrufe und trägt zur Optimierung der Time to First Token (TTFT) bei. Die Funktionen von Fastly Compute, einschließlich der Edge-Ausführung mit niedriger Latenz und der Unterstützung von Streaming-Antworten, bieten eine leistungsstarke Unterstützung für Ihre KI-Agentenentwicklung. Einzelheiten zur Implementierung eines MCP-Servers mit Compute finden Sie in meinem vorherigen Blogbeitrag.
Wie die Plattform und das Wasm-Sandboxing von Fastly Ihre KI-Workloads schützen
Zum Schluss noch ein Wort zur Sicherheit, die der Schlüssel zu vertrauenswürdiger KI ist. Die Frage, welche Berechtigungen KI-Agenten erhalten sollen und wie diese verwaltet werden sollen, stellt Entwickler vor große Herausforderungen. Während sich die Diskussionen häufig auf die Entwicklung von permissiven Modellen zur Beschleunigung der Entwicklung bei der Verwendung von Codierungsagenten wie Claude Code, Gemini CLI und Codex konzentrieren, erfordert die Gestaltung von KI-Workflows in Unternehmen eine Perspektive auf restriktive Berechtigungsmodelle.
Durch die Nutzung von Fastly Compute profitieren Programme leicht von WebAssembly-Laufzeit-Sandbox-Isolation und Speichersicherheitsfunktionen wie linearer Speichergrenzenkontrolle innerhalb klarer Sicherheitsgrenzen. Beispielsweise wird die dynamische Codeausführung mit dem AsyncFunction() -Konstruktor, wie sie im obigen Beispiel implementiert ist, in vielen JavaScript-Laufzeiten allgemein als Schwachstellenrisiko und Anti-Pattern betrachtet. Obwohl auch bei Fastly Compute eine sorgfältige Nutzung erforderlich ist, läuft die Plattform in einer isolierten WebAssembly-Umgebung, die von Natur aus keinen Dateisystemzugriff, keine Netzwerk-E/A und keine Funktionen zur Ausführung externer Befehle bietet. Dadurch kann der Agent autonome Verarbeitungsprozesse mit einer minimierten Angriffsfläche durchführen.
Und das ist noch nicht alles – die umfangreichen Hostcalls der Fastly Compute-Plattform beinhalten auch diverse Sicherheitsaspekte. Beispielsweise trägt die Begrenzung der Anzahl von Backend-Fetch-/Send-Aufrufen dazu bei, die Ausgabe übermäßiger externer Anfragen zu verhindern. Darüber hinaus kann unser Mechanismus „Statisches Backend “ den Traffic auf vordefinierte externe Server beschränken und so verhindern, dass der Agent HTTP-Anfragen an unerwünschte/unbekannte externe Server sendet.
// example of dynamic backend
fetch("https://example.com/some-path")
// example of static backend, restricting traffic to pre-defined external servers
fetch("https://example.com/some-path", {backend: "example-com"})Dieser Mechanismus schützt nicht nur den KI-Workflow vor böswilliger Ausführung, sondern ermöglicht auch die selektive Autorisierung eines breiteren Verhaltens über eine Funktion namens „Dynamische Backends“. Durch die Möglichkeit einer granularen Fähigkeitszuweisung an Programme, die als Wasm-Module innerhalb einer sicheren Infrastruktur laufen, erleichtert Fastly Compute die nahtlose Implementierung von Sicherheit in KI-Workflows.
Sicherung der Kontrolle durch Nutzung standardisierter Technologien und Spezifikationen
In diesem Post haben wir mehrere Methoden zur effektiven Implementierung von KI-Agenten auf Fastly Compute vorgestellt. KI-Agenten sind unverzichtbar geworden, um signifikante Verbesserungen in der Produktivität und betrieblichen Effizienz zu erzielen. Durch die Nutzung von Fastly Compute – einer Umgebung auf Unternehmensniveau, die Performance und Sicherheit in Einklang bringt – können Sie Agenten entwickeln, die das Potenzial von KI voll ausschöpfen. Ich hoffe, dieser Post hilft Ihnen bei der Entwicklung von KI-Agenten mit einer besseren Benutzererfahrung. Beteiligen Sie sich an der Diskussion in unserem Forum und teilen Sie uns mit, was Sie entwickeln.