

GraphQL es un lenguaje de consultas de código abierto que puede utilizarse como alternativa a REST. Los desarrolladores lo están incorporando de forma rápida para lograr la flexibilidad necesaria para mantener altos niveles de modernidad y crecimiento en las API. Este lenguaje de consultas permite a los clientes preguntar qué es exactamente lo que necesitan; así, se simplifica la evolución de las API a lo largo del tiempo.
Las ventajas son más que evidentes. Sin embargo, hay ciertos aspectos sobre seguridad que no suelen entenderse del todo bien. ¿Pueden los atacantes hacer un uso indebido de alguna funcionalidad? ¿Y aprovecharse de alguna vulnerabilidad con mayor facilidad? ¿Tiene la flexibilidad de consultas alguna consecuencia imprevisible?
En este artículo, analizaré todas estas cuestiones y ofreceré algunas recomendaciones a modo de guía sobre qué valores predeterminados y controles admiten una implementación más segura de GraphQL. Para abordar todos estos asuntos, seguiré una clasificación en tres categorías: configuraciones de riesgo, consultas abusivas y vulnerabilidades de las API web. ¡Vamos a ello!
Consejos de configuración
Los atacantes pueden aprovecharse de una serie de funcionalidades legítimas que ofrecen las implementaciones de GraphQL como, por ejemplo, la introspección, las sugerencias de campo y el modo de depuración. Por ello, hay que tener cuidado a la hora de hacerlas disponibles.
1. Evitar la introspección
El riesgo: GraphQL es un entorno introspectivo o, dicho de otra manera, se pueden hacer consultas en un esquema de GraphQL para encontrar información que exponga detalles reveladores sobre sus estructuras de datos o incluso sobre sus argumentos, campos, tipos, descripciones y estados de tipos obsoletos. Si se filtrara toda esta información, podrían quedar expuestas otras superficies de ataque, que a su vez pueden ofrecer otras vulnerabilidades a las que sacar partido.
Por ejemplo, si quieres crear una lista con todos los tipos en un esquema y obtener detalles sobre cada uno, puedes utilizar una consulta de introspección para preguntar:
{
__schema {
types {
name
kind
description
fields {
name
}
}
}
}GraphQL también ofrece, a través del mismo token, un entorno de desarrollo integrado (IDE) llamado GraphiQL (si te fijas bien, lleva una i después de Graph). GraphiQL permite a los usuarios crear consultas en una interfaz intuitiva con unos simples clics en los campos y las entradas. Se puede hacer un uso fraudulento de GraphiQL para entender el esquema utilizado y luego exponer otras superficies de ataque, como consultas o mutaciones existentes.
A base de interrogar al servidor con estas artimañas, los atacantes pueden conseguir los elementos que les faltan para crear un ataque complejo y grave. Imagina que utilizamos la introspección y logramos descubrir un objeto llamado UploadFile:
{
"name": "UploadFile",
"kind": "OBJECT",
"description": null,
"fields": [
{
"name": "content"
},
{
"name": "filename"
},
{
"name": "result"
}
]
}Un método que se nos puede ocurrir para aprovechar este hallazgo es un ataque de recorrido para acceder o modificar archivos y directorios que se almacenan fuera de la carpeta raíz web. Para este ejemplo, supongamos que el argumento filename permite cualquier cadena y permite escribir a cualquier ubicación del sistema de archivos del servidor. Así, creamos una consulta al intentar escribir un archivo llamado poc.php de la siguiente manera:
mutation {
uploadFile(filename:”../../../../var/www/html/app/poc/poc.php”, content: “<?php
phpinfo(); ?>”){
result
}
}Después de realizar esta llamada mediante nuestro vector de ataque, podemos comprobar que se nos facilita la ejecución de un código arbitrario. A partir de este, podríamos intentar acceder a un shell inverso para que interactuase con el entorno subyacente del servidor.
La solución: la introspección resulta útil durante el proceso de desarrollo, pero debes evitarla al dar acceso a información sensible protegida.
Puede ser tentador usar la introspección como ayuda para que los usuarios aprendan cómo se consulta la API, pero es más seguro ofrecer documentación por separado, como readthedocs. Si se deshabilita la introspección, no se corrige en sí ninguna vulnerabilidad, pero al menos se lo ponemos más difícil a los atacantes.
Muchas implementaciones de GraphQL habilitan la introspección por defecto. Sin embargo, deshabilitar la introspección para todo el sistema es lo más seguro. Por suerte, existen recursos útiles que explican cómo se limita la introspección en marcos de trabajo y lenguajes de programación populares, como Ruby, NodeJS, Java, Python y PHP. Nuclei, por su parte, ofrece una plantilla que se puede utilizar para probar la introspección de las implementaciones de GraphQL.
2. Deshabilitar sugerencias de campo
El riesgo: si la introspección se deshabilita, los atacantes pueden intentar atacar por fuerza bruta el esquema de GraphQL mediante una funcionalidad llamada «sugerencias de campo». Las sugerencias de campo se activan al introducir un nombre de campo incorrecto en una consulta. Esta acción ocasiona una respuesta de error que revela campos con nombres parecidos.
Por ejemplo, si se envía una consulta para obtener el nombre (query { name }), se obtiene la siguiente respuesta:
{
"errors": [
{
"message": "Cannot query field \"name\" on type \"Query\". Did you mean \"node\"?",
"locations": [
{
"line": 2,
"column": 3
}
]
}
]
}La solución: las sugerencias de campo pueden ser de utilidad para los desarrolladores a la hora de intentar integrar una API con GraphQL o contra API públicas. Aun así, esta funcionalidad debe usarse con cautela. Deberías plantearte deshabilitarla en cualquier entorno que dé acceso a información sensible protegida.
3. Deshabilitar el modo de depuración
El riesgo: se supone que los errores deben tener alguna utilidad; es decir, deben aportar información sobre lo que ocurre cuando se producen errores de funcionamiento. Sin embargo, la gestión incorrecta de los errores puede provocar problemas de seguridad de diversa índole en GraphQL.
GraphQL se puede ejecutar en modo de depuración. Su principal funcionalidad es la visualización detallada de errores de petición que contribuyen al proceso de desarrollo. No obstante, esto puede traer consigo consecuencias negativas si ejecutas la implementación de GraphQL en producción con la depuración habilitada. Por un lado, se producirían demasiados errores como, por ejemplo, seguimientos del stack. Por otro lado, se revelaría otro tipo de información sensible en la respuesta, lo cual pone en riesgo la seguridad y el cumplimiento de normas.
Ejemplo de seguimiento del stack
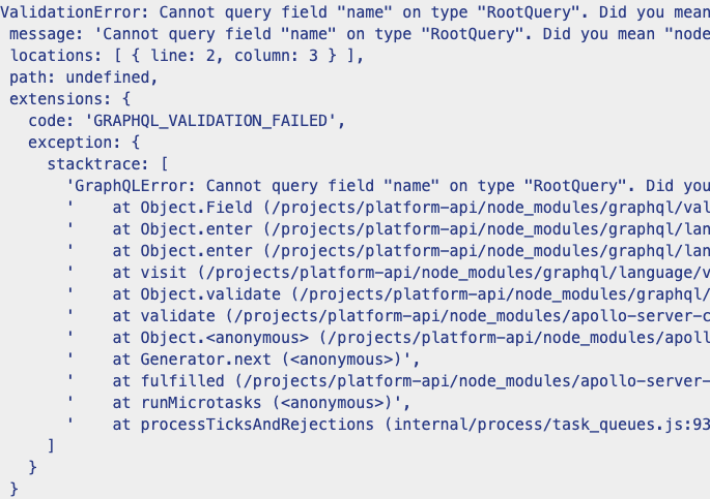
La solución: asegúrate de que el modo de depuración está deshabilitado en producción y omite los seguimientos del stack antes de devolver la información a los clientes en la respuesta.
Hay tres maneras de llevar un registro de los seguimientos del stack sin devolverlo al usuario y poniéndolo solo a disposición de los desarrolladores. Una de ellas, quizás la más conocida, garantiza un mejor control sobre los errores: consiste en implementar un programa intermedio que permita inspeccionar y modificar una petición. De este modo, es posible redactar u ocultar errores.
Consejos para lidiar con ataques maliciosos
Los atacantes pueden crear consultas maliciosas en GraphQL que les permitan realizar ataques de denegación de servicio (DoS), de enumeración o por fuerza bruta.
4. Establecer una profundidad máxima
El riesgo: en GraphQL, cada consulta presenta una profundidad expresada en el número de campos anidados y la cantidad de objetos que contienen los campos anidados. En lugar de enviar peticiones normales, los atacantes pueden crear una consulta que aumente en complejidad de forma exponencial sin apenas esfuerzo. De esta manera, se sobrecarga el sistema y se produce una DoS. Esto también puede ocurrir por error como, por ejemplo, cuando un usuario no sabe crear una consulta de manera adecuada.
En GraphQL, se puede producir una consulta cíclica si dos tipos se hacen referencia entre sí. Esta puede crecer de manera exponencial, lastrar los recursos y dejar el servidor fuera de servicio.
Por ejemplo, una implementación de GraphQL puede presentar una relación circular definida de la siguiente manera:
type Blog {
comments(first: Int, after: String)
}
Type Comment {
blog: Comment
}
Type Query {
blog(id: ID!): Blog
}Vemos, pues, que se pueden consultar tanto los comentarios de un blog como un blog de comentarios. Así, es más sencillo que un usuario malicioso desarrolle una consulta anidada pensada para multiplicar de forma exponencial la cantidad de objetos cargados. Por ejemplo:
query nefariousQuery {
blog(id: “some-id”) {
comments(first: 9999) {
blog {
comments(first: 9999) {
blog {
# ... repeat
}
}
}
}
}
}La solución: configurar una profundidad máxima puede mitigar los ataques que abusan de la profundidad y la complejidad en GraphQL. Dicho esto, en algunos casos, la profundidad de la consulta no basta para saber cuántos recursos exigirá. Es posible que incluya un campo en concreto que tarde más en resolverse, de modo que se consumirán más recursos.
Para evitarlo, se puede recurrir a una técnica llamada análisis de coste de consulta. Esta técnica asigna costes a campos para garantizar que el servidor pueda rechazar campos si tienen demasiado peso. Sin embargo, antes de dedicar tiempo a implementar esta mitigación, debemos asegurarnos de que la necesitamos de verdad. Si nuestro servicio no presenta relaciones anidadas de coste elevado o es capaz de soportar la carga, puede que esta medida no sea necesaria.
5. Perfeccionar el procesamiento por lotes
El riesgo: una ventaja fundamental de GraphQL es el procesamiento por lotes de consultas, es decir, la capacidad de empaquetar un grupo de peticiones en una sola. No obstante, sin los debidos límites preventivos de seguridad, el procesamiento por lotes de GraphQL puede crear vulnerabilidades que los atacantes intentarán aprovechar.
Sin ir más lejos, a continuación tenemos un fragmento de código de una consulta en lote utilizada para pedir múltiples instancias de un objeto de usuario, que los atacantes podrían usar para un ataque por fuerza bruta:
query {
user(id: "101") {
name
}
second:user(id: "102") {
name
}
third:user(id: "103") {
name
}
}Los atacantes podrían servirse de esta funcionalidad para enumerar cada posible usuario en una sola petición. Este tipo de ataque por fuerza bruta, específico de GraphQL, dificulta su detección, ya que se pueden solicitar múltiples instancias de objetos en una sola petición. En cambio, una API de REST obligaría al atacante a enviar una petición distinta por cada objeto.
Al presentarse como una única petición, el procesamiento de consultas por lotes permite burlar las herramientas habituales de seguridad de aplicaciones, como los WAF, la autoprotección de aplicaciones en tiempo de ejecución (RASP), sistemas de prevención y detección de intrusiones (IDS/IPS) o sistemas de gestión de eventos e información de seguridad (SIEM).
La solución: una forma de mitigar los ataques al procesamiento de consultas por lotes de GraphQL de forma adecuada es añadir limitaciones de volumen en objetos. Por ejemplo, puedes realizar un seguimiento del número de instancias de objetos distintas que el autor de la llamada ha pedido y bloquearlas cuando supere el límite de objetos pedidos.
Otra opción para prevenir este tipo de ataque consiste en excluir objetos sensibles del procesamiento por lotes. Esto obligaría a los atacantes a probar otra vía de acceso, como una API de REST, que enviaría una petición por objeto.
Además, también podría ser útil limitar el número de operaciones que se pueden procesar por lotes y ejecutar al mismo tiempo.
6. Adelantar la validación de entrada
El riesgo: GraphQL no dista mucho de otras arquitecturas de API, por lo que las aplicaciones que usan GraphQL presentan las vulnerabilidades que ya conocemos y a las que tenemos tantísimo pavor. Depende del desarrollador, pues, validar y corregir las entradas para prevenir peticiones maliciosas.
Por ejemplo, veamos cómo se puede aprovechar una vulnerabilidad por inyección de comando del sistema operativo mediante GraphQL.
Supongamos que tenemos un retailer online que realiza una operación para conocer las existencias de un artículo en el inventario. Por motivos históricos, el servidor consulta un sistema antiguo mediante una secuencia de comandos del shell que utiliza como argumentos itemId, vendorId y color:
inventorycount.sh 80 200 redEste script obtiene el número de artículos en el inventario, que devuelve en la petición. Puesto que la aplicación no implementa defensa alguna, un atacante podría introducir un comando arbitrario como el siguiente:
red ; env ;La consulta de GraphQL resultante sería así:
query {
inventoryCount(itemId:80, vendorId:200 color:”red; env ;”,)
}Esta consulta devolverá más tarde los contenidos de variables de entorno, que podrían contener datos secretos y otra información sensible.
Ejemplo de respuesta
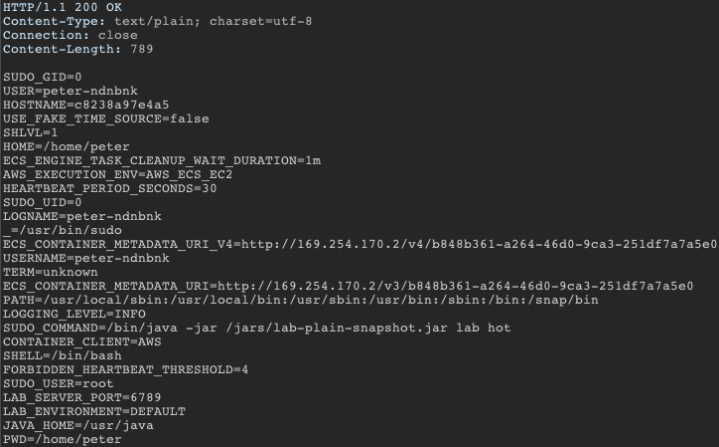
La solución: por regla general, la entrada se debería validar cuanto antes en el flujo de datos. Por muy corregida y validada que esté, no debería usarse para dar a un usuario el control del flujo de datos. Asimismo, todos los datos entrantes deben validarse mediante tipos de datos scalar y enum de GraphQL.
También es posible escribir validadores de GraphQL personalizados para realizar validaciones más complejas. La creación de listas de consultas permitidas en GraphQL también puede reducir el impacto potencial al indicarle al servidor que no permita pasar ninguna consulta que no se haya aprobado con anterioridad. Si, aun así, esto te quita el sueño o no logras salir de la espiral de complejidad, te recomendamos nuestro WAF de última generación (anteriormente Signal Sciences).
Con vistas al futuro
GraphQL es un estándar nuevo de interacción con las API: debemos ser conscientes de que puede conllevar ciertos problemas de seguridad y presentar una superficie de ataque.
Para desarrollar software seguro es necesario comprender los principios de seguridad subyacentes de cualquier tecnología en la que se base el desarrollo. Entender los fallos de seguridad que pueden ocurrir en cualquier etapa del ciclo de desarrollo reduce en gran medida los problemas e incidentes futuros, ya sea en proyectos donde se use GraphQL u otro lenguaje.
Sabemos que la seguridad funciona mejor cuando se lleva a cabo una defensa en profundidad. Si se produce un fallo en un control de seguridad o se introduce una vulnerabilidad, ahora nuestro WAF de última generación (antes Signal Sciences) ofrece compatibilidad en fase beta con GraphQL.