
Spotify on diagnosing cascading errors
War stories don’t always have tragic endings; smart risks are necessary in order to innovate. According to Nick Rockwell, CTO of The New York Times, “good risk taking” occurs in the space of the unknown, and failure can be a positive outcome — a learning experience for the future.
In this series, we’ve shared stories from technical leaders, such as HashiCorp’s Seth Vargo on recovering from an outage and Kenton Jacobsen on how to fail fast (and fix faster) at Vogue. We’ve learned that even the most routine changes (like restarting a database or switching backends) can sometimes lead to unexpected errors, but savvy teams already have the tools and processes in place to resolve them as they happen. In this post, we’ll share how Niklas Gustavsson, Principal Engineer at Spotify, encountered live (in production, and accessible to end users) but unplayable content after what should have been a routine change, as well as lessons learned and Niklas’ favorite debugging tool.

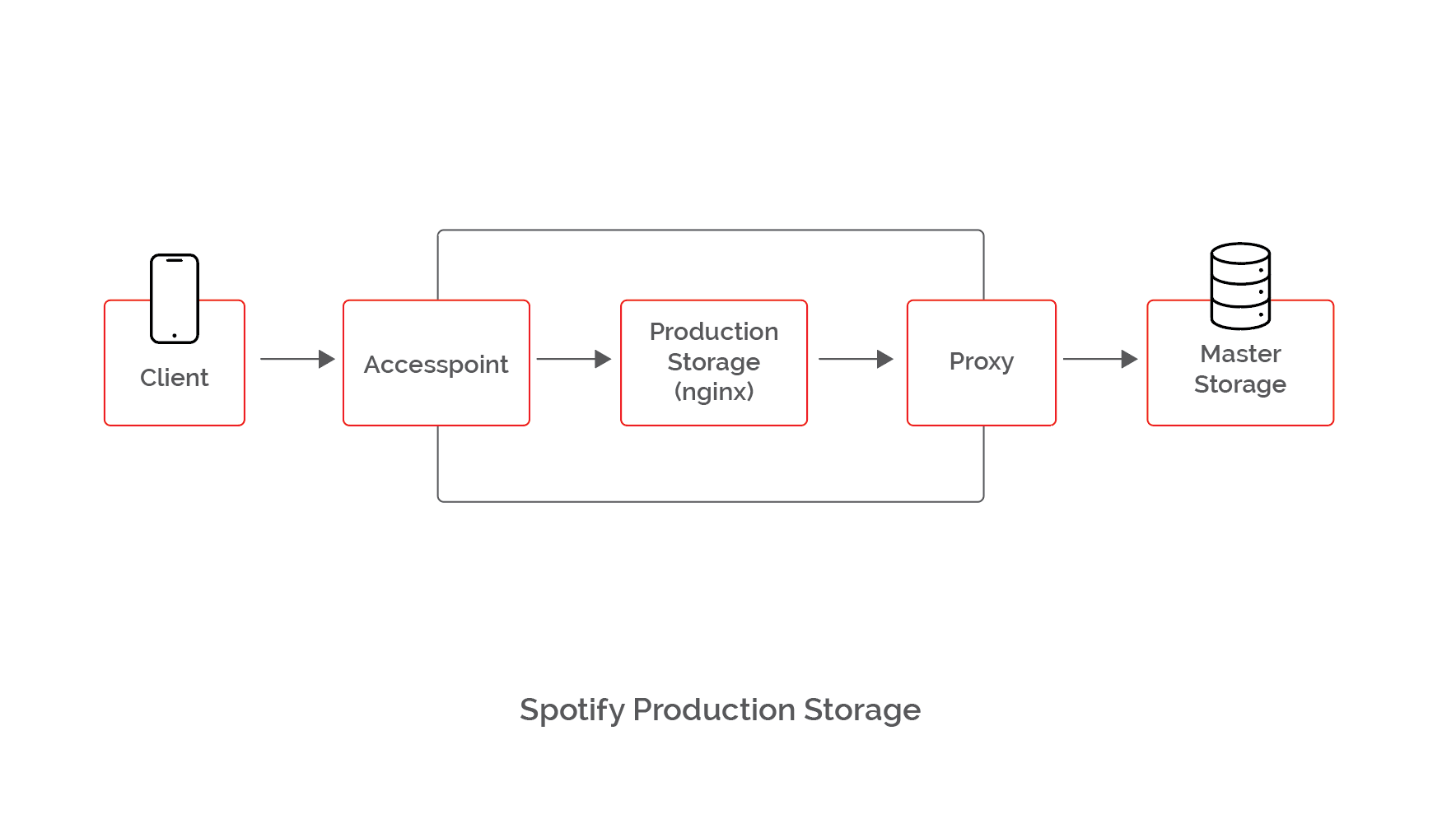
Spotify distributes audio content for legacy systems (i.e., users on older Spotify clients) using a slightly customized nginx, dubbed “production storage.” It works like this: a client talks to an access point (a perimeter service that manages authentication and does content routing), which in turn talks to production storage, which talks to a proxy which talks to master storage (AKA, the origin for all their audio files).
This year, backend storage was moved to Google Cloud Storage (GCS), including all of their audio files. After moving many petabytes of data to GCS, they made the switch to GCS as their origin by redirecting the proxy. This should have been an easy thing to do, since Google offers the same APIs as S3, their previous solution.
Although they’d tested these new systems, after switching over they received reports from Australia and New Zealand that there was new — but unplayable — content on their service. Understandably, artists and labels “get nervous” when there’s new content that can’t be played. After creating an incident report to track the issue, Niklas turned to his “favorite debugging tool of all” — ngrep, which exposes the raw network traffic flowing in and out of the server, capturing any traffic in real time that matches a specific pattern, like regular grep does for files on your local system.
ngrep helped uncover the fact that responses from GCS were missing the Accept-Ranges: bytes response header, and although the requests made to GCS were not using ranges, this was the only difference between GCS and S3, therefore warranting further investigation.
Even though nginix makes no range requests to GCS, Spotify client apps and the access point between the clients and nginix both do. By default, the way ngnix knows that it can respond to range requests is by confirming that the cached object has the Accept-Ranges response header. Since the header was now missing, nginix would respond to range requests with an HTTP status code 200 and the entire requested object, rather than an HTTP status code 206 and partial content for the requested range. This is an allowed and fully compliant behavior, but an nginx response that was different than before, which triggered problems downstream.
It turned out that responding with the full music file exposed two bugs downstream. The access point wasn't built to deal with non-partial responses and would send a response to the client with bad Content-Length. The client app was not able to cope with the bad Content-Length, which ultimately led to the inability to play tracks.
Fortunately, the team was able to resolve the issues by configuring nginx to force it to honor range requests and respond with partial content (as it did before), even if it received the content from upstream without an Accept-Ranges header. By looking at the cached files in nginx, they could inspect which ones were missing the response header and purge them from the system.
Going back up the chain
After this incident, Niklas and his team went through the other parts of their chain to make sure everything was fixed. Reconfiguring nginx removed the dependency on the Accept-Ranges header, but as an extra measure — since GCS doesn’t support setting the header by default — the proxy between nginx and GCS was configured to always add the header anyway.
The access point bug was also fixed, allowing it to handle full responses to range requests properly. And although this would mean that the access point will no longer respond to the client with bad content length, they’re in the process of fixing the client as well, so it can actually handle these types of exceptional errors in the future. (In the event of failure, letting them do so “gracefully, instead of failing in a brutal way.”)
Stay tuned — we’ll continue to share war stories in the months ahead.

