

This article is part one of Fastly’s "Pillars of Resilience" series, exploring how we design, build, and operate our global network for maximum availability and performance. Read the full series:
Every request counts. From transactions to streaming, user experience hinges on latency and reliability. A slow or unavailable website doesn't just annoy users; it hits the bottom line, erodes brand trust, and leads to lost revenue. On a global scale, the challenge of delivering content reliably is magnified exponentially.
You’ve heard about resilience from us before. We’re sort of hung up on, some might say obsessed with, the topic. It’s a core philosophy embedded in our culture, architecture, and processes. Some of the principles we’ll be talking about have already been publicized [1][2]. But we’re pulling them all together to illustrate how Fastly has engineered its network for maximum resilience. We'll explore the core principles and technologies that allow us to not only deliver content lightning fast but to do so with unwavering availability. We call these our Pillars of Resilience.
The Challenge of Global Distribution
Imagine trying to serve a single piece of content, such as an image, to hundreds of millions of users scattered across the globe. All those users aren’t geographically close to a single location that has the content. They’re also probably not all using the same access network. That content may originate anywhere on the Internet. If it is popular, many people want it. This global distribution paradigm presents a unique set of challenges:
Geographic Latency: The speed of light is a physical limit. A request from a user in London to a Point of Presence (PoP) in Sydney will always be slower than a request to a PoP in Paris, no matter how powerful the servers are in the Sydney PoP.
Network Congestion: Internet traffic is not uniform. Certain routes can become overwhelmed, leading to bottlenecks and degraded performance.
Single Points of Failure: A fiber cut, a power outage, or even a configuration error in a single data center can take a large portion of a network offline.
Adversarial Events: From distributed denial-of-service (DDoS) attacks to targeted malicious activity, the network must be prepared to absorb and mitigate a constant barrage of threats.
For a Content Delivery Network (CDN), these aren't just theoretical problems; they are the everyday reality. A CDN's value is directly tied to its ability to overcome these challenges consistently and serve customers’ content to the end-users. For our customers, a highly available and resilient CDN isn't a "nice-to-have"; it's a fundamental requirement. By offloading content delivery to a CDN like Fastly, businesses gain significant advantages:
Guaranteed Uptime: Your website or application remains accessible even if there's an issue with your origin server or a major network route.
Superior Performance: Content is served from the nearest available PoP, minimizing latency and ensuring a faster, more responsive user experience.
Cost Savings: By absorbing traffic spikes and mitigating attacks, a resilient CDN reduces the load on your own infrastructure, lowering operational costs.
Peace of Mind: You can focus on building your core product, knowing that the underlying delivery mechanism is designed to withstand the unpredictable nature of the internet.
To be clear, no one is immune. Disruptions happen. They’re a way of life when operating a complex, global infrastructure. Resilience is detecting the onset of the disruption as quickly as possible. Resilience is minimizing the impact of the disruption. Resilience is the speed at which services are returned to their normal levels. The true measure of a platform is not the prevention of failures, but how it responds to and recovers from them.
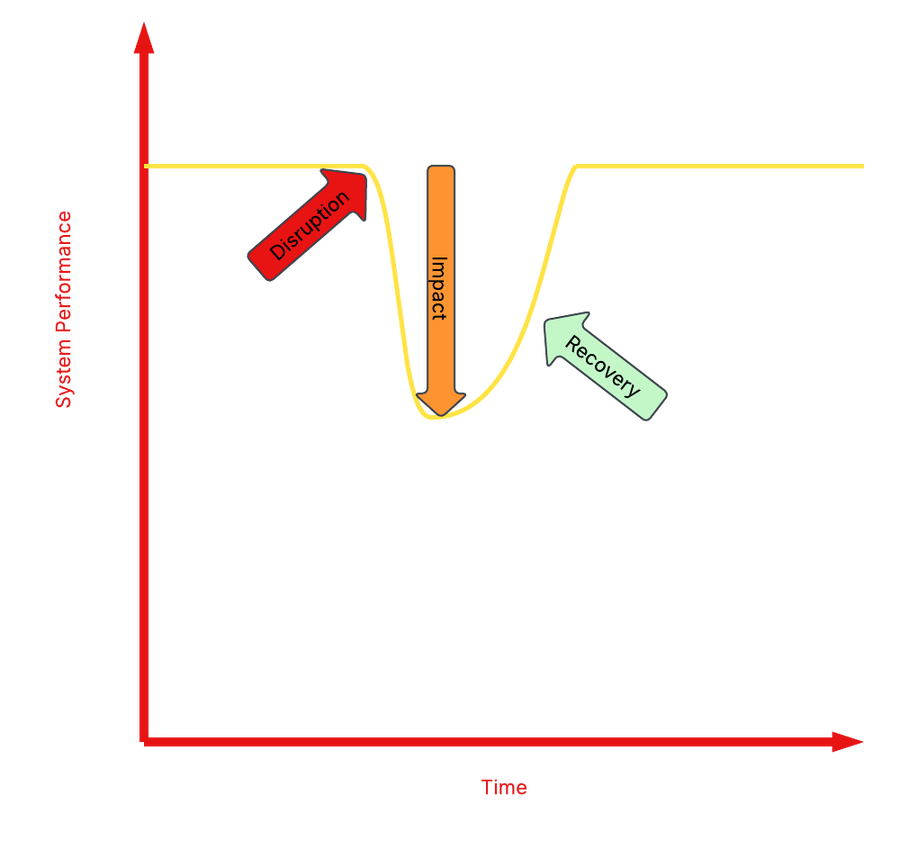
System resilience determines the depth and width of the impact trough
The Bedrock of Resilience: Observability
Before we dive into the specific pillars, we’ll first discuss a foundational capability that runs throughout them: Observability.
You cannot build a resilient system if you do not understand its behavior. At Fastly, we believe that observing a system is not about just looking at simple metrics like CPU usage or bandwidth. It's about being able to answer arbitrary questions about the state of the network at any moment in time. This includes:
Metrics: Tracking performance indicators like request rates, latency, and cache hit ratios.
Logs: Capturing detailed records of events to diagnose issues.
Traces: Following a single request as it travels through the system to identify bottlenecks and points of failure.
Simple metrics can only support reactive network operations. They do not provide enough context, especially given the complexity of a global CDN. Consider the following visualization:
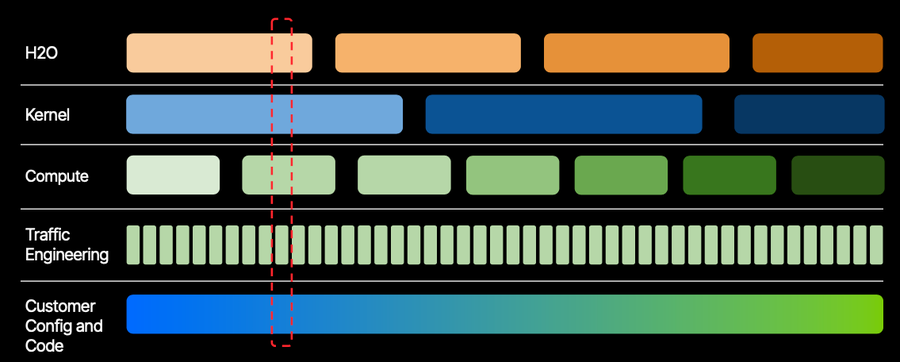
Every permutation of the state of production (code, configuration, workload) is different
The actual state of our system is always changing. Software is not static. Network state is not static. Customer workloads are not static. We must operate a network that has no baseline for comparison. As these variables evolve, our view of normal evolves.
Our engineers have access to a live, comprehensive view of every part of the network. 2.1 trillion data points each day. Our baseline collection frequency is 15 seconds, but with the ability to capture some metrics at much higher frequencies to facilitate diagnostics and debugging. We have a baseline set of metrics that are always collected, as well as other sets that can be enabled when the onset of an issue is detected. Metric collection can also be configured to capture at different percentiles (e.g., 99.9999 versus 99.99) since some events have distinctive appearances at different resolutions.
This deep observability is critical for everything from proactive maintenance to rapid incident response. It allows us to not only detect problems but to understand their root cause with precision, a non-negotiable step in building a truly resilient system. Our observability capability also facilitates data-driven capacity planning and system optimizations. Allowing us to adjust before something bad happens.
It is crucial for everyone to understand that such a capability does not come for free. Collecting such a volume of data is expensive. Multiple data pipelines need to be maintained to harvest the metrics. Back-end storage is needed to house the metrics. Compute resources are needed to turn the data into information. It should come as no surprise that observability is one of our top 3 infrastructure spend categories. But we think the expense is necessary in order to truly understand our complex infrastructure.
What's Next?
In the posts to follow, we will explore the individual pillars of resilience that supply the foundation of our global infrastructure. We'll discuss how we architect our network to be highly available, build it to be disruption resistant, and operate it to withstand and recover from even the most challenging events.