
Since we made HTTP/2 generally available in November 2016, h2 traffic has been steadily growing as more customers migrate to the new version of the protocol; since the beginning of 2017, h2 traffic has increased by over 400% and h2 requests now make up more than 25% of the total requests on Fastly’s network. Last year, I did a couple of talks about h2 and its practical applications. But, I thought this would be a good time to highlight one of its major features: server push, which allows a server to preemptively send (or "push") responses to a client, conserving round trips. In this post we’ll discuss the feature and how you can get the most from it through Fastly.

What is server push?
H2 operates over a single TCP connection, and on that connection the client and server communicate through virtual channels known as streams. Every time the client wants to request an object, it sends a HEADERS frame with a new stream ID. This frame carries the requested object and associated request headers, and opens that stream between the two endpoints. The server, normally, would then respond with HEADERS and DATA frames over the same stream (i.e., with the same stream ID) delivering the response headers and the body data for the requested object to the client. Each stream ID is a number between 1 and 231 — client-initiated streams have odd numbers and server-initiated streams have even numbers.
Most streams are client-initiated since clients are the ones doing all the requesting. Server push is a mechanism whereby a server can open a stream to the client and send it an object preemptively, before the client asks for it. To do this, it gives the client a heads-up through a PUSH_PROMISE frame before sending any data. The whole process is better illustrated with a diagram:
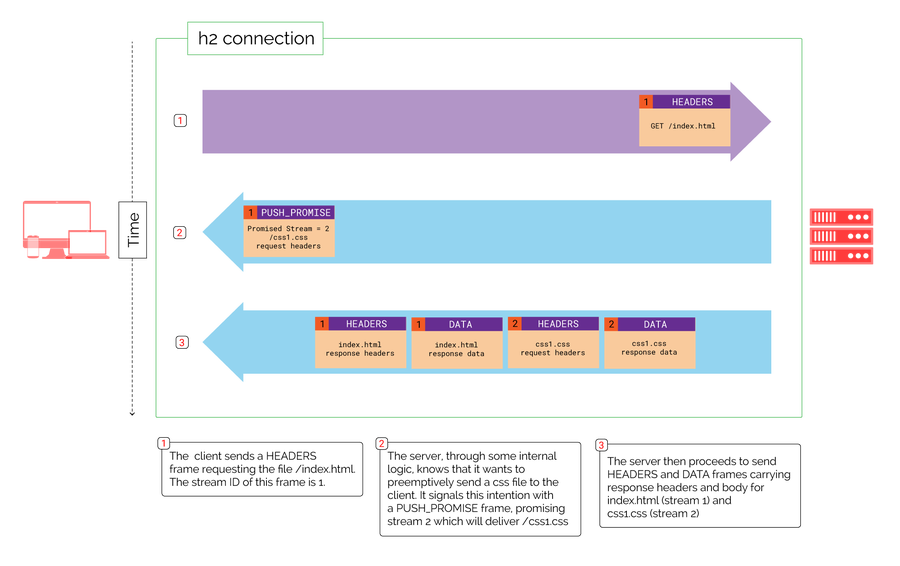
The diagram shows the general process a client and server go through when server push is used. The PUSH_PROMISE frame in this example is sent in step 2 and has a few interesting characteristics:
The frame itself is sent over stream 1, the original client-initiated stream.
The frame carries a promised stream ID of 2. This tells the client that a server-initiated stream with ID=2 will soon be established.
The frame also carries the would-be request headers for the file being pushed; headers the client would have sent if it was to request the file naturally, without push. Those headers will include things like HTTP scheme, origin, authority, and the file name (in this case
/css1.css). In other words, with push, the server sends both the request (as aPUSH_PROMISEframe) and the response (asHEADERSandDATAframes).
The main recommendation RFC 7540 makes for this process (through the proverbial spec-lingo mainstay “SHOULD”) is that the PUSH_PROMISE frame be sent before the data that references the object being pushed. In our example, this means that the PUSH_PROMISE frame for stream 2 should arrive at the client before the HTML object (on stream 1) that would reference the CSS file.
Server push is enabled by default in the protocol, although a client can request to disable it for the h2 connection via a parameter in a SETTINGS frame. As far as we’ve seen, most major browsers seem to support it.
There’s a lot of discussion about what to preemptively push to clients. The high-level consensus seems to be that the best assets to push are those crucial to the visual rendering of the current page navigation. Initially, server push was seen as an obvious replacement for inlining resources. This makes sense: by pushing previously inlined resources, we still get the benefits of inlining (less round trips from the browser) but without the drawback of not being able to cache those resources individually in the browser cache. Since server push will send the assets to the client as distinct HTTP objects (each with its own Cache-Control headers), they can be cached by the browser just like anything else.
As server push gets used more and more, the community is getting smarter about how best to utilize it. Google published a good paper on best practices and Fastly’s Patrick Hamann recently did a talk that highlighted critical resources to push for Time To First Meaningful Paint. I think server push use cases will continue to show up as we become more familiar with the protocol and figure out new ways to use the feature. In order to encourage our customers’ creativity, our job is to make sure you can use the mechanism as easily and flexibly as possible – that’s what I’ll focus on here.
Server push with Fastly
As the protocol first started being deployed, there needed to be an easy way to signal push to an h2-capable server. Using headers seemed like the simplest route, so the Link header was chosen by the community — and specifically its use case with W3C’s Preload mechanism. Preload (whether through the Link header or the <link> tag) is primarily intended to signal the browser’s preload engine to start downloading critical resources for the current page navigation without blocking the loading of the page. Server push became an extension to this, and the same general mechanism through a Link header started being used for h2’s server push.
The idea is that using a Link header with the relation type “preload” acts as a signal to an h2 server to initiate a push to the client:
Link: </css1.css>; rel=preload; as=styleThe Preload spec recognizes the fact that the Link header may also be used for server push and further defines a nopush directive, which tells an h2-capable server not to use the header as a mechanism for push, and pass it to the client as is.
There is some debate on whether or not it’s a good idea to use a header that already has a specific meaning to a browser as the primary signal for a server to push assets. The Preload spec partially addresses this issue with the nopush directive, but it leaves out an option for using the header only for push and not as an indicator for the browser. When we designed our server push implementation, we thought it best to make every permutation available to our customers so all use cases and combinations can be explored in order to find the best fit.
Fastly’s h2 engine, which is based on the excellent H2O server, supports the use of Link headers as a signal for server push. We’ve implemented three ways to interpret the header based on the directives used:
Standard use will cause a Fastly edge cache to push the indicated resource and also send the
Linkheader to the client:Link: </css1.css>; rel=preload; as=style
Used with the
nopushdirective, the header will not trigger server push and will be passed as is to the client:Link: </css1.css>; rel=preload; as=style; nopush
Used with the
x-http2-push-onlydirective, the header will trigger a server push but will be subsequently removed and not forwarded to the client:Link: </css1.css>; rel=preload; as=style; x-http2-push-only
The x-http2-push-only directive is an H2O-specific one that we felt was necessary to provide full flexibility. It’s implemented in H2O upstream as well.
You can include Link headers in responses from your origin, add them through the configuration web interface, or add them directly to your VCL (in vcl_deliver) as response headers (which means VCL snippets are also an option). Logically, our h2 engine sits in front of Varnish and would initiate a server push however it sees the headers. If you’d like to push multiple objects to the client, you can include multiple Link headers or a single header with a comma-separated list of values:
Link: </css1.css>; rel=preload; as=style,</css2.css>; rel=preload; as=styleThe resources indicated in the header can be relative or absolute links as long as their authority matches the request that triggered the push.
The problem with response headers
In standard web pages, it makes the most sense to have root HTML objects trigger server push, which is where we most commonly see Link headers used. This means our edge caches will learn about what they need to push as soon as they see response headers for the HTML object. If that HTML object is cached, this can happen immediately after the request is received. However, as much as we allow (and encourage) seemingly uncacheable HTML to be cached, there are still times where the HTML is truly dynamic and has to be requested from the origin every time. In these cases, pushing is delayed until the response is received from the origin. This isn’t really ideal:
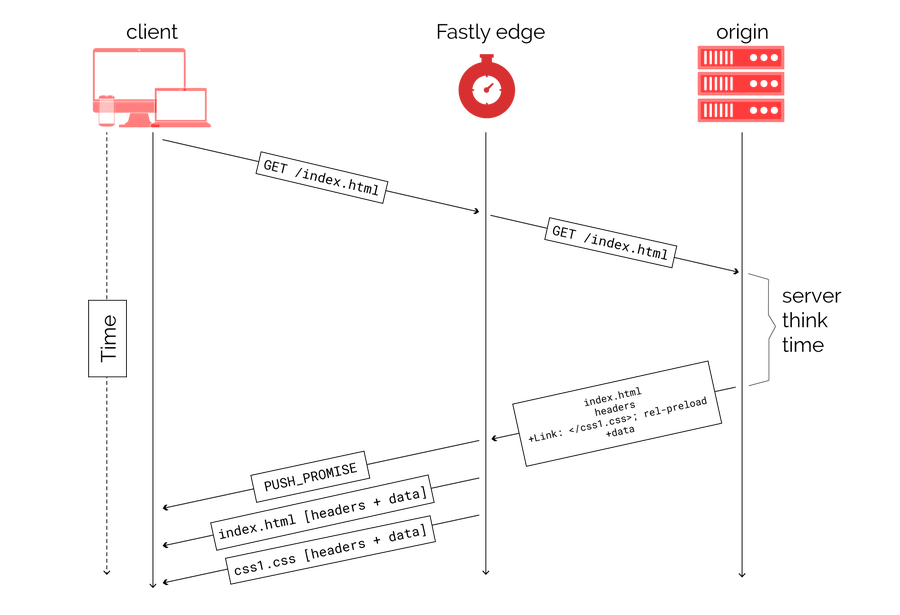
In this diagram, we can see that if the HTML was cached at the edge, server push would start as soon as the request is received (which is when a cached response is available to send to the client). But since it has to go all the way to origin, push is delayed until the server response is received from the origin. This problem is exacerbated if the origin is far away from the edge and/or the server takes significant “think time” to serve the response. Essentially, using Link headers for push makes the process a synchronous one since we need to wait for the server response. That time the client has to wait is basically wasted idle network time.
To address this issue, we’ve also developed an alternative to Link headers which we internally call “async push.” To trigger async push, we’ve implemented the h2.push() VCL function. Here’s a simple VCL snippet to show how it could be used:
sub vcl_recv {
#FASTLY recv
if (fastly_info.is_h2 && req.url ~ "^/index.html")
{
h2.push("css1.css");
}
}The filename passed to the function can be either a relative or absolute link and follows the same rules for HTTP authority as any file used in a Link header. Async push triggers server push immediately, even while the root HTML is still being fetched from the origin. This can provide a great performance boost, taking advantage of that wasted wait time to get some resources to the browser:
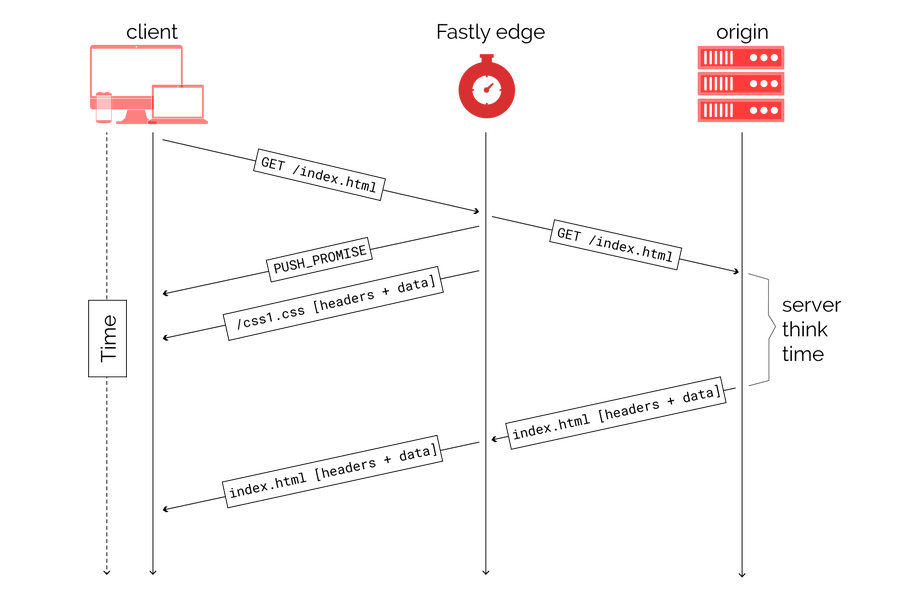
If used properly, once the HTML arrives at the client, critical resources will already be there so the rendering time for the page can be greatly improved. It looks pretty cool in a waterfall too — here’s push using Link headers for an HTML that takes a long time to fetch from the origin:
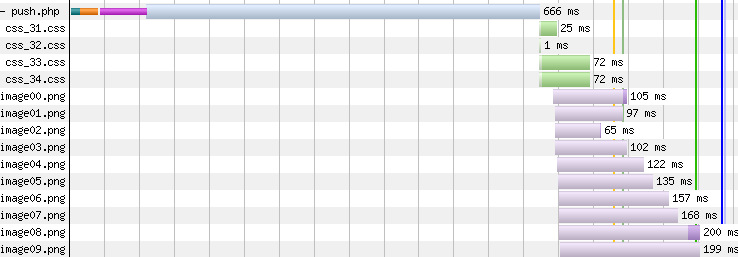
Source: Webpagetest
And here’s the same page with async push:
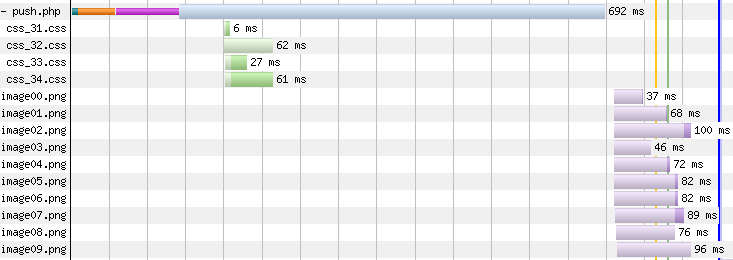
Source: Webpagetest
There’s a lot of wasted time in the first waterfall, waiting for the server, even though the four CSS files are being pushed. With async push, that idle network time can be put to good use by having critical resources pushed while the HTML itself is being fetched from the origin. Admittedly, this is somewhat of an exaggerated waterfall example, but it clearly shows the benefits of the mechanism and how it can be more powerful than using Link headers. Your results will depend on your application, but Patrick does a great job of quantifying the benefits of async push in his aforementioned talk, with a real-world example (here are the slides, as well as a very relevant and pretty chart).
The h2.push() function joins the other h2-specific variables available in VCL. This is also a good time to mention that any resource that Fastly sends a client as a result of server push carries the x-http2-push response header (e.g. x-http2-push: pushed), regardless of whether the push was initiated using Link headers or h2.push(). The header can come in handy for debugging and troubleshooting.
Looking ahead
Server push still has some problems, the biggest of which is to know when not to push an asset to the client. Specifically, if the object is already in the browser’s cache, the mechanism the protocol gives us for the client to reject a push (through a RST_STREAM frame, as outlined here) isn’t good enough because the data for the pushed objects may already be in flight. This may lead to wasted network bandwidth and can be expensive for mobile clients. Fastly’s server push mechanism won’t push the same resource twice over the same h2 connection, which can be helpful during a single user session across multiple pages. For future sessions, cookies can be used to a limited extent (e.g., set a cookie on first push and then don’t push again if the cookie is there), but a better overall mechanism is needed within the protocol.
With the goal of resolving this issue, Fastly’s Kazuho Oku (who is also the original author of H2O) is spearheading a new proposal for Cache Digests which defines a mechanism for a client to inform a server of the contents of its cache. This will allow smarter decisions for what to push and will be a huge step towards making sure we push the right things at the right time to the client.
Kazuho is also leading the way for a new HTTP status code 103 for Early Hints, which will add the ability for servers to behave more asynchronously by allowing them to send some response headers that are likely to be in the final response (including Link headers for signaling push) before sending the object with its full response headers. This mechanism will solve the problem of having to wait until a page is rendered server-side before the Link headers can be sent to the network.
Both these mechanisms will be supported by Fastly in the future as they become more defined and ultimately ratified by the standards community.
It’s true that server push is still relatively new and not always easy or intuitive to use. But despite its flaws, it’s a powerful mechanism offered by HTTP/2. At Fastly, we’ve aimed to provide maximum flexibility in deployment by supporting multiple ways to use the protocol feature. We’ll continue to fine-tune our feature set to enable the most options for our customers as they start utilizing it more and more. Feel free to leave a comment below to let us and the rest of the community know all of the cool ways you’re using server push.