
This article is part two of Fastly’s "Pillars of Resilience" series, exploring how we design, build, and operate our global network for maximum availability and performance. Read the full series:
The internet is a complex and unpredictable environment where disruptions are an everyday reality. For a global Content Delivery Network (CDN) like Fastly, this means constantly preparing for and responding to a variety of challenges, from network congestion and power outages to malicious attacks. Instead of hoping to prevent all failures, we believe a truly resilient platform should be measured by how quickly it responds to and recovers from them.
In our introductory post, we said resiliency is measured by how quickly a disruption is detected, how minimal the disruption becomes, and how quickly all services are returned to their normal levels. Today, we are going to discuss two of our resiliency pillars focused on minimizing the impact of a disruption: fault isolation and graceful degradation.
Fault Isolation
Delivering content to hundreds of millions of users worldwide presents a unique set of challenges. A power failure in a single data center could take a large part of a network offline. A network outage could make a Point of Presence (PoP) unreachable. A DDoS attack could render a collection of servers unresponsive. However, such disruptions should not take the entire CDN down. This is where fault isolation becomes a critical consideration in the design of all aspects of the CDN. By isolating faults, a CDN ensures that an issue doesn't cascade and cause a widespread outage. The goal is to limit the fault’s effect to the smallest footprint as possible (reduce the blast radius). This allows as many services as possible to continue operating with no visible impact on users.
Effectively minimizing the impact of a disruption requires careful consideration during every phase of a deployment. We like to think about operating a CDN like a software engineering problem. By borrowing techniques and strategies from software design principles, we inherently embed fault isolation into all aspects of our services. Single-function, modular components isolate critical capabilities. Modules that hide their internal state preclude other components from accessing corrupted data. Components are only granted the minimum level of privilege needed to perform their task. Well-defined interfaces with robust error checking minimize the distribution of bad data. Logging and monitoring enable traceability of actions within every component. Redundancy allows for fast failover.
An example of redundancy in action is our architecture for a single site. We deploy a number of servers, which we refer to as cache nodes, within a single PoP, and each cache node is capable of serving the same content. If a cache node fails or becomes unreachable, another cache node can immediately take over serving the content to the requesting user. The image below shows both the number of requests flowing into a single cache node and the total number of requests flowing into the site. At the 23:37 mark, the single cache node stops handling requests due to a hardware failure. However, the total number of requests handled by the site barely changes due to the cache failure. The robust observability within our systems and the fast failover enabled by redundant capabilities contain the disruption to just the affected cache node and isolate the failure from affecting the efficient handling of requests from users.
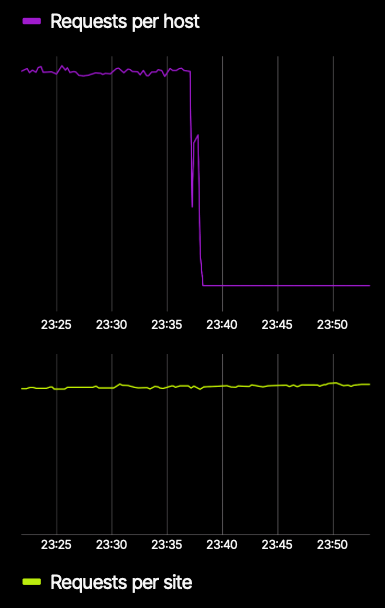
Failure of a single cache node does not impact the handling of incoming requests
Graceful Degradation
Fault isolation keeps disruptions from impacting other components of the system, but that isn’t sufficient. If an issue is encountered, we want systems to continue operating if at all possible. This brings us to graceful degradation. We prefer to have components, services, and systems continue operating in a degraded state rather than failing completely. A global, complex system like Fastly’s can’t be thought of as being “up” or “down”. Reduced functionality (e.g., response delay) is better than no functionality (500 Internal Server Error).
This concept goes hand-in-hand with fault isolation. As faults are isolated, the other components of the system continue to operate, albeit without the service provided by the failing component. For example, if a logging endpoint becomes unresponsive, it “fails open” and workloads continue to operate. If failures are more complex, some systems may become subject to an ever-growing load. To combat this, we employ a number of techniques to maintain the highest level of service to users. Depending on the situation, we may:
Shed Non-Critical Load: During a disruption, we can elect to pause collection of lower-priority metrics. Allowing the system to focus on maintaining as much service as possible for the end user.
Serve Stale Content: If an origin server is unavailable or slow, Fastly can be configured to serve a stale, but still available, version of the content from its cache instead of serving an error page. This ensures that the user experience remains fast and responsive.
A key benefit of graceful degradation is the positive impact it has on acute incident response. If key systems simply stopped working due to a disruption, operational staff would have to focus all their attention on restoring service as quickly as possible. When the system degrades its capabilities but continues to serve content, the incident responders get breathing room to focus on identifying the root cause of the issue. Time is spent diagnosing the problem, identifying mitigations, documenting remediation items, and restoring services to their normal levels.
Building a Resilient CDN
Disruptions are inevitable. The true measure of a platform is not its ability to prevent failures, but its ability to respond to and recover from them. Fault isolation and graceful degradation, supported by a strong foundation of observability, are critical pillars of resilience. By approaching the network as a software engineering problem, Fastly ensures that its infrastructure is built to be disruption-resistant and can withstand and recover from even the most challenging events.
Ready to build a more resilient online experience? Learn more about Fastly's platform.