

En 2020, surgió una idea: ¿podríamos hacer que la limpieza de peticiones de Varnish fuera más inteligente borrando solo la memoria realmente utilizada, en lugar de borrar siempre todo el bloque? La teoría era que menos escrituras en la memoria significaban menos ciclos desperdiciados y, a la escala de Fastly, eso se traduce en un aumento significativo del rendimiento.
Pero había un problema. Pero había un problema. Si había algún error en la contabilidad, aunque fuera mínimo, se podían filtrar datos de una petición a otra. Este es un riesgo que ningún desarrollador quiere correr. La idea quedó en suspenso hasta que encontramos una forma de demostrar que era segura. En este blog explicaremos cómo lo hicimos.
A la antigua usanza: borrar siempre 512 KB
Cada petición entrante en Varnish recibe un espacio de trabajo de 512 KB, dividido en dos regiones de 256 KB (una para gestionar la petición que llega a Varnish y otra para cualquier petición al backend del origen). Esto es esencialmente un espacio de trabajo para datos temporales por petición. Al final de la petición, Varnish limpiaba toda la región, independientemente de cuánto se hubiera utilizado.
Era simple, seguro, pero caro. Tanto si una petición utilizaba 10 KB como 500 KB, Varnish seguía borrando medio megabyte. A nuestros niveles de tráfico, eso significaba una montaña de operaciones de memoria innecesarias.
La idea latente: limpieza de marca de agua alta
La optimización consistía en hacer un seguimiento de la marca de agua alta, que es el punto más lejano del espacio de trabajo tocado durante una petición.
Si la petición solo utilizara 20 KB, borraríamos 20 KB, no los 512 completos. Pero si el seguimiento estaba desactivado, los bytes no borrados podrían persistir. Eso es una fuga de datos inminente.
El avance decisivo: céntrate en el verdadero cuello de botella
En una reciente cumbre sobre eficiencia, uno de nuestros ingenieros del equipo H2O creó un modelo de rendimiento de todo el sistema. Los resultados mostraron que en algunas máquinas AMD, el tráfico de memoria (y no los ciclos de CPU) era el verdadero cuello de botella. Eso cambió la balanza: de repente, la eliminación de marcas de agua altas no era solo una buena idea, sino algo que valía la pena poner en práctica. El reto era garantizar que fuera seguro.
Hacerlo seguro
Lo difícil no era escribir el código, sino demostrar que la marca de agua era siempre precisa. Si simplemente confiábamos en el seguimiento, un byte perdido podría filtrar datos entre peticiones. Pero verificar cada petición habría eliminado las ganancias de rendimiento.
El avance consistió en utilizar algo que ya teníamos: comprobaciones de integridad del espacio de trabajo que se ejecutan después de la mayoría de las operaciones del espacio de trabajo. Enganchándonos a ellas y añadiendo un muestreo aleatorio, podíamos validar la corrección sin añadir una sobrecarga constante ni aumentar innecesariamente el tráfico de memoria de Varnish. El razonamiento era sencillo: una sola máquina muestreando 1 de cada 20 000 operaciones no detectaría mucho, pero a través de miles de máquinas, eso supone más de un millón de comprobaciones por segundo. Eso es mucho para generar confianza a escala.
Implementamos la limpieza de marcas de agua en modo sombra:
Sigue borrando todo: cada petición continuaba borrando los 512 KB completos.
Realiza un seguimiento del uso de todos modos: cada petición también rastreó su marca de agua alta como si la optimización estuviera activa.
Ejemplos de comprobaciones: se auditó alrededor de 1 de cada 20 000 operaciones de espacio de trabajo; todo lo que había pasado la marca de agua se volvió a leer para confirmar que no se había utilizado.
Para mantener bajos los gastos generales:
Reutilizamos las comprobaciones de integridad del espacio de trabajo existentes.
Estructuramos el bucle de verificación para la vectorización SIMD, permitiendo que la CPU procesara varios bytes por instrucción.
Inspeccionamos el código de máquina generado para confirmar que el compilador emitía instrucciones vectorizadas, no un bucle escalar lento.
Tras recorrer toda la flota de esta manera, teníamos la confianza estadística necesaria para confiar en el seguimiento de la introducción de marca de agua. Solo entonces habilitamos la optimización de verdad.
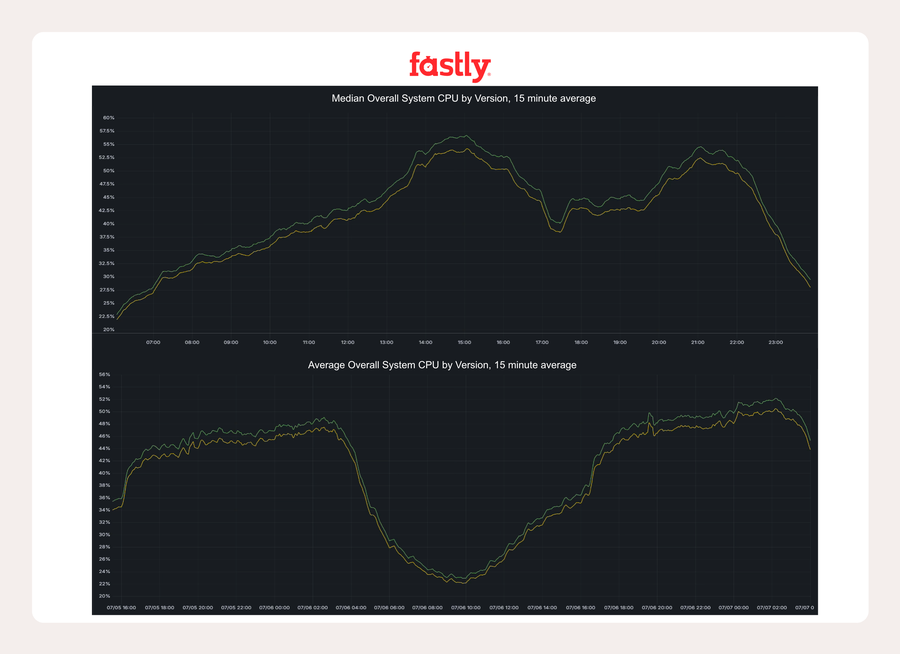
Despliegue y resultados
Seguimos nuestro habitual despliegue conservador, priorizando la seguridad, comenzando con un canario en algunos hosts de producción antes de expandirnos por toda la flota. Los resultados fueron significativos:
En Marsella, los hosts que ejecutan el modo de introducir marca de agua escribieron aproximadamente 10 GB/s menos en la memoria, una reducción del 25 % en las escrituras de memoria en comparación con el borrado completo. En las máquinas AMD, esto fue suficiente para eliminar el ancho de banda de la memoria como cuello de botella, desbloqueando ganancias de eficiencia en toda la pila.
En un POP europeo muy concurrido, el uso de la CPU del sistema se redujo en más de 2 puntos porcentuales en el pico.
En el KCGS720, que forma parte del POP metropolitano crítico de la IAD, la reducción fue de unos 1,5 puntos porcentuales.
En las máquinas Intel, no teníamos problemas de ancho de banda de memoria, así que el uso general del sistema no cambió tanto, pero las métricas específicas de Varnish siguieron mejorando.
Los efectos dominó fueron sorprendentes: al reducir el tráfico de memoria de Varnish, las instrucciones por ciclo (IPC) de H2O mejoraron, a pesar de que no hubo cambios en H2O. Cuando liberas ancho de banda de memoria, les das a otros procesos más espacio para respirar.
Lecciones para desarrolladores
La seguridad es lo primero: una optimización que corre el riesgo de filtrar datos es peor que inútil.
Ten paciencia a escala: tomar muestras de millones de operaciones por segundo nos dio confianza, no conjeturas.
Mide lo correcto: el ancho de banda de la memoria, no la CPU, fue el verdadero limitador aquí.
Crea sobre lo que tienes: reutilizar las comprobaciones de integridad reduce la complejidad.
Optimiza la optimización: los controles vectorizados hicieron que la seguridad fuera asequible.
Espera efectos en todo el sistema: corregir un cuello de botella puede dar ventaja al código no relacionado.
Revisa el código antiguo: las ideas archivadas hace años pueden ser viables con nuevos conocimientos.
Cuidado con las interfaces: gran parte de los problemas de depuración residían en las costuras entre sistemas.
Para los desarrolladores, la conclusión es la siguiente: no te limites a perseguir los números de CPU obvios. Comprende dónde está realmente obstruido tu sistema, demuestra la seguridad a escala y podrás conseguir mejoras de eficiencia sin sacrificar la corrección.
Haz que tu código sea más rápido y ágil sin sacrificar la seguridad. Empieza hoy mismo con una cuenta gratuita de desarrollador de Fastly.