
Coordination is hard and computers are hard, so it’s no surprise that things go wrong when coordination happens in computers. In the computing context, coordination is referred to as concurrency, the ability for a system to execute many things at once and, therefore, faster.
Speed is a definite advantage, but writing concurrent software requires engineers to accurately understand interactions between concurrent elements in their programs — which is why a non-trivial number of concurrency bugs emerge. These are particularly pernicious bugs because they are not only subtle — difficult to detect, diagnose, and avoid — but also pose a palpable problem for systems resilience.
Deadlocks are one type of concurrency bug that can lead to stalled, frozen, or even crashed applications — which can imperil meeting service objectives around uptime. This type of bug occurs when entities within programs are stuck because they’re waiting for resources that are held by entities that are stuck because they are waiting… and it is indeed the recursive nature of deadlocks that makes them so vile when they arise in production systems.
This post will illuminate how deadlock bugs emerge, some facets of their fascinating and frustrating strangeness, and guidance on how to handle them in your own systems.
Coordination is hard
Computers have a trove of resources within them — like files, network connections, or even data structures in memory — that programs need to use to fulfill their purpose(s). The entities that may want exclusive access to a resource include threads, processes, actors, and fibers. For simplicity’s sake, we’ll stick to exploring deadlocks through the lens of processes.
So what if multiple processes want to use the same resource at the same time? The mechanism for managing this demand operates via mutual exclusion (aka “mutexes”), which determines when a resource should be used by one process or another.
Consider a program, /bin/texttransform, that performs operations like reading, writing, or deleting lines of text in files. Different instances of this program can run at the same time to handle different requests using whatever resources are required to fulfill the operation. An example would be multiple copies of /bin/texttransform running on a web server that processes concurrent requests from different clients to read a line of text from FileA.txt.
But if one instance of the program needs to write a line of text in FileA.txt, while another instance of the program needs to delete a line of text in the same file, how do you manage which process uses the file and when?
Hence, the necessity of a mutual exclusion mechanism to facilitate efficient coordination — or, in more computer-y terms, to synchronize concurrent access to resources. For instance, your browser needs to ensure all the tabs you have open (in my case, far too many) can safely coordinate access to your browsing history database.
The mutual exclusion mechanism has two primary operations:
Acquire the mutex: This acquires a right to use the resource associated with the mutex (like
FileA.txtin our example). If another process already has the right to use the resource, you must wait until that other process releases its right before you can successfully acquire the right to use it. The mutex is also referred to as a “lock” because it locks out anyone else from using the resource while you have the right to use itRelease the mutex: This releases your right to use the resource associated with the mutex; the “lock” on access is opened. If another process is waiting for the resource, it will immediately acquire the right to use it after you release it.
As long as everyone uses the mutual exclusion mechanism consistently and doesn't break the rules, there won’t be a problem. Operations are sped up through concurrent execution and programs reach their intended outcomes sooner. The distributed system can gallop off into a glorious sunset, basking in its consummate concurrency.
But the real world is messy. Things can and do go wrong, and mutual exclusion is not spared from this fate.Despite the “lock” terminology, mutexes are more akin to traffic lights: everyone must know the convention and follow it perfectly for it to succeed. There are some obvious mistakes possible with a mutual exclusion system that could foment a nightmare in distributed systems, like downtime or latency spikes. Let’s dive into them.
Deadlocks in the multi-mutex of madness
What if there is more than one resource that is needed simultaneously?
Let’s say one of the texttransform program’s tasks is to remove a line from a source file (FileA.txt) and append it to a destination file (FileB.txt). If texttransform wants access FileA.txt and FileB.txt at the same time, it must hold the mutexes for each at the same time. The program can acquire the mutexes for the source file at startup and then acquire another mutex for the destination file, perform the text transfer operation, then release both mutexes once the operation completes.
This is precisely where opportunities for deadlock emerge. It won’t be immediately obvious to the developer who made this mutex design choice that this is precarious. After all, a lock for each resource sure sounds safe, right?
But what if /bin/texttransform is launched with a request to move text from FileA.txt to FileB.txt around the same time that another instance of the program is asked to move lines in the opposite order, from FileB.txt to FileA.txt? The first program may receive the right to use FileA.txt but will be stuck waiting to use FileB.txt. The other program will have access to FileB.txt but be stuck waiting to use FileA.txt (a condition called a “circular wait”). Both of the programs are waiting for rights that will never be released!
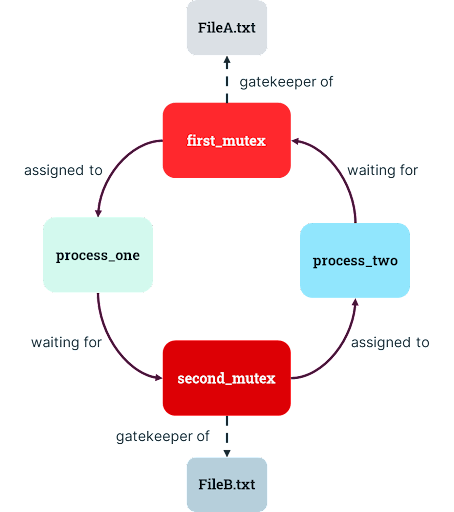
This is the dreaded deadlock. The resource locks will never be released, and there is no steward to inform the system that, “The mutex, my lord, is dead.” Files or other resources on a system can be requested by multiple processes at the same time, leaving them languishing in a digital purgatory in which they’re all waiting to acquire access and none of them can move forward with their lives.
The system impact of a deadlock can be a frozen application or even a system crash, jeopardizing precious uptime in distributed systems. Even entirely unrelated work can be stalled, a nightmare requiring powerful necromantic sorcery to overcome, for nothing short of the murder and reanimation of the system — along with sacrifices to the eldritch debugging gods to beg for a bountiful debug information harvest — will suffice to simulate and fix the cause of the deadlock.
How do mutex design choices result in deadlocks?
The design decision that leads to deadlocks — one mutex for each resource — is a natural conclusion for developers to reach when grappling with how to handle concurrency. It’s the most obvious choice, but it isn’t the only one. So how do things end up this way?
A developer may realize that each instance of their process may also need to coordinate access to multiple files (like FileA.txt, FileB.txt, FileC.txt, and FileD.txt), so all of those resources will need mutual exclusion enforced. At this point, the developer might start browsing log cabins off-the-grid and curse the existence of computers as mutual exclusion requirements spiral out of control.
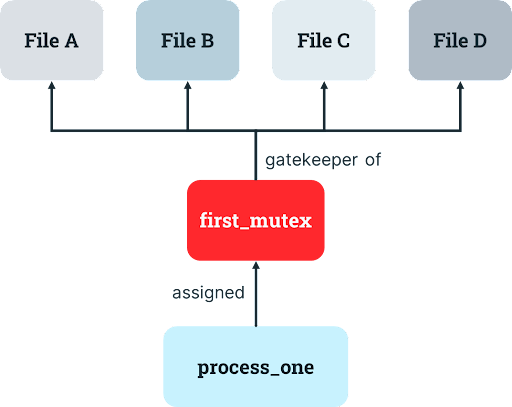
How can we handle this complexity? One way is for the developer to reduce the complexity by simplifying the mutex design to use only a single mutex. The developer can specify that whenever a process has the right to use one resource, they also have the right to use another resource. This is a reasonable choice if one resource is only needed when the other resource is also needed.
Let’s go back to our prior example: one of /bin/texttransform’s tasks is to remove a line from a source file (FileA.txt) and append it to a destination file (FileB.txt). The developer can implement a single mutex to ensure the process agrees to acquire the appropriate rights to both files before performing these operations and to release the mutex after it finishes. In fact, this mutex will apply to all invocations of the process, regardless of which files are accessed, since process instances operating on disparate files still must coordinate.
The problem with the single mutex design is that it can result in idle resources. If another instance of the process is already running and has the appropriate mutex, then the process will wait for that other instance to release the mutex before proceeding with its own operations. But if there are tasks that only require the first resource and other tasks that only require the second resource, one of the resources may sit idle even when a process needs it and hurt system performance, which makes human operators sad (and probably the computers, too).
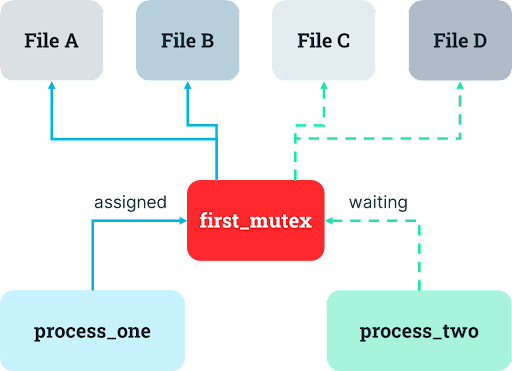
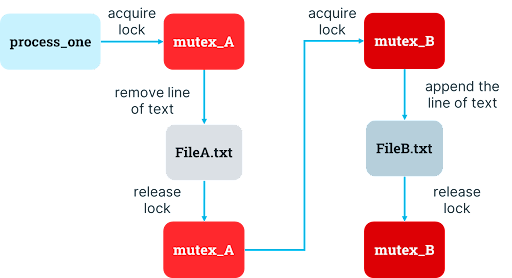
To resolve this problem of idle resources, the developer might naturally consider multiple mutexes to support greater concurrency. It could make sense to introduce another mechanism so that access to one resource can be coordinated separately from access to the other resource. The developer decides to migrate from a single mutex covering all the files it could need to individual mutexes for each file which the process acquires in sequential order, releasing each one once the relevant operation is complete.
In the case of texttransform that needs access to FileA.txt and FileB.txt, this decision results in two mutexes. When the process wants to remove a line from FileA.txt and append it to FileB.txt, it now must acquire the mutex for FileA.txt, remove the line from FileA.txt, release the mutex for FileA.txt, acquire the mutex for FileB.txt, append the line to FileB.txt, and release the mutex for FileB.txt.
Unfortunately, a sneaky, subtle problem emerges: lines can get jumbled when there are concurrent transfers from one file to another. Let’s consider two invocations of our program which are meant to copy the last line of the source file, PaleFire.txt, and append it to the destination file, EmptyFire.txt:
PaleFire.txt1 I was the shadow of the waxwing slain
2 By the false azure in the windowpane;
3 I was the smudge of ashen fluff--and
4 Lived on, flew on, in the reflected sky.If the two process invocations run their first task around the same time, the first invocation now has Line 4 in its memory and is ready to acquire File B’s mutex, while the second invocation now has Line 3 in its memory and is also ready to acquire File B’s mutex. Since each invocation wants access to File B next, they are “racing” to see who acquires the mutex first. The winning process will write their line into File B first (and presumably perform a digital victory dance, or at least emit happy beeps).
But it isn’t clear which process will win, which can be a bit of delightful digital suspense if the output order doesn’t matter because it results in more concurrent use of resources. If the order does matter (like in the mission-critical realm of poetry), it can be a disaster, resulting in a bug known as a “race condition.” So, if the second invocation wins the race in our example, EmptyFire.txt will end up reading like nonsense:
EmptyFire.txt1 Lived on, flew on, in the reflected sky.
2 I was the smudge of ashen fluff--and I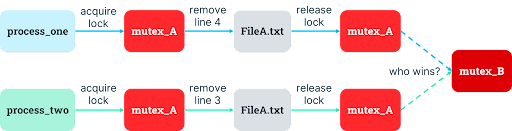
How should the developer fix this potential text mangling? Naturally, by requiring the process to hold the mutexes for each resource at the same time… bringing us back to the first design that has the deadlock opportunity. Thus, as our title foreshadowed, the developer becomes Dante in a journey through the concentric circular waits of torment located within the bowels of the machine.
Working around deadlocks
Chasing down deadlock bugs can certainly feel like entering a circle of hell. So how can developers cope with them? There are numerous workarounds and fixes for deadlocks with varying degrees of feasibility for developers working with mutexes.
The most obvious recourse for deadlocks is to go back to the simplest design: a single mutex that protects access to both items. Of course, this limits the ability to use the items concurrently, leading to the idle resource problem yet again. So, if engineering teams follow the “easiest” solution each time they encounter these problems, they’ll end up in a Kafka-meets-Sisyphus loop of:
Implement a single mutex to handle simultaneous access to two resources (like
FileA.txtandFileB.txt)But this results in idle resources, which isn’t efficient, so let’s implement a mutex for each resource instead
Oh no, now we’re encountering a deadlock. Let’s avoid it by implementing a single mutex to handle simultaneous access to the two resources.
Rinse and repeat until the heat death of the universe.
To avoid this loop, developers can carefully choose the order in which mutexes are acquired (which is especially relevant to avoid circular waits). For instance, maybe FileA.txt is always needed before FileB.txt; if so, you can enforce that order through proper placement of mutexes in your program.
The exact order of lock acquisition doesn’t matter as long as it’s consistent across your entire system — so developers can use the clever trick of specifying an arbitrary order, like alphabetical order. If more than one mutex is needed simultaneously, then they will always be acquired in the specified order, like mutex A -> mutex B -> mutex C. Alphabetical order doesn’t mean anything to the processes, but it still avoids circular waits.
As developers design and extend programs, they include mutexes throughout the program in anticipation of concurrent resource needs. But to do so successfully, they must understand which resources should be protected by which mutexes. An even heavier cognitive burden is that the developer must also understand when to acquire and release locks to ensure access to resources is not only safe, but also consistent with respect to the overall operations their program is performing — because even “safe” access to data may lead to inconsistent outcomes. And the developer also needs to know which parts of the system actually perform locking, because locking can have non-local effects and thus two components that are only indirectly connected can still bump into each other.
Therefore, in a reality of messy spaghetti code smothered in chunky complexity sauce, the ordering option is not so straightforward to implement because it basically depends on developers correctly understanding the program’s entire control flow to place mutexes correctly. And human brains are not optimized for such a task, especially in systems that change over time as new features are added.
So another option is deadlock detection. One process can back out its work, release its access rights to another process, and then request the rights once the other process is finished. For example, /bin/texttransform could discard its deletion of text in FileA.txt, release access rights to the other process instance, and try to request FileA.txt again once the other process is finished with it (what many database systems do when they detect two transactions that need exclusive access to data at the same time).
Existing approaches for deadlock detection include dataflow analysis (which includes resource allocation graphs and wait-for-graphs), model checking, and type-based approaches. Unfortunately, results are typically mixed, and implementation can be exorbitantly expensive, disincentivizing people from implementing it in production. For example, Linux offers the lockdep option, enabling an algorithm that detects some (but not all) deadlocks… but it also makes locking take a lot longer and therefore results in few people enabling it in production environments.
It's extremely difficult to know before starting the work if a deadlock could ever occur without fancy whole program analysis — making automated solutions difficult. Even just detecting deadlocks when they occur is difficult!
To make things even more confusing, it’s possible for a single process (or a single-threaded program) to deadlock. If the process acquires the right to use a resource but forgets that it has done so (a bug), when it tries to acquire the right again it will be waiting on itself to release the resource, which it never will. It’s kind of like not being able to leave your apartment because you can’t find your sunglasses… because your sunglasses are on top of your head.
For example, what happens if texttransform is asked to transfer a line from the source file into the destination file — and both files are FileA.txt? When this occurs, the process will try to acquire the mutex for FileA.txt twice: once because FileA.txt is the source file to be read and truncated, and another time because it is the destination file receiving the appendage. The process becomes deadlocked when it attempts to acquire the mutex a second time. Since it already has the mutex, it will be waiting on itself to release it.
A special kind of mutex, the recursive mutex, allows a single process (or thread) to acquire the mutex more than once; however, its use is often discouraged since it can hide lock acquisition bugs -- like forgetting to release the mutex. In our example, if one copy of /bin/texttransform forgets to release its use of FileA.txt after it’s done with it, the other process instance is left bereft of the file and stuck in their operation even though the file isn’t being used by anyone.
On the flip side, there’s also the relatively common bug of failing to acquire rights in the first place. A process could start using a resource without having acquired the rights first, which leads to quirky, arcane failures. Remember, mutexes are more like traffic lights; a developer can come up with a mutex convention for their program, but programs written by other developers won’t follow it (because they won’t even know about it). So failing to acquire rights in the first place is like running a red light.
In our example, this bug is like a program by another developer (textyeet to our texttransform) forgetting to gain the right to FileA.txt but starting to perform operations on it anyway. Then, when our program tried to use FileA.txt after properly acquiring the right to it, we’d bump into textyeet like two cooks colliding in a kitchen — which would be totally unsafe for the system! We can all agree that we want to operate distributed systems without the risk of burn injuries.
No one has discovered a straightforward general solution for deadlock bugs (yet). Even reliably detecting when a deadlock occurs is an unsolved problem. Systems can often simply fail to make forward progress without any error, requiring operators to intervene and investigate. Somewhat like the halting problem, it is possible to prove that some programs will or will not deadlock, but it’s not yet possible to prove that arbitrary programs will or will not deadlock in a generalized way.
Of course, programs that don’t use mutexes can’t deadlock by definition (but they might not be as performant, either). You can prove some uses of mutexes to be deadlock-free, but it’s super tricky to scale that up to real programs (like those running in distributed systems).
Alternatives to mutual exclusion
Honestly, the best course of action is probably to let someone else handle the problem— just pull in another system that handles concurrency for you. Basically, with anything where there might be concurrent writes (or reads) — like databases, load balancers, caches, stream processing frameworks, message busses, autoscaling and much more — it’s wise to let dedicated providers coordinate the locks rather than figuring it out yourself. (If you’re one of those dedicated providers yourself, then you really have no choice but to think about these hard problems.)
For instance, instead of writing your own concurrent queue, use Kafka or Kinesis. In our texttransform example with PaleFire.txt, the developer could store poetry in a database and use a transaction to move text from one record to another record. The database would perform the locking and figure out all the concurrency things rather than the developer having to think about it.
If a developer is having problems with deadlocks, then the answer probably isn’t to pursue something equally as complex, like CPU atomics (e.g. fetch-and-add or compare-and-swap), lock-free programming, or read-copy-update. These introduce more complexity and they’re even more difficult to get right than determining lock ordering as described above.
Conclusion
Deadlock bugs are a fascinating, ghoulish symptom of complex software systems. When they occur, they are hard to debug and usually even harder to fix. The more our software ecosystems become parallelized and concurrent in nature, the more likely deadlock bugs are to rise up bit by bit and eat our brains (or at least beleaguer our cognitive energy).
To survive the scourge of deadlocks, it is best to outsource concurrency stuff if you can. But if you must roll your own concurrency, use an arbitrary and consistent ordering of mutexes (whether alphabetic, numeric, or another consistently-applied total ordering). Locking everything together won’t work for any system that needs to be fast and operate at scale (so basically most distributed systems). If you’re operating a distributed system at speed and scale and concurrency is a core part of the value proposition you provide to customers, then putting some effort into deadlock detection — despite its mixed efficacy — is also advisable.