

This article is part three of Fastly’s "Pillars of Resilience" series, exploring how we design, build, and operate our global network for maximum availability and performance. Read the full series:
"Fastly’s Pillars of Resilience: Building a More Robust Internet" (Part 1)
"Design for Chaos: Fastly’s Principles of Fault Isolation and Graceful Degradation" (Part 2)
At the start of this series (and in part two as well), we discussed our obsession with resilience as a core philosophy at Fastly, embedded in our culture and architecture. We also introduced the concept of observability as the bedrock of a resilient system, allowing us to understand our network's constantly changing state and how that understanding allows us to respond with precision. Now, we'll dive into two critical pillars of that resilient architecture that leverage observability: distributed decision making and self-healing systems.
A centralized approach, where a single authority makes all decisions for a global network, presents significant risks. Any single point of failure, such as a fiber cut, a power outage, or a configuration error in one data center, can take a large portion of a network offline. Relying on a centralized point of control is the epitome of a single point of failure. And it is not just benign errors that have to be considered. In today’s ecosystem, DDoS attacks or other malicious activities are a way of life and can overwhelm a centralized system. The sheer scale of a global Content Delivery Network (CDN) necessitates robustness that far exceeds what a centralized point of control can provide.
As we have said before, our approach to resilience is not about preventing every disruption, that's a way of life with complex global infrastructure, but about minimizing the impact and recovering as quickly as possible. The true measure of a platform's resilience is how it responds to and recovers from failures. To that end, Fastly focuses on making decisions where they are needed and developing systems that can heal themselves.
Distributed Decision Making
Fastly's architecture is designed around the principle of distributed decision-making. Instead of a single, centralized brain, our network is composed of many loosely coupled systems and sites. Each Point of Presence (PoP) operates with a high degree of autonomy, making real-time decisions based on its own operational state, such as which server will handle a request. Our architecture is constructed to avoid a complete system collapse being triggered by the failure of a single component.
This approach also significantly reduces the need for a global shared state. Maintaining a single source of truth across a massive, geographically distributed system is a complex and error-prone process. It introduces a single point of congestion and failure, as all nodes must communicate with this central authority to get updates. By reducing or eliminating the need for this global coordination, our system can operate more quickly and with greater independence. Each PoP and server can make localized decisions without waiting for a global consensus, which is crucial for the speed and reliability demanded by our customers.
Key benefits of this approach include:
Reduced Single Points of Failure: By distributing intelligence and decision-making, we eliminate the risk of a single point of failure taking down the entire network.
Enhanced Performance: Requests are routed to the nearest available PoP, minimizing latency and ensuring a faster, more responsive user experience.
Rapid Adaptation: Each server's ability to make independent decisions allows for rapid adaptation to changing network conditions without relying on a centralized backend.
Increased Reliability: If one location fails, other servers can still accommodate customer traffic. The network can dynamically adapt to location and provider status, ensuring content remains available even during outages.
A good example of how Fastly utilizes distributed decision making is our Precision Path algorithm. Each server tracks the health of all its TCP connections. If a server detects a degradation in performance on a TCP connection, it tests all available routes and selects the most viable new path in order to route around the issue. We can do this since Fastly pushes routing information all the way down to each server (i.e., local decision making). So, the decision to select a new path is done in the affected server, using TCP performance metrics and local routing information. The illustration below shows the increased performance after treatment is applied to the impacted connection. The graph shows the number of bits transmitted at each time step. The control line shows performance on the original network path, and the treatment line shows performance measured on the best alternative path.
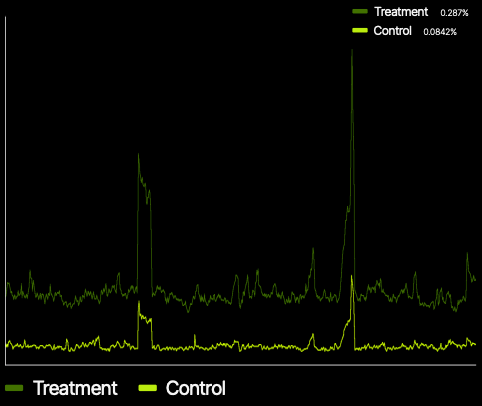
Performance boost from Precision Path
Self-Healing Systems
Distributed decision making is deeply intertwined in the Fastly DNA, and it goes hand-in-hand with our focus on self-healing capabilities. Our systems are not just designed to withstand disruptions, but to automatically detect and recover from them. This is achieved through high levels of automation and making those decisions at the point of impact.
A critical enabler of this self-healing capability is high-resolution observability. As we discussed in our earlier post, observability is the bedrock of a resilient system. It provides the machine-speed notification of errors required for rapid, automated response. By collecting and analyzing a high volume of data from our systems, we can quickly detect even the most subtle issues. This real-time, granular view of the system's health allows our automated systems to not only identify a problem but to initiate a pre-planned, localized response, such as shifting traffic away from a degraded node, with minimal human intervention. This machine-speed detection and response is fundamental to minimizing the impact and duration of any disruption.
Key insights about this pillar:
Automation: Fastly's architecture leverages automation to ensure that changes can be tested, deployed, and managed independently. This enables us to make changes quickly and safely without depending on other teams.
Loosely Coupled Systems: Our systems are built as independent components that can fail or be updated with minimal impact on the rest of the network. This is a fundamental contrast to a tightly coupled architecture, where a small change can lead to large-scale, cascading failures.
Loosely Coupled Teams and Services: This architectural style enables our teams to develop and deploy features independently, which allows for faster iteration and a more agile response to issues.
Our Autopilot logic serves as an exemplar for self-healing systems. In a nutshell, Autopilot works at the broader routing level to steer traffic towards higher-performing paths. It receives network telemetry data that it uses to influence route selection in order to get the best performance out of all available paths. Every minute, Autopilot collects network telemetry and uses it to project traffic demand. If demand is about to reach capacity on an egress link or the link is performing below that of alternate links, Autopilot makes decisions to reroute traffic. This approach eliminates the need to wait for packet loss to indicate congestion and allows our routing infrastructure to heal itself rather than waiting for an operator to instigate an override. The below illustrates how many routing changes are being initiated by Autopilot to ensure network performance.
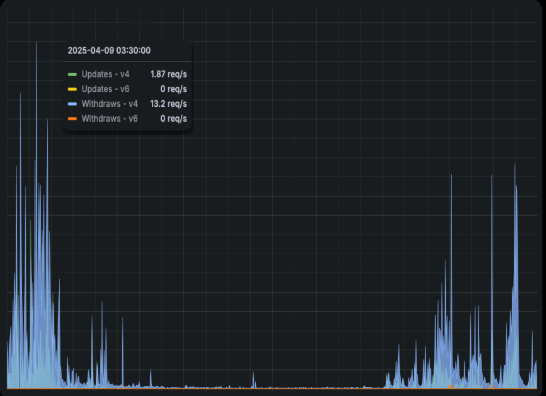
Rate of routing changes instigated by Autopilot
Fastly's Resilient Architecture: Distributed Decision Making & Self-Healing in Action
By combining distributed decision making and self-healing systems, we can ensure our edge continues to serve content even in moments of uncertainty. This is not a theoretical concept; it is a design philosophy that has been tested in real-world incidents. We are continuously learning and improving our systems to strengthen our failover strategies and ensure that our services, and by extension, our customers' services, are highly available.
For more detailed information on Precision Path and Autopilot, please read our original post on the topics.