

En 2020, une idée émergea : pourrait-on rendre le nettoyage des requêtes Varnish plus intelligent en n’effaçant que la mémoire réellement utilisée, au lieu d’effacer systématiquement tout un bloc ? Théoriquement parlant, en ayant moins d’écritures en mémoire, il y aurait aussi moins de cycles perdus, et à l’échelle de Fastly, cela se traduirait par d’importants gains de performance.
Mais il y avait un problème. En effet, si la comptabilité était incorrecte, même légèrement, alors des données d’une requête à une autre pourraient être divulguées. C’est un risque qu’aucun développeur ne veut prendre. L’idée est donc restée en sommeil jusqu’à ce que nous ayons un moyen de prouver qu’elle était sûre. Cet article s’intéresse à la façon dont nous avons procédé.
Une méthode des temps anciens : toujours effacer 512 Ko
Chaque requête entrante dans Varnish reçoit un espace de travail de 512 Ko, réparti sur deux régions de 256 Ko (une pour gérer la requête entrante dans Varnish et une pour toute requête en back-end vers l’origine). Il s’agit avant tout d’un bloc-notes pour les données temporaires par requête. À la fin de la requête, Varnish efface toute la région, quelle que soit la quantité utilisée.
C’était une méthode simple et sûre, mais chère. Et pour cause : qu’une requête utilise 10 Ko ou 500 Ko, Varnish mettait toujours à zéro un demi-mégaoctet. À notre niveau de trafic, cela impliquait une montagne d’opérations de mémoire inutiles.
L’idée inexploitée : effacer le niveau d’utilisation le plus élevé
L’optimisation consistait à suivre le niveau d’utilisation le plus élevé, qui est le point le plus éloigné de l’espace de travail touché lors d’une requête.
Ainsi, si la requête n’utilisait que 20 Ko, nous effacerions uniquement 20 Ko, et pas 512 Ko. Mais si le suivi était désactivé, des octets non effacés pourraient persister, pouvant conduire à une fuite de données.
La découverte : se concentrer sur le véritable goulot d’étranglement
Lors d’un récent sommet sur l’efficacité, l’un de nos ingénieurs de l’équipe H2O a construit un modèle de performances pour l’ensemble du système. Les résultats ont montré que sur certaines machines de mesure, le trafic mémoire était le véritable goulot d’étranglement, et non les cycles du processeur. L’équilibre s’en est trouvé modifié : soudainement, effacer le niveau d’utilisation le plus élevé n’était plus seulement une bonne idée, mais un objectif qui méritait d’être poursuivi. Le défi consistait à garantir sa sécurité.
Garantir la sécurité
La partie la plus difficile n’était pas d’écrire le code, mais de prouver que le filigrane était toujours exact. Si nous nous fiions simplement au suivi, un octet manquant pourrait entraîner une fuite de données entre les requêtes, mais vérifier chaque requête aurait empêché les gains de performance.
L’avancée a été d’utiliser quelque chose que nous avions déjà : des contrôles d’intégrité de l’espace de travail qui s’exécutent après la plupart des opérations. En les exploitant et en ajoutant un échantillonnage aléatoire, nous pourrions valider l’exactitude sans générer de frais généraux constants ou augmenter inutilement le trafic mémoire Varnish. Le raisonnement était simple : une seule machine échantillonnant 1 opération sur 20 000 ne détecterait pas grand-chose, mais sur des milliers de machines, cela représenterait plus d’un million de contrôles par seconde. Un chiffre suffisant pour obtenir la confiance à grande échelle.
Nous avons déployé la suppression des filigranes en mode caché :
Toujours tout effacer : chaque requête continuait d’effacer la totalité des 512 Ko.
Continuer à suivre l’utilisation : chaque requête a également suivi son niveau d’utilisation le plus élevé, comme si l’optimisation était active.
Contrôler les échantillons : environ 1 opération sur 20 000 dans l’espace de travail a fait l’objet d’un audit. Tous les éléments qui se trouvaient au-delà du filigrane ont été relus pour confirmer qu’ils n’avaient pas été utilisés.
Pour maintenir les frais généraux bas :
Nous avons réutilisé les contrôles d’intégrité de l’espace de travail existant.
Nous avons structuré la boucle de vérification pour la vectorisation SIMD, en laissant le processeur traiter plusieurs octets par instruction.
Nous avons examiné le code machine généré pour confirmer que le compilateur avait émis des instructions vectorisées, et non une boucle scalaire lente.
Après avoir effectué cette opération sur l’ensemble de la flotte, nous avions la confiance statistique nécessaire pour nous fier au suivi des filigranes. Ce n’est qu’à ce moment que nous avons réellement activé l’optimisation.
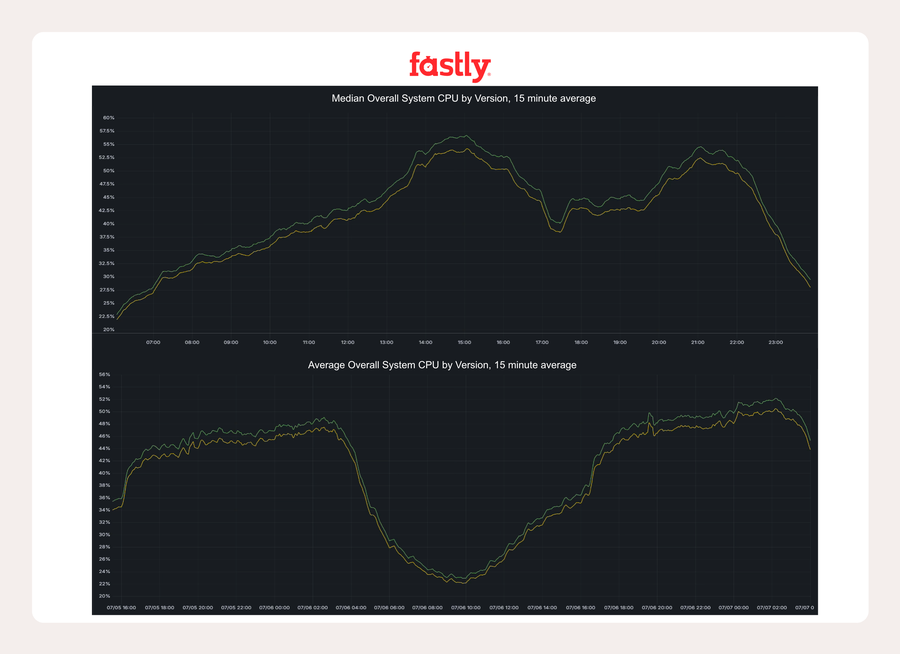
Déploiement et résultats
Nous avons suivi notre déploiement habituel conservateur et axé sur la sécurité, en commençant par un élément test sur plusieurs hôtes de production avant de l’étendre à l’ensemble de la flotte. Les résultats étaient significatifs :
À Marseille, les hébergeurs utilisant le mode filigrane écrivaient environ 10 Go/s de moins sur la mémoire, soit une réduction de 25 % des écritures mémoire par rapport à un effacement complet. Sur les machines de mesure, cela a suffi à éliminer la bande passante mémoire comme goulot d’étranglement, permettant ainsi des gains d’efficacité à tous les niveaux.
Dans un point of presence européen très fréquenté, l’utilisation du processeur système a chuté de plus de 2 points de pourcentage au moment le plus intense.
Sur le point KCGS720, qui fait partie des points of presence métropolitains critiques IAD, la réduction était d’environ 1,5 point de pourcentage.
Sur les machines Intel, nous n'étions pas limités par la bande passante mémoire, donc l'utilisation globale du système n'a pas beaucoup changé, mais les métriques spécifiques à Varnish se sont tout de même améliorées.
Les répercussions ont été saisissantes : en réduisant le trafic mémoire de Varnish, les instructions par cycle (IPC) de H2O se sont améliorées, malgré l’absence de modification de H2O. Lorsque vous libérez la bande passante mémoire, vous donnez aux autres processus plus d’espace pour respirer.
Leçons pour les développeurs
La sécurité avant tout : une optimisation qui risque de provoquer des fuites de données est plus qu’inutile.
Faites preuve de patience à grande échelle : l’échantillonnage de millions d’opérations par seconde nous a permis d’avoir confiance, et non de faire des suppositions.
Mesurez les bons éléments : c’est la bande passante de la mémoire, et non le processeur, qui a été le véritable facteur limitant.
Créez sur ce que vous avez : réutiliser les contrôles d’intégrité réduit la complexité.
Optimisez l’optimisation : les contrôles vectorisés ont rendu la sécurité abordable.
Attendez-vous à des effets à l’échelle du système : la correction d’un goulot d’étranglement peut être un avantage pour un code distinct.
Revenez sur l’ancien code : les idées mises de côté il y a des années peuvent être viables grâce à de nouvelles informations.
Prêtez attention aux interfaces : une grande partie de la complexité du débogage résidait aux jonctions entre les systèmes.
Pour les développeurs, la leçon à retenir est la suivante : ne vous contentez pas de courir après les chiffres évidents du processeur. Identifiez où se trouvent les goulets d’étranglement de votre système, prouvez la sécurité à grande échelle et réalisez des gains d’efficacité sans sacrifier l’exactitude.
Faites gagner à votre code rapidité et légèreté, sans compromettre la sécurité. Lancez-vous dès aujourd’hui en optant pour un compte développeur Fastly gratuit.