

Chez Fastly, nous aimons dire « Le cache est roi » (d'abord parce que c'est vrai, et ensuite parce que nous sommes tous de grands adeptes de l'efficacité !) Nous aimons l'efficacité du cache. Une mise en cache efficace peut apporter d’énormes améliorations en termes de performance, de sécurité, de résilience, d’économies de coûts… la liste est longue. Moins vos serveurs d'origine ont besoin d'être contactés, mieux c'est. Et cela compte beaucoup pour les utilisateurs qui visitent votre site web ou votre application — cela doit être instantané, rapide et efficace — ce qui signifie que la gestion de la charge de vos serveurs est une priorité.
Qu’est-ce que la réduction des demandes ?
L'un des « superpouvoirs » de notre plateforme, qui contribue à l'efficacité, est la réduction des demandes, une pratique consistant à combiner plusieurs requêtes concurrentes pour le même objet en une seule requête vers l'origine, puis à utiliser la réponse obtenue pour satisfaire toutes les requêtes en attente. Pour mieux comprendre ce que cela accomplit, examinons de plus près une réponse en cache Basic :

Simple et efficace, n'est-ce pas ? Mais chaque étape de ce processus devra prendre du temps, alors examinons cela de plus près :

Jusqu'à présent, tout va bien ! Mais que se passe-t-il lorsqu’un grand nombre d’utilisateurs veulent tous la même chose en même temps, mais que nous n’avons pas pu la récupérer depuis votre origine ? Cela se produit tout le temps lors des flux vidéo en direct ou des nouvelles versions de jeux. C’est là que la réduction des demandes se produit. L'architecture et la plateforme de mise en cache de Fastly nous permettent d'utiliser la même réponse d'origine pour servir les requêtes arrivées après le début de leur récupération. Cela signifie que toutes ces requêtes reçoivent la réponse la plus récente possible, sans aucune récupération supplémentaire depuis l'origine. Les utilisateurs reçoivent du contenu frais (et bénéficient d'une bonne expérience), votre origine est protégée et, surtout, c'est très efficace.
Quand la réduction des demandes peut-elle se produire ?
Dans notre exemple précédent, nous avons observé à quel point la réduction des demandes constitue un puissant sous-ensemble du comportement de mise en cache de Fastly. Il est toujours activé par défaut, et il n’y a rien de spécial que vous ayez à faire pour en Advantage. Cela dit, il s'agit d'un comportement situationnel nécessitant que certaines choses se produisent dans des délais très courts, et tous les flux de travail des clients ne peuvent pas en tirer avantage.
Tout d'abord, les requêtes doivent être interactives avec le cache, c'est-à-dire qu'elles produiront un objet de cache que les requêtes suivantes pourront utiliser. Les requêtes PASS et de nombreuses erreurs ne peuvent pas être mises en cache par défaut, ce qui signifie que nous ne serons jamais en mesure de regrouper ces requêtes. Si nous ne pouvons pas le mettre en cache, nous ne pourrons pas réduire les requêtes sur la réponse.
Deuxièmement, pour que les requêtes soient regroupées, elles doivent être concurrentes avec la requête qui a initié la récupération depuis l'origine. Cela signifie que nous recevons la requête alors que nous sommes déjà en train de la récupérer pour satisfaire une requête antérieure. Une fois que cette réponse est complétée, le comportement normal de la mise en cache prend le relais et l'effondrement s'arrête. Cela se produit le plus souvent sur les objets du cache qui changent fréquemment et qui sont très sollicités, de sorte que de nombreux utilisateurs les demandent en même temps et nous devons les récupérer fréquemment depuis l'origine.
La simultanéité sera augmentée par des fonctionnalités telles que le groupe et la protection. Tous deux concentrent les requêtes au sein de notre plateforme afin d'améliorer l'efficacité et les performances. "Vous pourriez également observer une fréquence accrue de réduction des demandes lorsqu'une origine met plus de temps à répondre, soit parce que l'objet est plus volumineux, soit parce que l'origine est surchargée." Comme la période d'attente de la réponse est plus longue, il y a plus de temps pour le regroupement des requêtes.
De manière quelque peu contre-intuitive, des origines plus rapides et des fonctionnalités qui améliorent le temps de chargement du premier octet réduiront la fréquence à laquelle nous pouvons regrouper les requêtes. Comme expliqué ci-dessus, nous ne regrouperons les requêtes que lorsque nous attendrons la réponse de l'origine. Une fois que la réponse est prête à être utilisée, nous arrêtons de regrouper les requêtes. L'activation de la fonctionnalité de streaming manqué peut réduire considérablement cette fenêtre, car elle nous permet de commencer à utiliser l'objet du cache dès que nous recevons les en-têtes de la réponse d'origine.
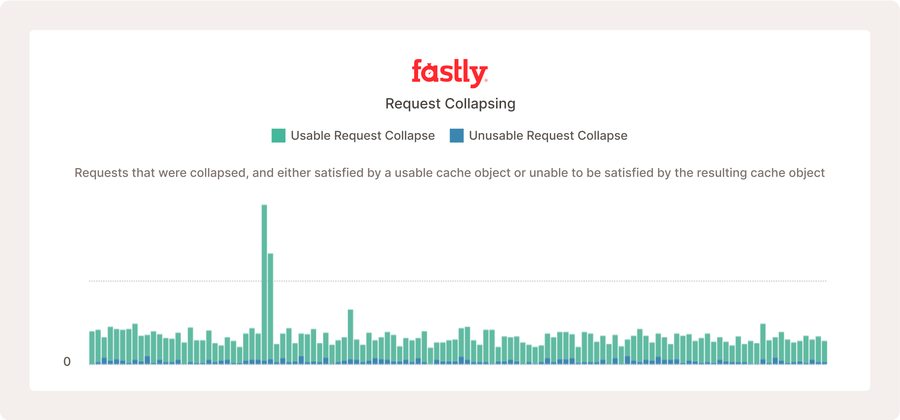
L'image ci-dessus montre une partie du tableau de bord Media Shield pour un service de vidéo en direct populaire. La réduction des demandes se produit, mais comme l'origine est rapide et que la configuration est si efficace, cela ne se produit pas très souvent par rapport au nombre de requêtes qu'elle reçoit.
Métriques de réduction des demandes
Maintenant que nous avons une meilleure compréhension de ce qu’est la réduction des demandes et de ce qu’elle fait, explorons les métriques que vous voudrez surveiller de près. Ces métriques vous aideront à comprendre si cela fonctionne (ou pas !) et à quel point c'est efficace.
Nous avons introduit deux métriques qui sont disponibles à la fois en temps réel et dans les statistiques historiques :
request_collapse_usable_countrequest_collapse_unusable_countNos clients peuvent trouver ces métriques via nos API ou vous pouvez utiliser un panneau personnalisé pour les visualiser dans nos tableaux de bord d’observabilité et Media Shield. Pour entrer dans les détails :
Usable_count: compte la fréquence à laquelle nous avons réduit les requêtes et trouvé un objet de cache utilisable. Pour être utilisable, l'objet doit être mise en cache possible et avoir une durée de vie de cache positive. La durée de vie du cache est le Temps de vie (TTL) de l'objet moins son âge (combien de temps nous l'avons eu en cache). Une fois que la durée de vie d'un objet dans le cache n'est plus positive, il expire et n'est plus valide pour aucune Utilisation du cache, sauf pour livrer des données obsolètes. La mise en cache est également régie par la variable mise en cache possible et est documentée ailleurs.
Unusable_count : est l'opposé de ce qui précède — usable_count. Lorsqu'une réponse est inutilisable, nous devons essayer de la récupérer à nouveau depuis l'origine. En général, c'est mauvais et cela peut signifier qu'il y a un problème de configuration soit avec votre origine, soit avec votre service, ou que vous avez un flux de travail non cachable qui n'est pas transmis. (L'addition de ces deux éléments vous indique la fréquence à laquelle les requêtes sont regroupées !)
Comprendre les métriques de réduction des demandes
On y est presque ! Nous disposons de tableaux de bord pour analyser le comportement de votre trafic sur notre plateforme, et vous savez ce qu'il faut surveiller – mais il y a aussi de nombreux nouveaux chiffres à gérer… qu'est-ce qui est pertinent ? Qu’est-ce qui ne va pas ?
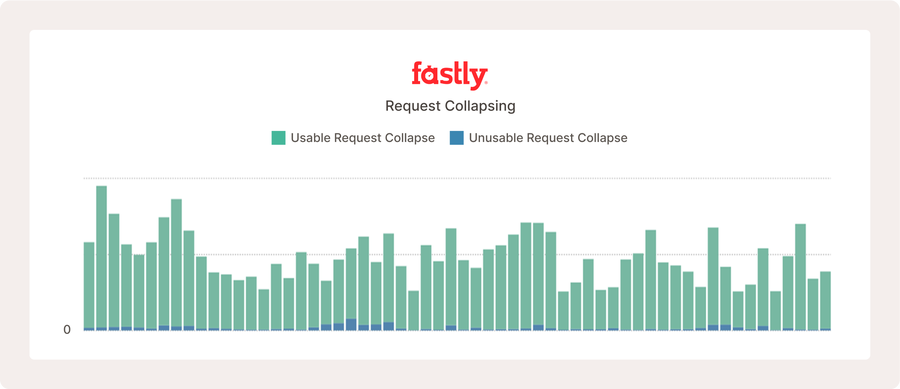
Les informations ci-dessus présentent les métriques de réduction des demandes pour un projet open source très actif, où de nombreux utilisateurs consultent régulièrement le nouveau contenu, ce qui augmente la fréquence de réduction des demandes.
Pour comprendre ce qui fonctionne et ce qui ne fonctionne pas, vous devez d’abord avoir une connaissance fondamentale des schémas de trafic de vos utilisateurs. Il est peu probable que la réduction des demandes se produise si vos requêtes sont réparties sur un grand nombre d'URL qui ne changent pas très souvent. Il est important de se rappeler que la majorité de la réduction des demandes se produit pour des requêtes arrivant dans le même intervalle de 25 à 150 ms. C'est une très petite fenêtre temporelle. Certains flux de travail sont beaucoup plus susceptibles de bénéficier de la réduction des demandes. "Les sites d'actualités, les flux vidéo en direct et les téléchargements de fichiers populaires sont susceptibles de constater que la réduction des demandes se produit beaucoup plus souvent." Tout dépend du nombre d’utilisateurs qui requêtent le même objet en même temps.
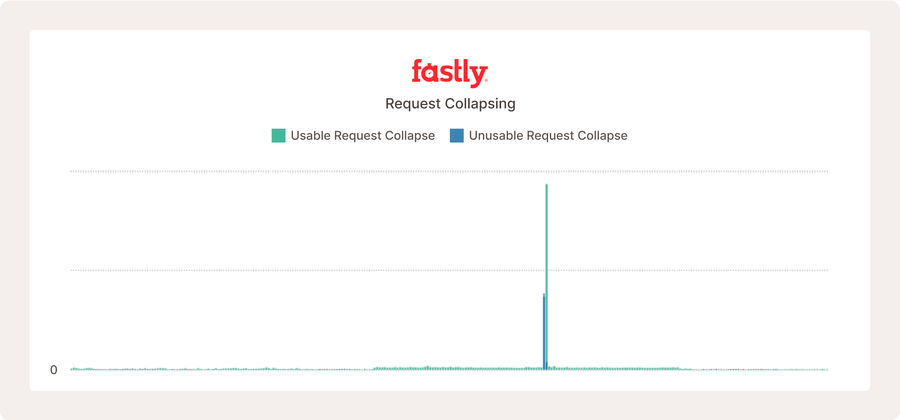
"Dans l'exemple ci-dessus d'un site web réel, la réduction des demandes ne se produit pas souvent avant qu'il y ait un pic soudain de trafic pour les mêmes objets de cache."
Il est important de souligner que la réduction des demandes, qu'elle soit plus ou moins importante, n'est ni bonne ni mauvaise. Il ne s'agit pas d'une métrique dont vous devez vous préoccuper d'augmenter ou de diminuer, à une exception près (nous y reviendrons dans un instant !). Cela montre à quelle fréquence nous servons des utilisateurs directement depuis votre origine en même temps. Une bonne règle de base consiste à considérer l'importance de ces chiffres par rapport à vos volumes globaux de requêtes. Il est tout à fait normal qu'il y ait de petites quantités de réduction des demandes avec un résultat inutilisable. Cela est dû au fait que de nombreuses erreurs de back-end ne sont pas mise en cache possible, et que, parfois, le comportement de l'utilisateur peut nous amener à faire une requête un objet au moment précis où il a expiré. C'est tout à fait attendu.
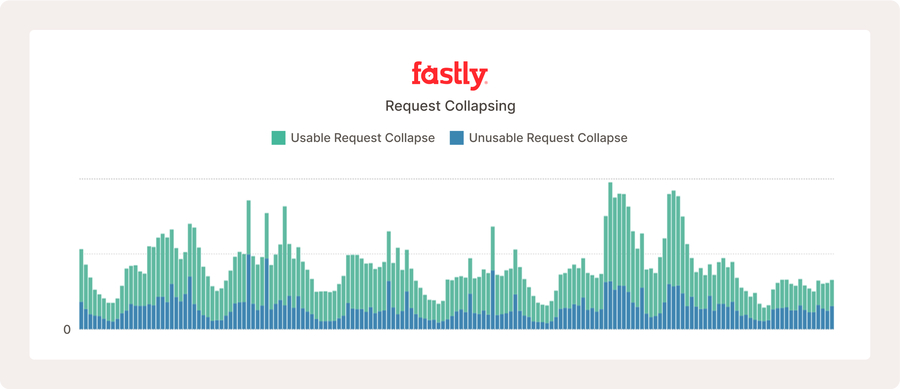
De nombreuses réponses inutilisables peuvent sembler problématiques, comme indiqué ci-dessus. Cependant, ce site web reçoit plus de dix millions de requêtes par heure, et ce que nous observons est un comportement internet normal dû à des réponses d'erreur légitimes, qui ne peuvent pas être mises en cache.
Pour revenir à la mise en garde que j'ai mentionnée, une chose dont vous devez être très conscient (et contactez votre représentant Fastly si vous le voyez se produire) est si vous avez des volumes élevés de comptes inutilisables par rapport à vos volumes de requêtes. Ceci est un indicateur potentiel de sérialisation des requêtes. Nous en discuterons plus en détail dans un futur blog, mais brièvement, la sérialisation des requêtes signifie que Fastly essaie de récupérer un objet pour satisfaire plusieurs requêtes simultanément, mais la réponse ne parvient pas à créer un objet de cache valide. Lorsque cela se produit, la requête initiale obtient l'objet inutilisable, et la requête suivante réessaie. Si cela continue, nous ne répondrons plus qu'à une seule requête à la fois, encore et encore. Cela est très inefficace et peut avoir un impact réel sur les utilisateurs.
Un autre problème avec ces métriques est qu’elles ne peuvent pas indiquer si les requêtes s’effondrent sur quelques objets très populaires ou sur un grand nombre d’objets modérément populaires. Ceci est important car de grands volumes d’objets inutilisables répartis peuvent être tout à fait normaux pour votre flux de travail. La réduction des demandes peut être un sujet compliqué, mais si vous êtes arrivé jusqu’ici, nous espérons que vous l’avez trouvé informatif dans votre parcours d’efficacité. Nous prévoyons de couvrir ce sujet plus en détail dans de futurs articles de blog. Restez à l'affût !