

Bei Fastly sagen wir gerne „cachen ist König“ (erstens, weil es das ist, und zweitens, weil wir alle große Fans von Effizienz sind!) Wir lieben Cachen-Effizienz. Effizientes Caching kann enorme Verbesserungen bei der Performance, Sicherheit, Netzwerkstabilität und Kosteneinsparungen bringen … die Liste geht weiter. Je weniger Ihre Origin-Server kontaktiert werden müssen, desto besser. Und das ist für die Nutzer, die Ihre Website oder App besuchen, von großer Bedeutung – sie sollte sofort, reaktionsschnell und effizient sein. Das bedeutet, dass die Verwaltung der Auslastung Ihrer Server Priorität hat.
Was ist Request Collapsing?
Eine der „Superkräfte“ unserer Plattform, die zur Effizienz beiträgt, ist das Request Collapsing, die Praxis, mehrere gleichzeitige Anforderungen für dasselbe Objekt zu einer einzigen Anforderung an den Ursprung zusammenzufassen und die daraus resultierende Antwort zu verwenden, um alle anstehenden Anforderungen zu erfüllen. Um besser zu verstehen, was damit erreicht wird, schauen wir uns eine Basic gecachte Antwort genauer an:

Einfach und effizient, nicht wahr? Aber jeder Schritt in diesem Prozess wird Zeit benötigen, also werfen wir einen noch genaueren Blick darauf:

So weit, so gut! Aber was passiert, wenn eine Flut von Nutzern alle zur gleichen Zeit das Gleiche wollen – wir aber nicht in der Lage waren, es von Ihrem Ursprung abzurufen? Dies passiert ständig während Live-Videostreams oder bei neuen Game Releases. Dort tritt das Request Collapsing auf. Die Architektur und Caching-Plattform von Fastly ermöglicht es uns, dieselbe Ursprungsantwort zu verwenden, um Anforderungen zu bedienen, die eingegangen sind, nachdem wir mit dem Abrufen begonnen haben. Das bedeutet, dass alle diese Anforderungen die frischestmögliche Antwort erhalten, ohne dass zusätzliche Abrufe vom Ursprung erforderlich sind. Nutzer erhalten frische Inhalte (und haben ein gutes Erlebnis), Ihr Ursprung ist geschützt, und das Beste daran ist, dass es sehr effizient ist.
Wann kann Request Collapsing stattfinden?
In unserem vorherigen Beispiel haben wir gesehen, wie das Request Collapsing eine leistungsstarke Teilmenge des Caching-Verhaltens von Fastly darstellt. Es ist immer standardmäßig aktiviert, und Sie müssen nichts Besonderes tun, um davon Advantage zu ziehen. Das gesagt, handelt es sich um ein situationsabhängiges Verhalten, das erfordert, dass bestimmte Dinge innerhalb sehr kurzer Zeiträume geschehen, und nicht alle Kunden-Workflows können davon profitieren.
Zuerst müssen die Anforderungen cache-interaktiv sein, was bedeutet, dass sie ein Cache-Objekt erzeugen, das nachfolgende Anforderungen verwenden können. PASS-Anforderungen und viele Fehler sind standardmäßig nicht zwischenspeicherbar, was bedeutet, dass wir diese Anforderungen nie erfolgreich zusammenfassen können. Wenn wir es nicht cachen können, werden wir die Anforderungen nicht auf die Antwort zusammenfassen können.
Zweitens müssen Anforderungen gleichzeitig mit der Anforderung sein, die den Abruf vom Ursprung initiiert hat, um sie zu reduzieren. Das bedeutet, dass wir die Anforderung erhalten, während wir sie bereits abrufen, um eine frühere Anforderung zu erfüllen. Sobald diese Antwort abgeschlossen ist, übernimmt das normale Caching-Verhalten und das Zusammenführen wird beendet. Dies geschieht am häufigsten bei cachen Objekten, die sich häufig ändern und sehr gefragt sind, sodass viele Nutzer sie gleichzeitig benötigen und wir sie häufig vom Ursprung abrufen müssen.
Die Parallelität wird durch Funktionen wie Cluster und Origin Shield erhöht. Beide konzentrieren Anforderungen innerhalb unserer Plattform, um Effizienz und Performance zu verbessern. Möglicherweise sehen Sie auch häufiger ein Request Collapsing, wenn ein Ursprung länger für die Antwort benötigt, entweder weil das Objekt größer ist oder der Ursprung überlastet ist. Da die Zeitspanne, in der wir auf die Antwort warten, länger ist, gibt es mehr Zeit für das Zusammenbrechen von Anforderungen.
Etwas kontraintuitiv ist, dass schnellere Ursprünge und Funktionen, die die TTFB verkürzen, verringern, wie oft wir Anforderungen zusammenfassen können. Wie oben erläutert, werden wir Anforderungen nur zusammenfassen, während wir auf die Antwort vom Ursprung warten. Sobald die Antwort für uns einsatzbereit ist, hören wir auf, uns zusammenzufalten. Die Aktivierung der Streaming-Miss-Funktion kann dieses Zeitfenster erheblich reduzieren, da die Funktion es ermöglicht, das cachen-Objekt zu verwenden, sobald die Header für die Ursprungsantwort empfangen wurden.
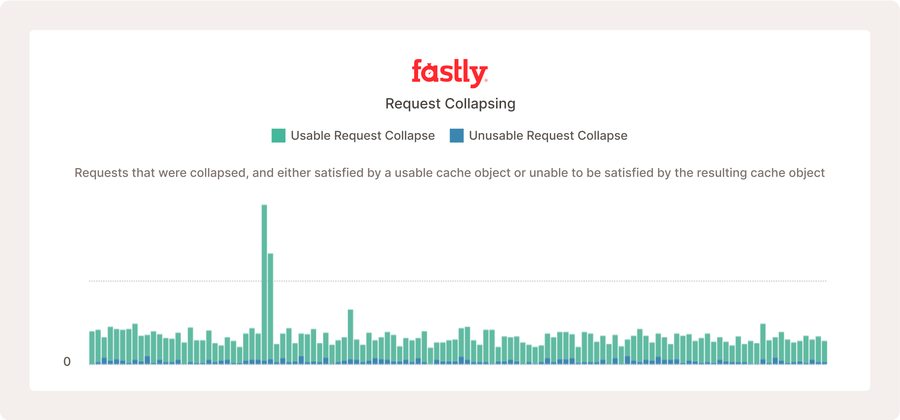
Oben ist ein Teil des Media Shield Dashboards für einen beliebten Live-Video-Service zu sehen. Request Collapsing tritt auf, aber da der Origin-Server schnell ist und die Konfiguration so effizient, geschieht dies im Vergleich zur Anzahl der Anfragen, die er erhält, nicht sehr häufig.
Metriken für Request Collapsing
Nachdem wir nun besser verstanden haben, was Request Collapsing ist und was es bewirkt, lassen Sie uns die Metriken genauer betrachten, die Sie im Auge behalten sollten. Diese Metriken helfen Ihnen zu verstehen, ob es funktioniert (oder nicht!) und wie effektiv es arbeitet.
Wir haben zwei Metriken eingeführt, die jetzt sowohl in Echtzeit- als auch in historischen Statistiken verfügbar sind:
request_collapse_usable_countrequest_collapse_unusable_countUnsere Kunden können diese Metriken über unsere APIs abrufen oder Sie können ein Custom Panel verwenden, um sie in unseren Observability - und Media Shield -Dashboards anzuzeigen. Um näher ins Detail zu gehen:
Usable_count: zählt, wie häufig wir Anforderung zusammengefasst und ein verwendbares cachen-Objekt gefunden haben. Um nutzbar zu sein, muss das Objekt cachefähig sein und eine positive Cache-Lebensdauer aufweisen. Die Cachen-Lebensdauer ist die TTL des Objekts minus sein Alter (wie lange wir es im cachen hatten). Sobald die Cache-Lebensdauer eines Objekts nicht mehr positiv ist, läuft sie ab und ist für die Cache-Usage nicht mehr gültig, außer zum Ausliefern veralteter Daten. Die Cacheability wird ebenfalls durch die Variable beresp.cachefähig geregelt und ist an anderer Stelle dokumentiert.
Unusable_count: ist das Gegenteil von dem oben genannten – usable_count. Wenn eine Antwort unbrauchbar ist, müssen wir versuchen, sie erneut vom Ursprung abzurufen. Im Allgemeinen ist dies ein schlechtes Zeichen und könnte bedeuten, dass es ein Konfigurationsproblem mit Ihrem Ursprung, Ihrem service oder einem nicht zwischenspeicherbaren Workflow gibt, der nicht übergeben wird. (Wenn Sie diese beiden Werte zusammenzählen, erfahren Sie, wie häufig Anforderungen zusammengeführt werden!)
Verständnis von Request-Collapsing-Metriken
Fast geschafft! Wir haben Dashboards, mit denen Sie überprüfen können, wie sich Ihr Traffic auf unserer Plattform verhält, und Sie wissen, worauf Sie achten müssen – aber es gibt auch viele neue Zahlen zu verwalten … was ist gut? Was ist schlecht?
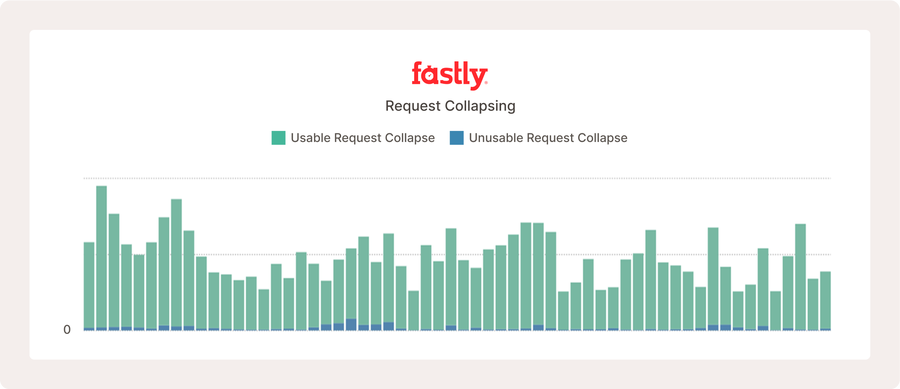
Die obige Darstellung zeigt die Metriken des Request Collapsing für ein stark frequentiertes Open-Source-Projekt, bei dem viele Nutzer regelmäßig nach neuen Inhalten suchen, was die Häufigkeit des Request Collapsing erhöht.
Um zu verstehen, was funktioniert und was nicht, müssen Sie zunächst über ein grundlegendes Verständnis der Traffic-Muster Ihrer Nutzer verfügen. Request Collapsing ist unwahrscheinlich, wenn Ihre Anforderungen auf eine große Anzahl von URLs verteilt sind, die sich nicht sehr oft ändern. Es ist wichtig, sich daran zu erinnern, dass die meisten Anfragen, die innerhalb von 25–150 ms gleichzeitig eintreffen, zusammengeführt werden. Das ist ein sehr kleines Zeitfenster. Bestimmte Workflows profitieren mit höherer Wahrscheinlichkeit von Request Collapsing. Nachrichtenseiten, Live-Videostreams und beliebte Datei-Downloads werden wahrscheinlich viel häufiger Request Collapsing erleben. Es hängt alles davon ab, wie viele Nutzer gleichzeitig dasselbe Objekt anfordern.
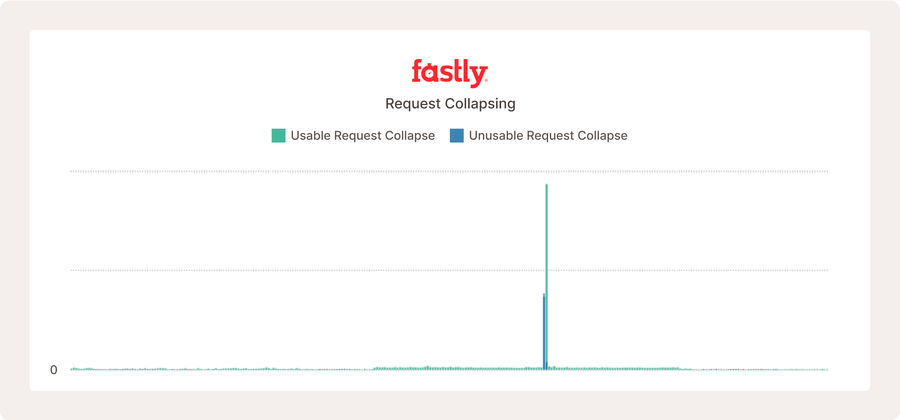
Im obigen Beispiel einer echten Website tritt Request Collapsing häufig erst dann auf, wenn es zu einem plötzlichen Anstieg des Traffics für dieselben cachen Objekte kommt.
Es ist wichtig zu betonen, dass ein geringeres oder höheres Volumen an Request Collapsing weder gut noch schlecht ist. Dies ist keine Metrik, um die Sie sich kümmern müssen, ob sie erhöht oder verringert wird, mit einer Ausnahme (dazu gleich mehr!). Es zeigt, wie oft wir Nutzer gleichzeitig direkt von Ihrem Origin-Server aus bedienen. Eine gute Faustregel ist, zu berücksichtigen, wie hoch diese Zahlen im Vergleich zu Ihrem gesamten Anforderungsvolumen sind. Es ist völlig normal, dass es zu geringfügigem Request Collapsing mit einem unbrauchbaren Ergebnis kommt. Dies liegt daran, dass viele Backend-Fehler nicht cachefähig sind, und gelegentlich kann das Nutzerverhalten dazu führen, dass wir eine Anforderung eines Objekts genau zum richtigen Zeitpunkt stellen, sodass es zum Zeitpunkt des Empfangs bereits abgelaufen ist. Das ist völlig zu erwarten.
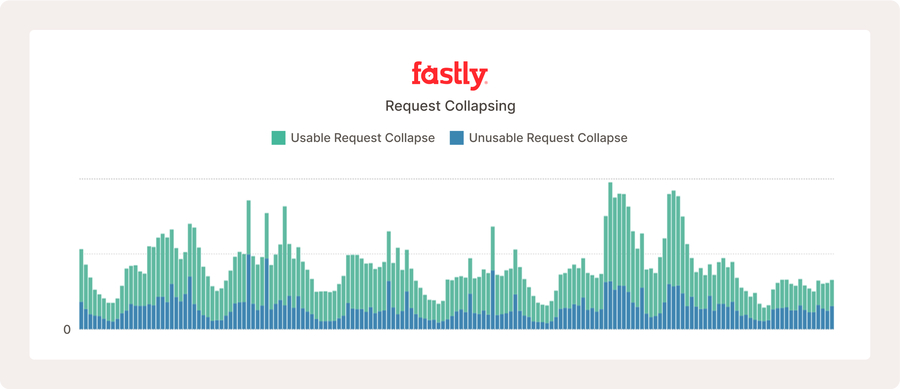
Viele unbrauchbare Antworten können problematisch erscheinen, wie oben gezeigt. Diese Website bedient jedoch über zehn Millionen Anforderungen pro Stunde, und was wir sehen, ist ein normales Internetverhalten aufgrund legitimer Fehlerantworten, die nicht zwischengespeichert werden können.
Zurück zu der Vorwarnung, die ich erwähnt habe: Eine Sache, auf die Sie sehr achten sollten (und sich an Ihren Fastly-Vertreter wenden sollten, wenn Sie dies bemerken), ist, wenn Sie im Vergleich zu Ihren Anforderung hohe Mengen an unbrauchbaren Zählern haben. Dies ist ein potenzieller Indikator für die Anforderungsserialisierung. Wir werden das in einem zukünftigen Blog ausführlicher besprechen, aber kurz gesagt bedeutet die Anforderungsserialisierung, dass Fastly versucht, ein Objekt zu holen, um mehrere Anforderungen auf einmal zu erfüllen, aber die Antwort ist nicht in der Lage, ein gültiges cachen-Objekt zu erstellen. Wenn dies geschieht, erhält die erste Anforderung das unbrauchbare Objekt, und die nächste Anforderung versucht es erneut. Wenn dies weiterhin geschieht, werden wir immer wieder nur auf eine Anforderung nach der anderen antworten. Dies ist sehr ineffizient und kann zu echten Auswirkungen auf die Nutzer führen.
Ein weiteres Problem bei diesen Metriken ist, dass sie nicht erkennen können, ob Anforderungen bei einigen wenigen sehr stark frequentierten Objekten oder bei einer großen Anzahl von nur mäßig frequentierten Objekten zusammenbrechen. Dies ist wichtig, da große Mengen unbrauchbarer, verteilter Objekte für Ihren Workflow völlig normal sein können. Request Collapsing kann ein kompliziertes Thema sein, aber wenn Sie es bis hierher geschafft haben, hoffen wir, dass Sie dies auf Ihrer Effizienzreise informativ fanden. Wir planen, dieses Thema in zukünftigen Blogs ausführlicher zu behandeln. Sie dürfen also gespannt sein!