
Altitude NYC, the East coast edition of our annual customer summit, brought together customers, Fastly engineers, and industry leaders to tackle complex problems in security, cloud infrastructure, DevOps, and more. In this post, we’ll recap The New York Times CTO Nick Rockwell’s talk, in which he gave us a peek inside the company’s stack and culture, and described how they prepare for major events — such as the 2016 presidential election.
Failure & risk at The New York Times
The New York Times team is comprised of smart, passionate individuals — “everyone is very motivated around the mission.” When Nick came on board, he deemed the visible parts of the product (nytimes.com and its mobile application) to be in great shape, but he saw room for improvement in the underlying infrastructure. They did not have a CDN in place, and were hosting their content in four data centers, a “jumbled mess” of AWS services, three generations of web frameworks “lying around,” and “a whole slew of” unutilized foundational tech, such as languages and databases. Nick ultimately determined that the root cause of redundant infrastructure was risk aversion, “manifested as an unwillingness to take on projects that weren’t forced upon us by somebody else.”
To tackle this dilemma, Nick sought to redefine risk in a corporate and technical context. According to Nick, today’s corporate culture is obsessed with risk, but current ideologies of risk taking and accountability are at odds. By insisting on accountability, you concentrate risk in one spot — you’re setting up a single point of failure, an inherently bad design principle. Accountability in its current state relies on a rigid and mechanical process to determine success (e.g., “If you don’t hit this KPI, you fail.”). The difference between success and failure is not a clear-cut issue. With real risk taking, there isn’t perfect clarity between the two — “Risk taking can only occur within the space of the unknown” — and failure can be a positive outcome. It’s on an organization’s leadership to highlight these distinctions, and set the tone for “good risk taking,” which is calculated, distributed, and hedged.
Updating The New York Times’ stack
As part of his effort to redefine how risk is perceived and mitigated at The New York Times, Nick made several changes to their technical infrastructure, such as consolidating their data centers and doing away with tech they weren’t using. They also integrated Fastly’s CDN, which allowed them the “obvious joys” of scaled caching, better performance, and DDoS protection, while also providing “less obvious” benefits, including:
Consistent performance: Nick’s team now “spends less time chasing down aberrations or regional problems”
“Better everything:” TLS negotiation, compression — “every single part of the client interaction works better”
Scale, or “the cascading effects of smaller, simpler infrastructure” that help eliminate a proliferation of interacting pieces that makes scaling a challenge
Another benefit is dealing with traffic spikes. When breaking news hits, The New York Times sends as many as 20-30 million push alerts in a single minute. Because news spikes are too short-lived to merit autoscaling to the cloud (and too unpredictable to be ready with redundant servers beforehand), they use Fastly’s CDN for their alerts API to “mirror those alerts and take load off the central systems,” which saves them $25,000 per month.
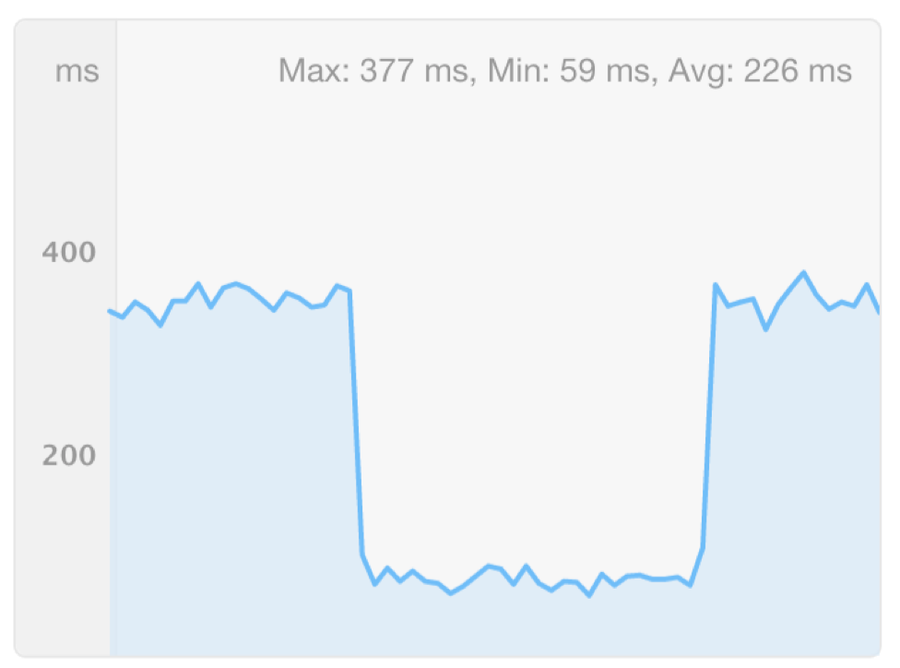
According to Nick, “everything gets better” when you have an effective caching strategy in place — especially for very concentrated, content-oriented sites like nytimes.com. Using various performance monitoring tools, Nick tested how Fastly’s CDN performed; you can see the moment at which he started and stopped the test — “the beautiful chalice of user experience” — in the following graphs:
US homepage performance
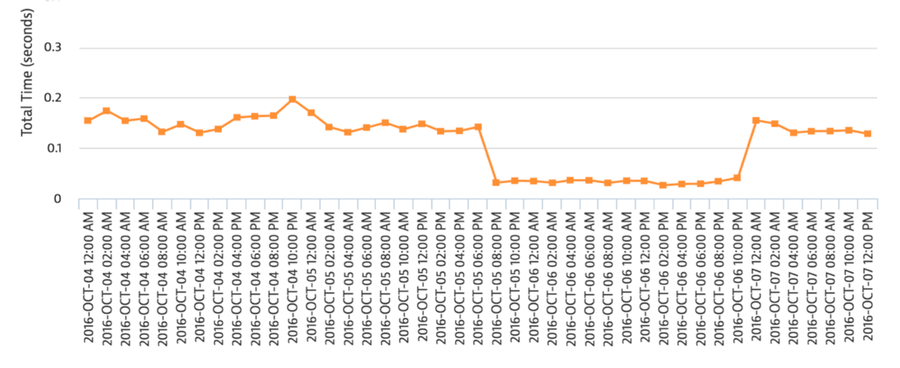
Source: Keynote
EU homepage performance
Source: Pingdom
TLS negotiation time (“lower is better”)

Source: Catchpoint
Turning to Fastly’s CDN also played a huge role in how The New York Times prepared for the 2016 presidential election.
Election night at The New York Times
A presidential election is often the biggest the night for a news organization, which is why Nick found it surprising that The New York Times wasn’t well-prepared from a technology standpoint. This was compounded by the fact that they had gone down on election night in 2012 (before Nick’s time): they didn’t even know what the high-water mark of inbound traffic looked like. In order to rally the team around the upcoming election, Nick had them focus on the failures from last time; he conducted a “pre-post-mortem” to define what failure would look like, as well as approaches for addressing and mitigating it. They realized that responsibility was too diffused across the team, and they didn’t have a coordinated plan for handling likely failure scenarios. They worked to put a plan in place, make responsibilities clear, and integrate a CDN, while using the debates leading up to the election as practice runs. They also had a plan b for the election — you can check out the details in his presentation slides.
Their timeline to prep was tight, due in part to the 2016 Summer Olympics closing at the end of August:
8/21 Olympics wrap
8/24 first election prep meeting
9/21 meet with Fastly
9/23 commit to using Fastly
10/25 in production
11/5 agreement signed
11/8 election night
Although Nick acknowledged it was “fairly insane” to switch (and fully integrate) CDNs six weeks before the election — not to mention going to production just two weeks before — they needed Fastly’s instant invalidation, and “didn’t want to deal with the configuration or support nightmares of its incumbent.”
The New York Times has a long-standing policy of turning off their paywall on election night; that, coupled with the momentousness of the event, encouraged them to prepare for a high-traffic evening. Nick’s team set up war rooms to monitor site health and traffic patterns. As the evening wore on, traffic to nytimes.com started to build; Nick noted that Chartbeat recorded 2,002,872 concurrent visitors, with 100,000 requests per second to the election map alone. At Fastly, we observed that their traffic climbed up to 8,371% higher than the same time the previous week as readers rushed to engage with the final results.

From The New York Times’ view in the Fastly control panel, you can see the cache hit ratio mimicked the spike (showing that traffic was hitting Fastly’s cache, and sparing their origin):
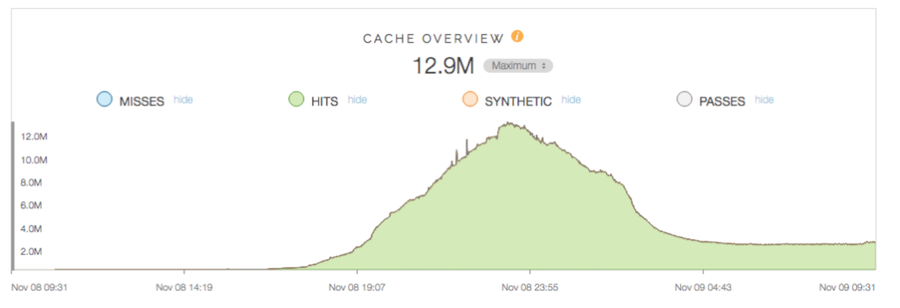
And that their origin performance actually improved — behaving more predictably and with more stability — during the peak:
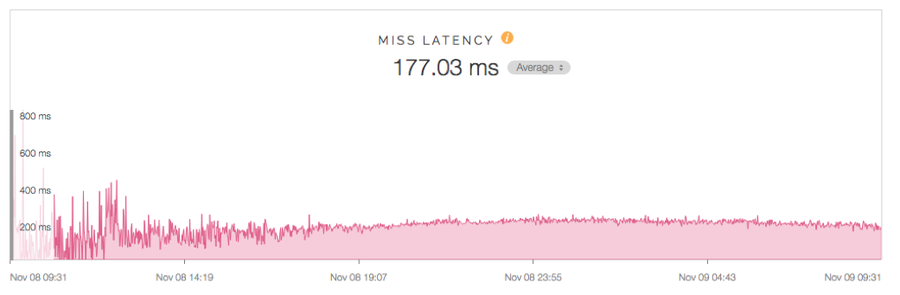
As Nick noted, even with very short time to live values (TTLs), “the edge can have an enormous impact” on origin performance.
What’s next?
Going forward, The New York Times will continue shrinking provisioning and putting Fastly in front of its primary API; replace downstream caching (previously they’d put caches between different sources); leverage BigQuery for log streaming; and further explore the edge processing opportunities referenced in Fastly CEO Artur Bergman’s Altitude NYC keynote — including load balancing, WAF, and image optimization.
Check out the video below to see Nick’s full presentation (including an excellent anecdote from his MTV days). West Coast customers: join us June 28-29 for Altitude in San Francisco — we’ll have a full day of hands-on trainings on 6/28, followed by our customer summit on 6/29, where we’ll hear from industry leaders like the ACLU and Slack, and explore the future of edge delivery, infrastructure, and enforcement.