
The following is adapted from a post Andrew wrote for Smashing Magazine.
I’ve previously written about Vary in relation to CDNs: the intermediary caches (like Fastly’s) that you can put between your servers and the user. Browsers also need to understand and respond to Vary rules, and the way they do this is different from the way Vary is treated by CDNs. In this post I’ll explore the murky world of cache variation in the browser.
Today’s use cases for varying in the browser
As we saw previously, the traditional use of Vary is to perform content-negotiation using the Accept, Accept-Language, and Accept-Encoding headers, and historically the first two of these have failed miserably. Varying on Accept-Encoding, to deliver gzip or brotli-compressed responses where supported, mostly works reasonably well, but all browsers support gzip these days so this isn’t very exciting.
But how about some of these ideas?
We want to serve images that are the exact width of the user’s screen. If the user resizes their browser, we download new images (varying on client-hints).
If a user logs out, we want to avoid using any pages that were cached while they were logged in (using a cookie as a Key).
Users of browsers that support the WebP image format should get WebP images, otherwise they should get JPEGs.
When using a browser on a high-density screen, the user should get a 2x image. If they move the browser window onto a standard density screen and refresh, they get 1x images.
Caches all the way down
Unlike edge caches, which act as one gigantic cache shared by all users, the browser is just for one user, but has lots of different caches for distinct, specific uses:

Some of these are quite new, and understanding exactly which cache content is being loaded from is a complex calculation which is not well supported by developer tooling. Here’s what these caches do:
The image cache is a page-scoped cache that stores decoded image data so that, for example, if you include the same image on a page multiple times, the browser only needs to download and decode it once.
The preload cache is also page-scoped and stores anything that has been preloaded in a Link: header or
<link rel=”preload”>tag, even if the resource is ordinarily uncachable. Like the image cache, the preload cache is destroyed when the user navigates away from the page.The Service Worker cache API provides a cache backend with a programmable interface, so nothing is stored here unless you specifically put it there via JavaScript code in a service worker. It will also only be checked if you explicitly do so in a service worker fetch handler. The service worker cache is origin-scoped, and while not guaranteed to be persistent, it’s more persistent than the browser’s HTTP cache.
The HTTP cache is the main cache that people are most familiar with. It is the only cache that pays attention to HTTP-level cache headers like
Cache-Control, and combines these with the browser’s own heuristic rules to determine whether to cache something and for how long. It has the broadest scope — being shared by all sites, so if two unrelated sites load the same asset (e.g., Google Analytics) they may share the same cache hit.Finally the HTTP/2 push cache (aka “H2 push cache”) sits with the connection, and stores objects that have been pushed from the server but have not yet been requested by any page that is using the connection. It is scoped to pages using a particular connection, which is essentially the same as being scoped to a single origin, but is also destroyed when the connection closes.
Of these, the HTTP cache and Service Worker cache are best defined. As for the image and preload caches, some browsers may implement them as a single “memory cache” tied to the render of a particular navigation, but the mental model I’m describing here is still the right way to think about the process. See the spec note on preload if you’re interested. In the case of the H2 server push, there continues to be active discussion over the fate of this cache.
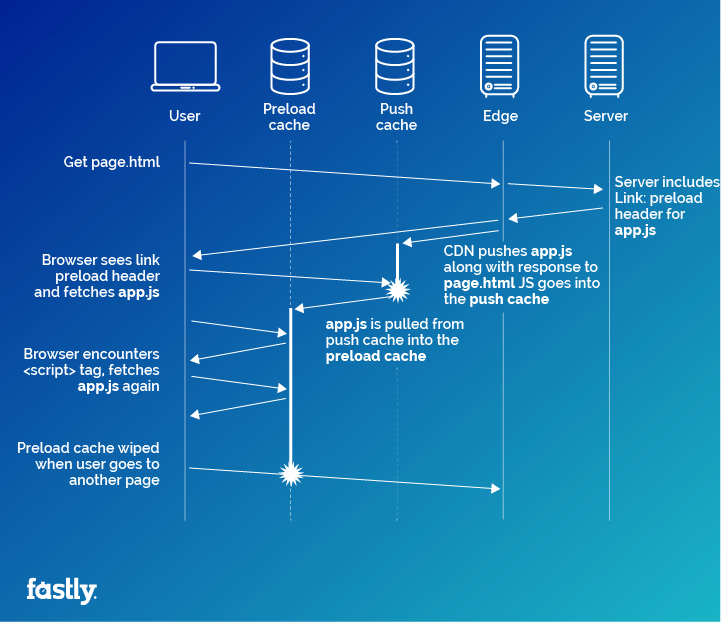
The order in which a request checks these caches before venturing out onto the network is important, because requesting something might pull it from an outer layer of cache into an inner one. For example, if your HTTP/2 server pushes a stylesheet along with a page that needs it, and that page also preloads the stylesheet with a <link rel=”preload”> tag, then the stylesheet will end up touching three caches in the browser. First, it sits in the H2 push cache waiting to be requested. When the browser is rendering the page and gets to the preload tag, it will pull the stylesheet out of the push cache, through the HTTP cache (which might store it, depending on the stylesheet’s Cache-Control header), and will save it in the preload cache.
Introducing Vary as a validator
OK, so what happens when we take this situation and add Vary into the mix?
Unlike intermediary caches (such as CDNs), browsers typically do not implement the capability to store multiple variations per URL. The rationale for this is that the things we typically use Vary for (mainly Accept-Encoding and Accept-Language) do not change frequently within the context of a single user. Accept-Encoding might (but probably doesn’t) change on a browser upgrade, and language would most likely only change if I edit my OS language locale settings. It also happens to be a lot easier to implement Vary in this way, though some spec authors believe this was a mistake.
It’s no great loss most of the time for a browser to store only one variation, but it is important that we don’t accidentally use a variation that isn’t valid anymore if the varied-on data does happen to change.
The compromise is to treat Vary as a validator, not a key. Browsers compute cache keys in the normal way (essentially, use the URL), and then if they score a hit, check that the request satisfies any Vary rules that are baked into the cached response. If it doesn’t, the browser treats the request as a miss on the cache, and moves on to the next layer of cache or out to the network. When a fresh response is received, it will then overwrite the cached version, even though it’s technically a different variation.
Demonstrating vary behaviour
To demonstrate the way Vary is handled, I made a little test suite. The test loads a range of different URLs, varying on different headers, and detects whether the request hit the cache or not. I was originally using ResourceTiming for this, but for greater compatibility I ended up switching to just measuring how long the request took to complete (and intentionally added a one-second delay to server-side responses to make the difference really clear).
Let’s look at each of the cache types and how Vary should work, and whether it actually works like that. For each test, I show here whether we should expect to see a result from the cache (HIT vs MISS) and what actually happened.
Preload: Preload is currently only supported in Chrome, where preloaded responses are stored in a memory cache until they are needed by the page. They also populate the HTTP cache on their way to the preload cache, if they are HTTP-cacheable. Since it’s impossible to specify request headers with a preload, and the preload cache only lasts as long as the page, it’s hard to test this, but we can at least see that objects with a Vary header do get preloaded successfully:

Service Worker Cache API: Chrome and Firefox support Service Worker, and in developing the Service Worker spec, the authors wanted to fix what they saw as broken implementations in browsers, to make Vary in the browser work more like CDNs. That means that while the browser should store only one variation in the HTTP cache, it is supposed to hold on to multiple variations in the Cache API. Firefox (54) does this correctly, while Chrome uses the same vary-as-validator logic that it uses for the HTTP cache (raised CRBug).

HTTP cache: The main HTTP cache should observe Vary, and does so consistently (as a validator) in all browsers. For much, much more on this, see Mark Nottingham’s State of browser caching, revisited.
HTTP/2 push cache: Should observe Vary, but in practice no browser actually respects this, and browsers will happily match and consume pushed responses with requests that carry random values in headers that the responses are varying on.

The 304-Not-Modified wrinkle
The HTTP 304 “Not Modified” response status is fascinating. Our dear leader Artur Bergman pointed out this gem in the HTTP caching spec (emphasis mine):
The server generating a 304 response MUST generate any of the following header fields that would have been sent in a 200 (OK) response to the same request: Cache-Control, Content-Location, Date, ETag, Expires, and Vary.
Why would a 304 response return a Vary header? The plot thickens when you read about what you’re supposed to do upon receiving a 304 response that contains those headers:
If a stored response is selected for update, the cache MUST [...] use other header fields provided in the 304 (Not Modified) response to replace all instances of the corresponding header fields in the stored response.
Wait, what? So if the 304’s Vary header and the one on the existing cached object are different, we’re supposed to update the cached object, but that might mean it no longer matches the request we made!
In that scenario, at first glance the 304 seems to be telling you simultaneously that you can, and you can’t, use the cached version. Of course if the server really didn’t want you to use the cached version it would have sent a 200, not a 304, so the cached version should definitely be used, but after applying the updates to it, it might not be used again for a future request identical to the one that actually populated the cache in the first place.
(Side note: At Fastly we do not respect this quirk of the spec, so if we receive a 304 from your origin server, we will continue to use the cached object unmodified, other than resetting the TTL.)
Browsers do seem to respect this, but with a quirk. They update not just the response headers but the request headers that pair with them, so as to guarantee that post-update, the cached response is a match for the current request. This seems to make sense. The spec doesn’t mention this so the browsers are free to do what they like, but luckily all browsers exhibit this same behaviour.
Client Hints
Google’s Client Hints feature is one of the most significant new things to happen to Vary in the browser in a long time. Unlike Accept-Encoding and Accept-Language, Client Hints describe values that might well change regularly as a user moves around your website, specifically the following:
DPR
Device pixel ratio, the pixel density of the screen (might vary if the user has multiple screens)Save-Data
Whether the user has enabled data-saving modeViewport-Width
Pixel width of the current viewportWidth
Desired resource width in physical pixels
Not only might these values change for a single user, but the range of values for the width-related ones is large. So, we can totally use Vary with these headers, but we risk reducing our cache efficiency or even rendering caching ineffective.
The Key header proposal
Vary has been around for a long time, and there is now a proposal to replace it with a new header called Key. Let’s look at a couple of examples:
Key: Viewport-Width;div=50This says that the response varies based on the value of the Viewport-Width request header, but rounded down to the nearest multiple of 50 pixels.
Key: cookie;param=sessionAuth;param=flagsAdding this header into a response means we’re varying on two specific cookies: sessionAuth and flags. If they haven’t changed we can reuse this response for a future request.
So, the main differences between Key and Vary are:
Keyallows varying on subfields within headers, which suddenly makes it feasible to vary on cookies, because you can vary on just one cookie. This opens up the possibility of varying on virtually any arbitrary data, such as whether the user is logged in.Individual values can be bucketed into ranges, to increase the change of a cache hit, particularly useful for varying on things like viewport width.
All variations with the same URL must have the same
Key, so if a cache receives a new response for a URL for which it already has some existing variants, and the new response’s Key header value doesn’t match the values on those existing variants, all the variants must be evicted from the cache.
At time of writing no browser or CDN supports Key, though in some CDNs you may be able to get the same effect by splitting incoming headers into multiple private headers and varying on those (for how to do this with Fastly, see here) so browsers are the main area where Key can make an impact.
The requirement for all variations to have the same key recipe is somewhat limiting, and I’d like to see some kind of “early exit” option in the spec. This would enable you to do things like “vary on authentication state, and if logged in, also vary on preferences.”
The Variants proposal
Key is a nice generic mechanism, but some headers have more complex rules for their values, and understanding those values’ semantics can help us to find automated ways of reducing cache variation. For example, imagine that two requests come in with different Accept-Language values, en-gb and en-us, but although your website does have support for language variation, you only have one “English.” If we answer the request for US English and that response is cached on a CDN, then it can’t be reused for the UK English request, because the Accept-Language value would be different and the cache isn’t smart enough to know better.
Enter, with considerable fanfare, the Variants proposal. This would enable servers to describe which variants they support, allowing caches to make smarter decisions about which variations are actually distinct and which are effectively the same.
Right now, Variants is a very early draft, and because it is designed to help with Accept-Encoding and Accept-Language, its usefulness is rather limited to shared caches, such as CDNs, rather than browser caches. But it nicely pairs up with Key and completes the picture for better control of cache variation.
Conclusions
There’s a lot to take in here, and while it can be interesting to understand how the browser works under the hood, there are also some simple things you can distil from it:
Most browsers treat
Varyas a validator. If you want multiple separate variations to be cached, find a way to use different URLs instead.Browsers ignore
Varyfor resources pushed using HTTP/2 Server Push, so don’t vary on anything you push.Browsers have a ton of caches, and they work in different ways. It’s worth trying to understand how your caching decisions impact performance in each one, especially in the context of
Vary.Varyis not as useful as it could be, andKeypaired with Client hints is starting to change that. Follow along with browser support to find out when you can start using them.