

En Fastly, nos encanta decir «almacenar en caché es el rey» (primero porque lo es y, segundo, porque todos somos grandes fanáticos de la eficiencia) Nos encanta la eficiencia de almacenar en caché. El almacenamiento en caché eficiente puede aportar grandes mejoras en el rendimiento, la seguridad, la resiliencia y el ahorro de costes... la lista sigue. Cuanto menos necesiten ser contactados tus servidores de origen, mejor. Y eso importa mucho a los usuarios que visitan tu sitio web o aplicación: debe ser instantáneo, ágil y eficiente, lo que significa que gestionar la carga en tus servidores es una prioridad.
¿Qué es la reducción de peticiones a una sola?
Uno de los «superpoderes» de nuestra plataforma que contribuye a la eficiencia es la reducción de peticiones a una sola, la práctica de combinar múltiples peticiones simultáneas para el mismo objeto en una sola petición al origen y luego usar la respuesta resultante para satisfacer todas las peticiones pendientes. Para entender mejor lo que esto logra, analicemos más a fondo una respuesta básica almacenada en caché:

Fácil y eficiente, ¿no? Pero cada paso de este proceso necesitará tiempo, así que vamos a examinarlo aún más detenidamente:

¡Hasta ahora, todo bien! Pero, ¿qué pasa cuando una oleada de usuarios quiere lo mismo al mismo tiempo, pero no hemos podido obtenerlo de tu origen? Esto ocurre todo el tiempo durante las transmisiones de vídeo en vivo o los lanzamientos de nuevos juegos. Ahí es donde ocurre la reducción de peticiones a una sola. La arquitectura y la plataforma de caché de Fastly nos permiten usar la misma respuesta de origen para servir las peticiones que llegaron después de que comenzamos a recuperarla. Esto significa que todas esas peticiones reciben la respuesta más reciente posible sin recuperaciones adicionales desde el origen. Los usuarios reciben contenido actualizado (y tienen una buena experiencia), tu origen está protegido y, lo mejor de todo, es muy eficiente.
¿Cuándo puede ocurrir la reducción de peticiones a una sola?
En nuestro ejemplo anterior, vimos cómo la reducción de peticiones a una sola es un poderoso subconjunto del comportamiento de almacenamiento en caché de Fastly. Siempre está activado por defecto, y no tienes que hacer nada especial para sacar Ventaja de ello. Dicho esto, es un comportamiento situacional que requiere que ciertas cosas ocurran en plazos muy cortos, y no todos los flujos de trabajo de los clientes pueden obtener ventaja de ello.
En primer lugar, las peticiones deben ser interactivas de almacenar en caché, lo que significa que producirán un objeto de almacenar en caché que las peticiones posteriores pueden utilizar. Las peticiones PASS y muchos errores no se pueden almacenar en caché por defecto, lo que significa que nunca podremos reducir con éxito esas peticiones. Si no podemos almacenar en caché, no podremos colapsar las peticiones en la respuesta.
En segundo lugar, para colapsar las peticiones, deben ser concurrentes con la petición que inició la recuperación desde el origen. Esto significa que recibimos la petición mientras ya la estamos obteniendo para satisfacer una petición anterior. Una vez que se completa esa respuesta, el comportamiento normal de almacenamiento en caché toma el control y el colapso se detiene. Esto ocurre más comúnmente en los objetos de almacenar en caché que cambian con frecuencia y son muy solicitados, por lo que muchos usuarios los quieren al mismo tiempo y tenemos que buscarlos del origen con frecuencia.
La concurrencia se incrementará mediante características como el clúster y la protección. Ambos concentran las peticiones dentro de nuestra plataforma para mejorar la eficiencia y el rendimiento. También puedes observar una mayor frecuencia de reducción de peticiones a una sola cuando un origen tarda más en responder, ya sea porque el objeto es más grande o porque el origen está sobrecargado. Debido a que el período de tiempo en el que estamos esperando la respuesta es más largo, hay más tiempo para que las peticiones colapsen sobre ella.
De manera algo contraintuitiva, los orígenes más rápidos y las características que mejoran el tiempo hasta el primer byte reducirán la frecuencia con la que podemos agrupar las peticiones. Como se explicó anteriormente, solo reduciremos las peticiones mientras esperamos la respuesta de origen. Una vez que la respuesta esté lista para que la usemos, dejamos de colapsar. Habilitar la función de fallo de streaming puede reducir esta ventana significativamente, ya que la función nos permite comenzar a usar el objeto de almacenar en caché tan pronto como recibimos los encabezados de la respuesta de origen.
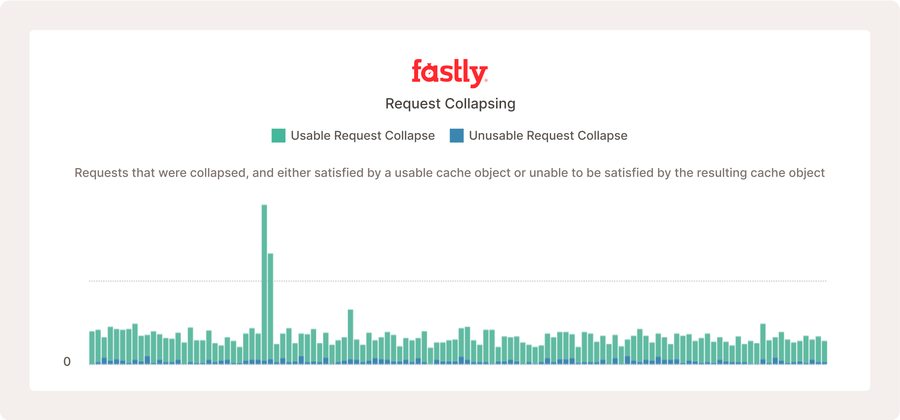
Lo anterior muestra una parte del panel de control de Media Shield para un popular servicio de vídeo en vivo. Se está produciendo la reducción de peticiones a una sola, pero como el origen es rápido y la configuración es tan eficiente, no ocurre con mucha frecuencia en comparación con el número de peticiones que recibe.
Reducción de peticiones a una sola métrica
Ahora que entendemos mejor qué es y qué hace la reducción de peticiones a una sola, exploremos las métricas que querrás vigilar. Estas métricas te ayudarán a entender si está funcionando (¡o no!) y cuán eficazmente está operando.
Hemos introducido dos métricas que están disponibles tanto en tiempo real como en las estadísticas históricas ahora mismo:
request_collapse_usable_countrequest_collapse_unusable_countNuestros clientes pueden encontrar estas métricas a través de nuestras API o puedes usar un panel personalizado para verlas dentro de nuestros paneles de observabilidad y Media Shield. Para entrar en más detalle:
Usable_count: cuenta la frecuencia con la que colapsamos las peticiones y encontramos un objeto de almacenar en caché utilizable. Para que sea utilizable, el objeto debe ser almacenable en caché y tener una vida útil de almacenar en caché positiva. La duración de almacenar en caché es el tiempo de vida (TTL) del objeto menos su antigüedad (cuánto tiempo lo hemos tenido en almacenar en caché). Una vez que la duración de la caché de un objeto ya no es positiva, caduca y ya no es válida para ningún Uso de almacenar en caché, excepto para distribuir información obsoleta. La capacidad de almacenamiento en caché también se rige por la variable beresp.almacenable en caché y se documenta en otro lugar.
Unusable_count: es lo contrario de lo anterior: usable_count. Cuando una respuesta es inutilizable, tenemos que intentar recuperarla nuevamente desde el origen. Por lo general, esto es malo y podría significar que hay un problema de configuración con tu origen, tu service o que tienes un flujo de trabajo que no se puede almacenar en caché y que no se está pasando. (¡Sumando estos dos datos sabrás con qué frecuencia se están reduciendo las peticiones a una sola!)
Comprende las métricas de reducción de peticiones a una sola
¡Casi allí! Disponemos de paneles para comprobar cómo se comporta tu tráfico en nuestra plataforma, y sabes qué buscar, pero también hay muchas cifras nuevas que gestionar... ¿Qué es lo relevante? ¿Qué es lo malo?
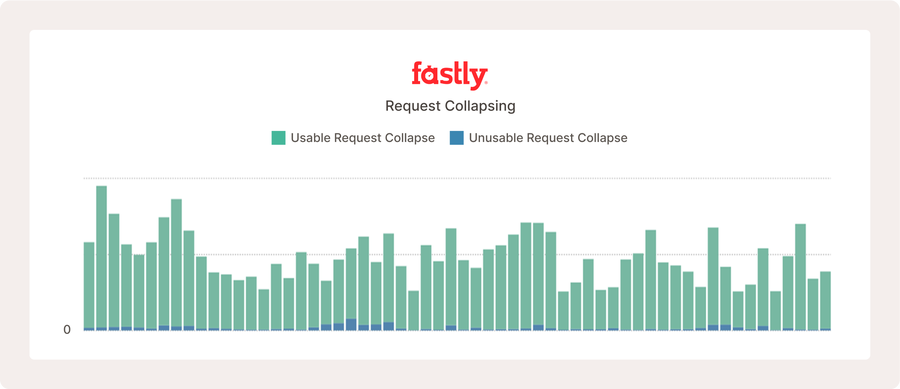
Lo anterior muestra las métricas de reducción de peticiones a una sola para un proyecto de código abierto muy activo, en el que muchos usuarios consultan contenido nuevo con regularidad, lo que aumenta la frecuencia con la que ocurre la reducción de peticiones a una sola.
Para entender qué está funcionando y qué no, primero necesitas tener un conocimiento fundamental de los patrones de tráfico de tus usuarios. Es poco probable que se produzca una reducción de peticiones a una sola si tus peticiones se distribuyen en una gran cantidad de URL que no cambian con mucha frecuencia. Es importante recordar que la mayoría de la reducción de peticiones a una sola ocurre cuando las peticiones llegan dentro del mismo intervalo de 25 a 150 ms. Eso es un muy pequeño margen de tiempo. Ciertos flujos de trabajo son mucho más propensos a experimentar ventajas de la reducción de peticiones a una sola. Es probable que los sitios de noticias, las transmisiones de vídeo en vivo y las descargas de archivos populares experimenten la reducción de peticiones a una sola con mucha más frecuencia. Todo depende de cuántos usuarios hagan la misma petición al mismo tiempo.
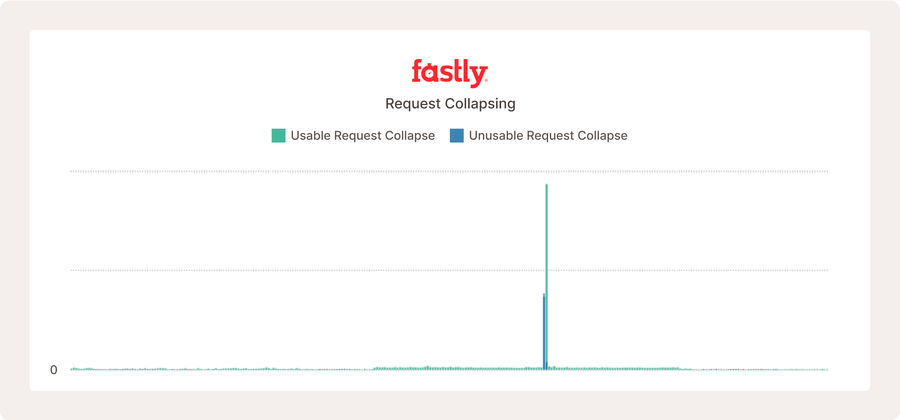
En el ejemplo anterior de un sitio web real, la reducción de peticiones a una sola no suele ocurrir hasta que hay un pico repentino en el tráfico para los mismos objetos de almacenar en caché.
Es importante destacar que un volumen mayor o menor de reducción de peticiones a una sola no es ni bueno ni malo. Esta no es una métrica de la que debas preocuparte por aumentar o disminuir, con una excepción (más sobre esto en un momento). Lo que muestra es con qué frecuencia servimos a los usuarios directamente desde tu origen al mismo tiempo. Una buena regla general es considerar cuán altos son estos recuentos en comparación con tus volúmenes generales de peticiones. Es completamente normal que haya pequeñas cantidades de reducción de peticiones a una sola con un resultado inutilizable. Esto se debe a que muchos errores de backend no son almacenables en caché y, en ocasiones, el comportamiento del usuario puede hacer que hagamos una petición de un objeto en el momento justo para que haya caducado cuando lo recibamos. Esto es completamente esperado.
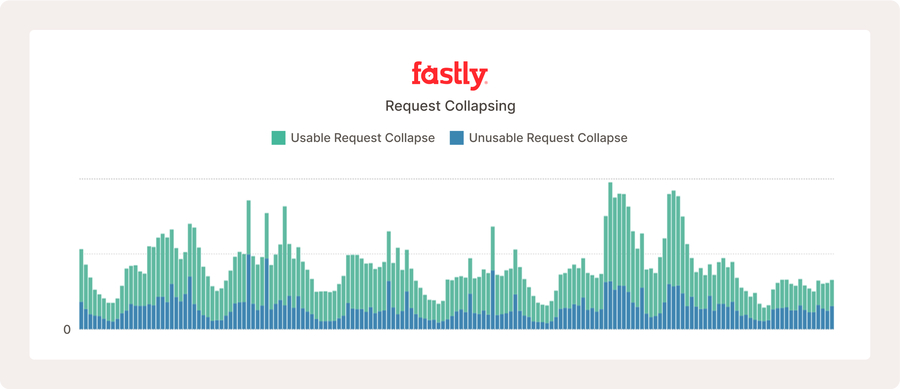
Muchas respuestas inutilizables pueden parecer problemáticas, como se muestra arriba. Sin embargo, este sitio web gestiona más de diez millones de peticiones cada hora, y lo que observamos es un comportamiento normal de internet debido a respuestas de error legítimas, que no se pueden almacenar en caché.
Volviendo a la advertencia que mencioné, una cosa que debes tener muy en cuenta (y contacta a tu representante de Fastly si ves que ocurre) es si tienes grandes volúmenes de recuentos inutilizables en comparación con tus volúmenes de peticiones. Esto es un posible indicador de serialización de peticiones. Hablaremos de eso con mucho más detalle en un blog futuro, pero brevemente, la serialización de peticiones significa que Fastly está intentando obtener un objeto para satisfacer varias peticiones a la vez, pero la respuesta no puede crear un objeto de almacenar en caché válido. Cuando esto ocurre, la petición inicial recibe el objeto inutilizable y la siguiente petición lo intenta de nuevo. Si esto sigue ocurriendo, solo responderemos a una petición a la vez, repetidamente. Esto es muy ineficiente y puede tener un impacto real en los usuarios.
Otra cosa complicada de estas métricas es que no pueden indicar si las peticiones se están concentrando en unos pocos objetos muy solicitados o en un gran número de objetos que solo son moderadamente solicitados. Esto es importante porque los grandes volúmenes de objetos inutilizables dispersos pueden ser completamente normales para tu flujo de trabajo. La reducción de peticiones a una sola puede ser un tema complicado, pero si has llegado hasta aquí, esperamos que hayas encontrado esto informativo en tu camino hacia la eficiencia. Planeamos tratar este tema con más detalle en futuros blogs. ¡No os lo perdáis!