

2020年に、あるアイデアが浮上しました。Varnish リクエストのクリーンアップを、ブロック全体を常に消去するのではなく、実際に使用されたメモリのみをクリアすることで、よりスマートにできるのではないか、というものでした。理論上、メモリへの書き込み回数が減れば無駄なサイクルも減り、Fastly のスケーラビリティではそれが大幅なパフォーマンス向上につながるはずでした。
しかし、問題がありました。登録を少しでも誤ると、リクエスト間でデータが漏洩する可能性があるのです。これは開発者が絶対に避けたいリスクです。このアイデアは安全性を証明する手段が確立されるまで休眠状態でした。このブログでは、それをどのように実現したかを説明します。
従来の方法 : 常に 512 KB を消去
Varnish のすべての受信リクエストは 512 KB のワークスペースを受け取り、2つの 256 KB の領域に分割されます (1つは Varnish に入ってくるリクエストの処理用、もう1つはオリジンへのバックエンドリクエスト用)。これは基本的に、一時的なリクエストごとのデータ用のスクラッチパッドです。リクエストの最後に、使用量に関係なく、Varnish は領域全体をクリアしました。
それはシンプルで安全でしたが、高価でした。リクエストが 10 KB を使用したか 500 KB を使用したかに関係なく、Varnish は 0.5 メガバイトをゼロクリアしました。当社のトラフィックレベルでは、これは膨大な不要なメモリ操作を意味していました。
休眠中のアイデア : ハイウォーターマーククリアリング
最適化では、リクエスト中に触れられるワークスペース内の最も遠いポイントであるハイウォーターマークを追跡します。
リクエストが 20 KB のみ使用していた場合、512 KB 全体ではなく 20 KB を消去します。しかし、追跡がオフになっていると、クリアされていないバイトが残る可能性があります。これはデータ漏洩の危険性を孕んでいます。
ブレークスルー : 真のボトルネックに焦点を当てる
最近の効率性サミットで、H2O チームのエンジニアの一人が、システム全体のパフォーマンスモデルをビルドしました。その結果、一部の AMD マシンでは、CPU サイクルではなくメモリトラフィックが真のボトルネックであることがわかりました。それでバランスが変わりました。突然、ハイウォーターマーククリアリングは単なる良いアイデアではなく、追求する価値のあるものになりました。課題は、その安全性を保証することでした。
安全性の確保
難しかったのはコードを書くことではなく、ウォーターマークが常に正確であることを証明することでした。単純に追跡機能を信頼すると、バイトの欠落がリクエスト間でデータ漏洩を引き起こす可能性があります。しかし、すべてのリクエストをチェックすれば、パフォーマンス向上の効果が失われてしまいます。
画期的だったのは、すでに存在していた機能、つまりほとんどのワークスペースオペレーションの後に実行されるワークスペースの整合性チェックを使用することでした。これらにフックしてランダムサンプリングを追加することで、一定のオーバーヘッドを追加したり、Varnish のメモリトラフィックを不必要に増加させたりすることなく、正確性を検証できます。理由は単純です。1台のマシンで20,000回のオペレーションのうち1回をサンプリングしても、検出できるものはほとんどありませんが、数千台のマシンでは、1秒あたり100万チェックを超えます。これは、大規模に信頼を築くには十分です。
私たちは、シャドウモードでウォーターマークの消去を導入しました。
引き続きすべてを消去 – すべてのリクエストで 512 KB 全体の消去を継続しました。
使用状況は追跡 – 各リクエストは最適化が有効であるかのように、ハイウォーターマークを追跡しました。
サンプルチェック – ワークスペース操作の約2万回に1回を監査対象に設定 : ウォーターマークを超える全データを再読み込みし、未使用を確認しました。
オーバーヘッドを低く抑えるには :
既存のワークスペースの整合性チェックを再利用しました。
SIMD ベクトル化の検証ループを構築し、CPU が命令ごとに複数バイトを処理できるようにしました。
生成されたマシンコードを調べて、コンパイラが遅いスカラーループではなく、ベクトル化された命令を出していることを確認しました。
フリート全体でこの方法を実行した後、ウォーターマークの追跡を信頼できるという統計的な自信が得られました。そうして初めて、実際に最適化が可能になりました。
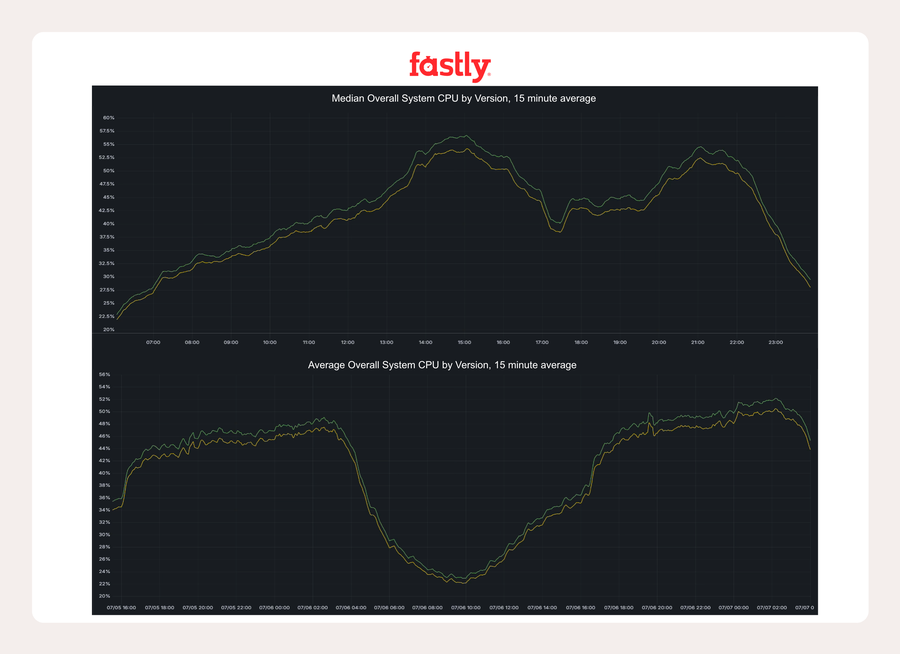
展開と結果
我々は従来通りの保守的で安全第一の展開方針に従い、まず数台の本番環境ホストでカナリアテストを実施した後、全ホスト群へ拡大しました。結果は顕著でした。
マルセイユでは、ウォーターマークモードを実行しているホストは、完全なクリアリングと比較して、メモリへの書き込みが 10 GB/s 少なく、メモリ書き込みが 25% 削減されました。AMD マシンでは、これでメモリ帯域幅のボトルネックが解消され、スタック全体の効率性が向上しました。
ある忙しいヨーロッパの配信拠点では、システムの CPU 使用率がピーク時に2パーセントポイント以上低下しました。
重要な IAD メトロ POP の一部である KCGS720 では、減少率は約1.5パーセントポイントでした。
Intel マシンでは、メモリ帯域のボトルネックはなかったので、全体的なシステム従量課金プランはそれほど変化しませんでしたが、Varnish 固有の指標は改善されました。
波及効果は顕著でした。Varnish のメモリトラフィックを削減することで、H2O 自体に変更がなかったにもかかわらず、H2O のサイクルあたりの命令数 (IPC) が向上しました。メモリ帯域幅を解放すると、他のプロセスがよりスムーズに動作する余地が生まれます。
開発者への教訓
セキュリティが最優先です– データ漏洩のリスクがある最適化は役に立たないどころか有害です。
大規模な処理では忍耐が必要– 1秒あたり数百万の操作をサンプリングすることで、推測ではなく確信が得られました。
適切なものを測定する – ここでの真の制限要因は、CPU ではなくメモリ帯域でした。
既存のものを基にビルド– 整合性チェックを再利用することで複雑さを軽減します。
最適化を最適化 – ベクトル化されたチェックにより安全性を手頃な価格で実現できます。
システム全体への影響を期待してください – 1つのボトルネックを修正すると、無関係なコードにもメリットがもたらされる可能性があります。
古いコードの再検討 – 何年も前に棚上げされたアイデアが、新しいインサイトによって実現可能になるかもしれません。
インターフェースに注意– デバッグの苦労の多くは、システム間の接合点にありました。
開発者にとっての重要なポイントは、明らかな CPU 数値だけを追い求めないことです。システムの実際のボトルネックとなっている場所を理解し、大規模に安全性を証明すれば、正確性を犠牲にすることなく効率性を向上させることができます。
安全性を犠牲にすることなく、コードをより速く、よりスリムにします。今すぐ無料の Fastly 開発者アカウントを作成して始めましょう。