
El registro de errores de red (NEL) puede ofrecer información valiosa sobre los problemas de red que podrían tener los usuarios al conectarse a tu sitio web. Al ser una especificación de W3C compatible con algunos navegadores, puede ser una herramienta muy útil para detectar y notificar errores. De hecho, hemos probado NEL con Fastly Insights y hemos descubierto que el procesamiento de informes de NEL es un excelente caso de uso de Compute, el nuevo entorno informático sin servidores de Fastly. Compute nos permite analizar y enriquecer los datos de forma eficiente. Luego, podemos volver a serializar el JSON antes de enviar el informe resultante a un punto de conexión de registro de terceros, como BigQuery, prescindiendo de las canalizaciones de procesamiento más complejas y propensas a errores que se solían usar para solucionar este problema.
Llevamos un tiempo hablando de Compute, el entorno sin servidores más seguro, eficiente y escalable, que te permite cargar y desplegar lógica compleja en el edge. Pues bien, ahora vamos a mostrar por primera vez cómo usamos Compute para solucionar un problema interno. En esta entrada veremos cómo creamos una canalización de informes de NEL, analizaremos las áreas que podían optimizarse y, por último, explicaremos la forma en que Compute ayudó a solucionar estos problemas mejorando, de paso, el rendimiento y la seguridad.
La típica canalización de informes
En teoría, solo hay unos pocos requisitos para crear un punto de conexión de informes de NEL:
Responder a peticiones OPTIONS con una respuesta 204 No Content y los encabezados CORS adecuados para cumplir con los requisitos de seguridad previos.
Responder a las peticiones POST portadoras de informes con una respuesta HTTP 204 No Content.
Recopilar informes, agregarles los metadatos necesarios y registrarlos en una canalización de análisis.
Convertir los datos registrados en un formato que pueda usarse en los análisis y conservarlos en una base de datos.
Los informes de NEL llegan desde un navegador como cargas útiles del cuerpo de POST en formato JSON. Aunque pueden analizarse tal y como llegan, Fastly tiene mucha más información sobre la petición, así que capturamos los metadatos disponibles en el edge para añadir contexto a cada uno de los informes. En este ejemplo, vamos a añadir a cada informe información de geolocalización mediante la IP y una marca de tiempo, y luego usaremos los registros en tiempo real de Fastly para registrarlos.
Por si fuera poco, los navegadores pueden — y según hemos observado podrán— procesar varios informes de errores de NEL por lotes y enviarlos todos juntos en una única petición POST, probablemente para aprovechar mejor sus recursos. Eso significa que el cuerpo de POST de cada petición puede incluir uno o varios informes, enviados en forma de matriz de objetos de informe JSON.
Analizar y crear objetos JSON complejos en el edge no es tarea fácil, y lo que hicimos fue crear un nuevo objeto JSON que sirviera como envoltorio, especificar los metadatos como propiedades individuales del objeto, añadir la matriz de informes como otra propiedad del objeto y registrar el objeto de envoltorio con formato JSON delimitado por nuevas líneas en un punto de conexión de almacenamiento (en este caso, Google Cloud Storage).
En ese momento, los registros sin procesar no son del todo útiles para realizar análisis, puesto que cada fila podría contener varios informes y preferimos que cada informe ocupe una sola fila en la base de datos. Para solucionarlo, desplegamos un patrón de canalización común de extracción, transformación y carga (ETL) mediante la solución Cloud Functions de Google para procesar los registros, analizar los informes uno a uno, combinarlos con los metadatos e insertarlos en filas independientes en BigQuery. Este diagrama representa todo el flujo de principio a fin:

Lo que creamos era funcional, e incluso podíamos usarlo en producción, pero vimos que podía mejorarse. Por ejemplo, si podíamos analizar los informes en el edge, crear objetos JSON individuales para cada informe (añadiéndole los metadatos adicionales proporcionados por Fastly) y registrar el resultado directamente en BigQuery desde el edge, reduciríamos el número de pasos del proceso y crearíamos una canalización de recopilación, registro y análisis más eficiente que podríamos ampliar fácilmente con posterioridad.
Esa es precisamente la clase de herramientas que nos ofrece Compute, y eso fue lo que más nos motivó a migrar la canalización actual a la nueva plataforma.
Recopilar informes de NEL con Compute
Compute es independiente del lenguaje y nos permite programar en el edge con los lenguajes que dominamos, como Rust. Rust ofrece compatibilidad nativa con tareas como el análisis de JSON en estructuras de datos con establecimiento inflexible de tipos, además de una potente capacidad de comprobación de coincidencia de patrones. Estas funcionalidades nos permiten crear y desplegar un punto de conexión de recopilación a medida que extrae, transforma y registra los informes en BigQuery, por lo que muchos de los componentes de nuestra iteración anterior ya no son necesarios. Ahora echemos un vistazo a parte de la lógica principal para ver cómo lo conseguimos (si lo prefieres, puedes ver toda la aplicación en GitHub):
Enrutamiento
Como la mayoría de las plataformas sin servidores, los programas de Compute tienen un punto de entrada que consiste en una función única que acepta una petición y devuelve una respuesta. Por eso, primero tenemos que definir la función de punto de entrada de nuestro programa, que contendrá la lógica de enrutamiento HTTP. Por suerte, la sintaxis de comprobación de coincidencia de patrones de Rust nos permite contrastarla fácilmente con la estructura y los valores de tipos como la petición entrante, de modo que podemos definir que se ejecute esto si se trata de una petición POST o esto otro si no lo es.
#[fastly::main]
fn main(req: Request<Body>) -> Result<Response<Body>, Error> {
// Pattern match on the request method and path.
match (req.method(), req.uri().path()) {
// If a CORS preflight OPTIONS request, return a 204 no content.
(&Method::OPTIONS, "/report") => generate_no_content_response(),
// If a POST request pass to the `handler_reports` request handler.
(&Method::POST, "/report") => handle_reports(req),
// For all other requests return a 404 not found.
_ => Ok(Response::builder()
.status(StatusCode::NOT_FOUND)
.body(Body::from("Not found"))?),
}
}En este ejemplo, lo contrastamos con el método y la ruta de URL de la petición. Si se trata de una petición OPTIONS a la ruta del informe, devolvemos de inmediato una respuesta 204; si se trata de una petición POST a la misma ruta, la pasamos a una función handle_reports; en cualquier otro caso, devolvemos una respuesta 404 Not Found.
Análisis de JSON
El principal objetivo de la CloudFunction de nuestra canalización anterior era analizar JSON, extraer cada uno de los informes, transcluir los metadatos globales e insertar los informes en filas individuales de la base de datos. Una de las ventajas clave de Compute es que nos permite aprovechar el amplio y maduro ecosistema de módulos diseñados para solucionar estos problemas con seguridad y eficacia, como la increíble caja de Rust serde_json.
Con Serde, podemos leer el flujo de datos del cuerpo de la petición y analizarlo como JSON en una estructura de datos Rust con establecimiento inflexible de tipos que hayamos predefinido. Como NEL es una especificación de W3C, la carga útil de POST es también una estructura predefinida a la que deben ajustarse todos los agentes de usuario. Esto tiene una consecuencia positiva, y es que Serde descartará los informes mal formados o maliciosos que se envíen a nuestro punto de conexión, ya que no se ajustarán a la especificación. Tampoco tendremos que realizar ningún procesamiento posterior para limpiar los datos en BigQuery antes de usarlos. ¡Todo son ventajas!
/// `Report` models a Network Error Log report.
#[derive(Serialize, Deserialize, Clone)]
pub struct Report {
pub user_agent: String,
pub url: String,
#[serde(rename = "type")]
pub report_type: String,
pub body: ReportBody,
pub age: i64,
}
// Parse the NEL reports from the request JSON body using serde_json.
// If successful, bind the reports to the `reports` variable, transform and log.
if let Ok(reports) = serde_json::from_reader::<Body, Vec<Report>>(body) {
// Processing logic...
}Transformación y registro
Ahora que tenemos acceso a una lista de informes de NEL estructurados enviados desde el cliente, podemos agregarles metadatos de IP de geolocalización antes de registrarlos definitivamente en nuestro punto de conexión de BigQuery. Aquí es precisamente donde salen a relucir todas las bondades de usar un entorno de programación flexible en el edge.
Primero modelamos los metadatos en forma de estructura ClientData e implementamos su método constructor, que acepta una cadena de IP y de agente de usuario. El constructor hace unas cuantas cosas dignas de mención:
En primer lugar, trunca la dirección IP del cliente y la convierte en un prefijo seguro que garantice la privacidad, ya que no nos hace falta guardar la IP completa en nuestra base de datos.
Luego llama a la función geo_lookup desde el módulo fastly::geo importado, que devuelve los datos geográficos asociados a una determinada dirección IP, como el código de país y el nombre del sistema autónomo.
Por último, analiza la cadena de agente de usuario y la normaliza, convirtiéndola en una cadena con información de la versión (family, major, minor o patch). Como pasaba con la IP, no necesitamos toda la información y nos basta con estos datos.
use fastly::geo::{geo_lookup, Continent};
/// `ClientData` models information about a client.
///
/// Models information about a client which sent the NEL report request, such as
/// geo IP data and User Agent.
#[derive(Serialize, Deserialize, Clone)]
pub struct ClientData {
client_ip: String,
client_user_agent: String,
client_asn: u32,
client_asname: String,
client_city: String,
client_country_code: String,
client_continent_code: Continent,
client_latitude: f64,
client_longitude: f64,
}
impl ClientData {
/// Returns a `ClientData` using information from the downstream request.
pub fn new(client_ip: IpAddr, client_user_agent: &str) -> Result<ClientData, Error> {
// First, truncate the IP to a privacy safe prefix.
let truncated_ip = truncate_ip_to_prefix(client_ip)?;
// Lookup the geo IP data from the client IP. If no match return an
// error.
match geo_lookup(client_ip) {
Some(geo) => Ok(ClientData {
client_ip: truncated_ip,
client_user_agent: UserAgent::from_str(client_user_agent)?.to_string(), // Parse the User-Agent string to family, major, minor, patch.
client_asn: geo.as_number(),
client_asname: geo.as_name().to_string(),
client_city: geo.city().to_string(),
client_country_code: geo.country_code().to_string(),
client_latitude: geo.latitude(),
client_longitude: geo.longitude(),
client_continent_code: geo.continent(),
}),
None => Err(anyhow!("Unable to lookup geo IP data")),
}
}
}Ahora que ya tenemos nuestra implementación de metadatos, podemos crear una nueva instancia y generar la lista de informes que queremos registrar. Para ello, asignamos cada uno de los informes analizados y creamos así nuestro propio envoltorio LogLine, que combina el cuerpo del informe y los metadatos del cliente en un solo objeto con una marca de tiempo de recepción. Con NEL solo queremos agregar los metadatos que ya existen en el edge, pero si quisiéramos hacer algo más complicado, como recuperar más datos de un servicio de origen, tendríamos que hacer lo siguiente:
// Construct a new `ClientData` structure from the IP and User Agent.
let client_data = ClientData::new(client_ip, client_user_agent)?;
// Generate a list of reports to be logged by mapping over each raw NEL
// report, merging it with the `ClientData` from above and transform it
// to a `LogLine`.
let logs: Vec<LogLine> = reports
.into_iter()
.map(|report| LogLine::new(report, client_data.clone()))
.filter_map(Result::ok)
.collect();Por último, iteramos a través de la lista de registros, serializamos cada uno de ellos para volver a convertirlos a formato JSON mediante Serde y enviamos la línea a nuestro punto de conexión de registro de BigQuery. Con un par de líneas de Rust nos olvidamos del todo de la canalización de ETL. ¿No es genial?
// Create a handle to the upstream logging endpoint that we want to emit
// the reports too.
let mut endpoint = Endpoint::from_name("reports");
// Loop over each log line serializing it back to JSON and write it to
// the logging endpoint.
for log in logs.iter() {
if let Ok(json) = serde_json::to_string(&log) {
// Log to BigQuery by writing the JSON string to our endpoint.
writeln!(endpoint, "{}", json)?;
}
}Esta es una muestra del resultado del procesamiento del programa, un objeto JSON bien estructurado que coincide con nuestro esquema de BigQuery:
{
"timestamp": 1597148043,
"client": {
"client_ip": "",
"client_user_agent": "Chrome 84.0.4147",
"client_asn": 5089,
"client_asname": "virgin media limited",
"client_city": "haringey",
"client_country_code": "GB",
"client_continent_code": "EU",
"client_latitude": 51.570,
"client_longitude": -0.120
},
"report": {
"url": "https://www.fastly-insights.com/",
"type": "network-error",
"body": {
"type": "abandoned",
"status_code": "0",
"server_ip": "",
"method": "GET",
"protocol": "http/1.1",
"sampling_fraction": "1",
"phase": "application",
"elapsed_time": "27"
},
"age": "34879"
}
}Bueno, pues ya tenemos toda la información que necesitamos: el tipo de error de red que se ha producido, la red afectada, el tipo de agente de usuario que ha generado el informe y una pista de dónde ha ocurrido todo. Tenemos datos suficientes para generar sistemas de alertas y paneles en tiempo real que nos ayudarán a entender qué problemas tienen los clientes para acceder a nuestra red y dónde se producen.
Menos complejidad, y más velocidad y seguridad
Al migrar nuestra canalización de informes de NEL a Compute, pudimos eliminar dos partes móviles del sistema (el cubo de almacenamiento temporal y la CloudFunction), lo que nos permitió reducir la sobrecarga operativa y los costes generales del sistema. No está nada mal.
Sin embargo, creo que en lo que más ganamos fue en rendimiento, seguridad e integridad de los datos:
Ahora los informes aparecen en BigQuery a los pocos segundos de haberlos recibido. Ya no hay que esperar varios minutos, lo que supone una vuelta al registro en tiempo real que se espera de Fastly.
Como usamos un sistema de tipos seguros en Rust para el análisis de JSON, solo registramos los informes válidos. Ya no es necesario realizar ningún procesamiento posterior porque una sola base de código nos permite desplegar fácilmente cambios en el esquema en lugar de tener que hacerlo de forma sincronizada.
El diagrama de la arquitectura de nuestra nueva canalización es mucho más sencillo que antes:
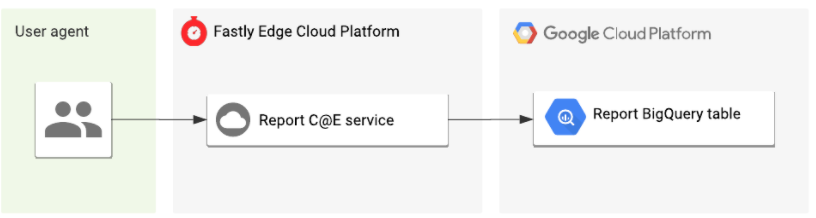
Esto no es más que un ejemplo de cómo estamos aprovechando la plataforma de forma interna en Fastly, y estoy deseando poder daros muchos más ejemplos en el futuro.
¿Por qué no lo pruebas?
Si te han quedado dudas, puedes ver el código de la aplicación completa en todo su esplendor en GitHub. Si eres uno de los clientes beta de Compute, lo tienes todavía más fácil: puedes usar nuestro kit de inicio de NEL para empezar un nuevo proyecto con un solo comando CLI:
$ fastly compute init --from https://github.com/fastly/fastly-template-rust-nel.gitY si todavía no eres uno de nuestros clientes beta, puedes registrarte hoy mismo. Estamos deseando que nuestros clientes empiecen a descubrir el verdadero potencial de la plataforma y nos cuenten más casos de uso, así que nos encantará saber cómo te ha ido. ¡Venga, anímate a usar la plataforma y a hacer cosas increíbles!