

Im Jahr 2020 tauchte eine Idee auf: Könnten wir die Bereinigung von Varnish-Anforderungen intelligenter gestalten, indem wir nur den tatsächlich genutzten Speicher löschen, anstatt immer den gesamten Block zu löschen? Die Theorie war, dass weniger Speicherschreibvorgänge weniger vergeudete Zyklen bedeuten, und im Fastly-Maßstab führt das zu erheblichen Leistungssteigerungen.
Aber es gab ein Problem. Wenn die Buchhaltung auch nur geringfügig fehlerhaft war, konnte dies zu einem Datenleck von einer Anfrage zur anderen führen. Das ist ein Risiko, das kein Entwickler eingehen möchte. Die Idee blieb so lange ungenutzt, bis wir einen Weg hatten, ihre Sicherheit zu beweisen. In diesem Blog wird erklärt, wie wir genau das gemacht haben.
Die alte Methode: Immer 512 KB löschen
Jede eingehende Anfrage in Varnish erhält einen 512 KB großen Arbeitsbereich, der auf zwei 256 KB große Regionen aufgeteilt ist (eine für die Bearbeitung der eingehenden Anfrage in Varnish und eine für jede Backend-Anfrage an den Origin-Server). Dies ist im Wesentlichen ein Notizblock für temporäre, anfragebezogene Daten. Am Ende der Anfrage hat Varnish die gesamte Region gelöscht, unabhängig davon, wie viel verwendet wurde.
Das war einfach, sicher, aber teuer. Unabhängig davon, ob eine Anforderung 10 KB oder 500 KB umfasste, hat Varnish trotzdem ein halbes Megabyte überschrieben. Bei unseren Traffic-Niveaus bedeutete das einen Berg unnötiger Speicheroperationen.
Die schlummernde Idee: High-Watermark-Bereinigung
Die Optimierung bestand darin, den High Watermark zu verfolgen, also den am weitesten entfernten Punkt im Workspace, der während einer Anfrage berührt wurde.
Wenn die Anfrage nur 20 KB belegen würde, würden wir 20 KB löschen, nicht die vollen 512 KB. Aber wenn das Tracking deaktiviert war, könnten nicht gelöschte Bytes bestehen bleiben. Das ist ein Datenleck mit Ansage.
Der Durchbruch: Konzentration auf den eigentlichen Engpass
Auf einem kürzlich abgehaltenen Effizienzgipfel hat einer unserer Engineers aus dem H2O-Team ein Gesamtsystem-Performance-Modell erstellt. Die Ergebnisse zeigten, dass bei einigen AMD-Rechnern der Speicher-Traffic – und nicht die CPU-Zyklen – der eigentliche Flaschenhals war. Das verschob das Gleichgewicht: Plötzlich war das Löschen nach High Watermarks nicht nur eine nette Idee, sondern etwas, das es wert war, verfolgt zu werden. Die Herausforderung bestand darin, die Sicherheit zu gewährleisten.
Gewährleistung der Sicherheit
Der schwierige Teil war nicht, den Code zu schreiben, sondern zu beweisen, dass der Watermark immer korrekt war. Wenn wir uns einfach auf die Nachverfolgung verlassen würden, könnte ein fehlendes Byte zu einem Datenleck zwischen den Anfragen führen. Die Überprüfung jeder einzelnen Anfrage hätte jedoch die Performancegewinne zunichtegemacht.
Der Durchbruch bestand darin, etwas zu nutzen, das wir bereits hatten: Integritätsprüfungen des Arbeitsbereichs, die nach den meisten Arbeitsbereichsoperationen durchgeführt werden. Indem wir uns in diese einklinken und Zufallsstichproben hinzufügen, konnten wir die Korrektheit überprüfen, ohne ständigen Kostenaufwand zu verursachen oder den Speicher-Traffic von Varnish unnötig zu erhöhen. Die Überlegung war einfach: Ein einzelner Rechner, der 1 von 20.000 Vorgängen prüft, würde nicht viel abfangen, aber bei Tausenden von Rechnern sind das über eine Million Prüfungen pro Sekunde. Das ist ausreichend, um Vertrauen in großem Maßstab aufzubauen.
Wir haben die Watermark-Bereinigung im Schattenmodus eingeführt:
Trotzdem wurde weiterhin alles gelöscht – Jede Anfrage löschte weiterhin die vollen 512 KB.
Nutzung trotzdem verfolgen – Jede Anfrage verfolgte auch ihre High Watermark, als ob die Optimierung aktiv wäre.
Stichprobenprüfungen – Etwa 1 von 20.000 Workspace-Operationen wurde geprüft: Alles, was über dem Watermark lag, wurde erneut gelesen, um zu bestätigen, dass es nicht verwendet wurde.
Um den Kostenaufwand niedrig zu halten:
Wir haben die bestehenden Integritätsprüfungen des Arbeitsbereichs wiederverwendet.
Wir haben die Verifikationsschleife für die SIMD-Vektorisierung so strukturiert, dass die CPU mehrere Bytes pro Befehl verarbeiten kann.
Wir haben den generierten Maschinencode überprüft, um zu bestätigen, dass der Compiler vektorisierte Anweisungen und keine langsame skalare Schleife ausgegeben hat.
Nachdem wir diese Methode bei der gesamten Flotte angewandt hatten, hatten wir die statistische Gewissheit, dass wir der Watermark-Verfolgung vertrauen konnten. Erst dann haben wir die Optimierung wirklich aktiviert.
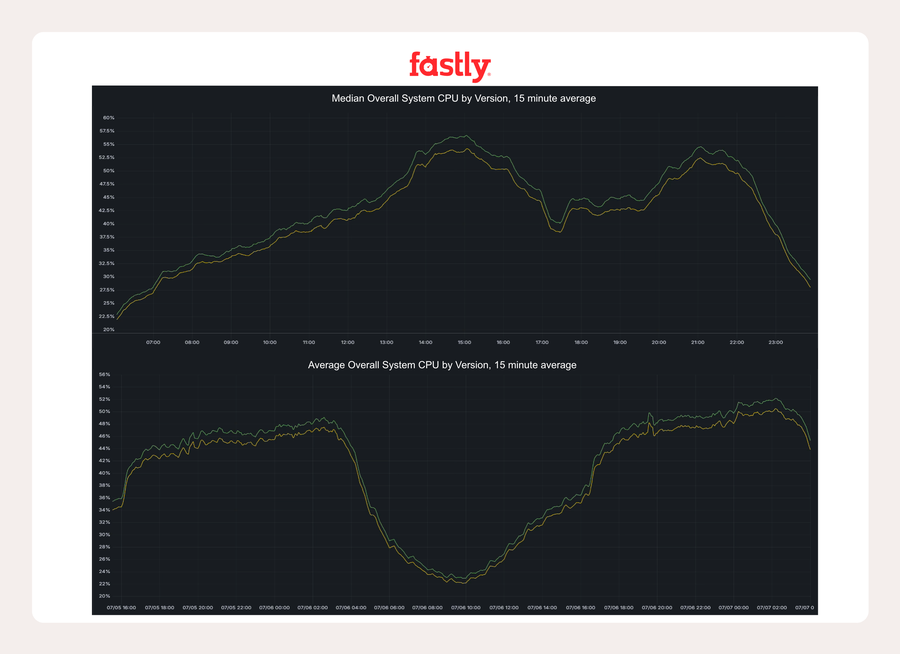
Rollout und Ergebnisse
Wir folgten unserer üblichen konservativen, auf Sicherheit ausgerichteten Einführung und begannen mit einem Test auf einigen Hosts der Produktivumgebung, bevor wir das Projekt auf die gesamte Flotte ausweiteten. Die Ergebnisse waren signifikant:
In Marseille schrieben Hosts im Watermark-Modus etwa 10 GB/s weniger in den Speicher – eine 25-prozentige Reduzierung der Schreibvorgänge im Speicher im Vergleich zum vollständigen Löschen. Bei AMD-Rechnern reichte dies aus, um die Speicherbandbreite als Flaschenhals zu beseitigen und so Effizienzgewinne im gesamten Stack zu erzielen.
In einem stark frequentierten europäischen POP sank die System-Nutzung des Systems zu Spitzenzeiten um mehr als 2 Prozentpunkte.
In KCGS720, Teil des kritischen IAD Metro POP, betrug die Reduzierung etwa 1,5 Prozentpunkte.
Auf Intel-Computern hatten wir keinen Engpass bei der Speicherbandbreite, sodass sich die Gesamtsystem-Nutzung nicht so stark veränderte, aber die spezifischen Metriken für Varnish verbesserten sich trotzdem.
Die Auswirkungen waren verblüffend: Durch die Reduzierung des Speicher-Traffics von Varnish verbesserte sich die Anweisungsrate pro Zyklus (IPC) von H2O, obwohl H2O selbst nicht verändert wurde. Wenn Sie Speicherbandbreite freigeben, geben Sie anderen Prozessen mehr Spielraum.
Lektionen für Entwickler
Sicherheit steht an erster Stelle – eine Optimierung, bei der das Risiko besteht, dass Daten verloren gehen, ist schlimmer als nutzlos.
Seien Sie geduldig in großem Maßstab – die Stichprobe über Millionen von Operationen pro Sekunde gab uns Vertrauen statt Vermutungen.
Messen Sie das Richtige – die Speicherbandbreite, nicht die CPU, war hier der eigentliche limitierende Faktor.
Bauen Sie auf dem auf, was Sie haben – die Wiederverwendung von Integritätsprüfungen reduziert die Komplexität.
Optimieren Sie die Optimierung – vektorisierte Kontrollen machten Sicherheit erschwinglich.
Erwarten Sie systemweite Auswirkungen – die Behebung eines Engpasses kann auch anderen, nicht damit zusammenhängenden Code zugutekommen.
Überdenken Sie alten Code – Ideen, die vor Jahren ad acta gelegt wurden, können mit neuen Einblicken realisierbar sein.
Achten Sie auf die Schnittstellen – Ein Großteil der Debugging-Probleme trat an den Schnittstellen zwischen den Systemen auf.
Für Entwickler lautet die Lehre: Konzentrieren Sie sich nicht nur auf die offensichtlichen CPU-Zahlen. Verstehen Sie, wo Ihr System tatsächlich zum Engpass wird, beweisen Sie Sicherheit in großem Maßstab, und Sie können Effizienzsteigerungen erzielen, ohne die Korrektheit zu opfern.
Machen Sie Ihren Code schneller und schlanker, ohne die Sicherheit zu beeinträchtigen. Legen Sie noch heute mit einem kostenlosen Fastly-Entwickler-Account los.