
In the past, I've given a number of talks about dealing with uncacheable content and using CDNs to extend the application to the edge by treating them as part of your stack. In these talks, I use real-world examples to discuss some of these topics. Using a CDN for beacon termination at the edge is the one example that has gotten the most amount of attention and generated the most questions. This is partially because edge termination for beacons is cool; but it’s mostly because beaconing applications are becoming more popular and they involve a lot of components, deployed at scale, to accommodate proper data collection. These applications are primarily used for analytics, monitoring, and targeting — all of which have become vital elements in today’s modern business operations — making their deployment critical. Using a CDN with edge caches and the right combinations of features can help application deployment and the collection of crucial data, so I thought it'd be a good idea to finally write about it.
What are beacons?
Chances are you're already familiar with beacons, and even if you're not, you're certainly subjected to many during your normal web browsing day. Wikipedia has a nice long description on what beacons are, but here are the essentials:
Beacons are sent from your browser as you surf from site to site and from page to page, if they’ve been coded into those pages. Typically, beacons are sent because some javascript in the page (either a first- or third-party script) is collecting some data about that particular page view or site visit. The script can be collecting web analytics data about the visit, gathering performance information about the page view, feeding an ad network with information about browsing habits, or any number of other applications. Whatever it may be, the collected information is usually sent from the browser via a beacon. Google Analytics is responsible for many of the beacons seen on the web, and most Real User Monitoring (RUM) tools (like those from our friends at SOASTA and Catchpoint, and New Relic) use beacons to report performance information to their respective services.
A beacon is a single HTTP request, with all collected information either reported through query parameters or through POST content. And since it's usually for data collection, most "polite" scripts wait until the page has completely loaded before they fire off their beacons so as to not affect page load times. Here's an example of what a very simple beacon might look like:
http://some_analytics_service/image.png?key1=value1&key2=value2&key3=value3Here, the beacon is reporting back three pieces of data via query parameters as key=value pairs. More realistically, here's a Google Analytics beacon sent from a browser visiting one of the Google Cloud Platform product pages:
https://www.google-analytics.com/internal/collect?v=1&_v=j44&a=1075432611&t=pageview&_s=1&dl=https%3A%2F%2Fcloud.google.com%2Fcompute%2F&dr=https%3A%2F%2Fwww.google.com%2F&ul=en-us&de=UTF-8&dt=Compute%20Engine%20-%20IaaS%20%C2%A0%7C%C2%A0%20Google%20Cloud%20Platform&sd=24-bit&sr=2560x1080&vp=1469x286&je=0&fl=22.0%20r0&_u=QEAAAEABC~&cid=1868971048.1468120331&tid=UA-36037335-1>m=GTM-5CVQBG&cd1=&cd2=%5Bobject%20Object%5D&cd4=&cd14=GTM-5CVQBG%3A188&cd16=False&cd17=False&cd22=True&cd31=(not%20set)&cd32=(not%20set)&cd34=(not%20set)&z=1436980794and here's the same beacon broken down in Chrome's DevTools:
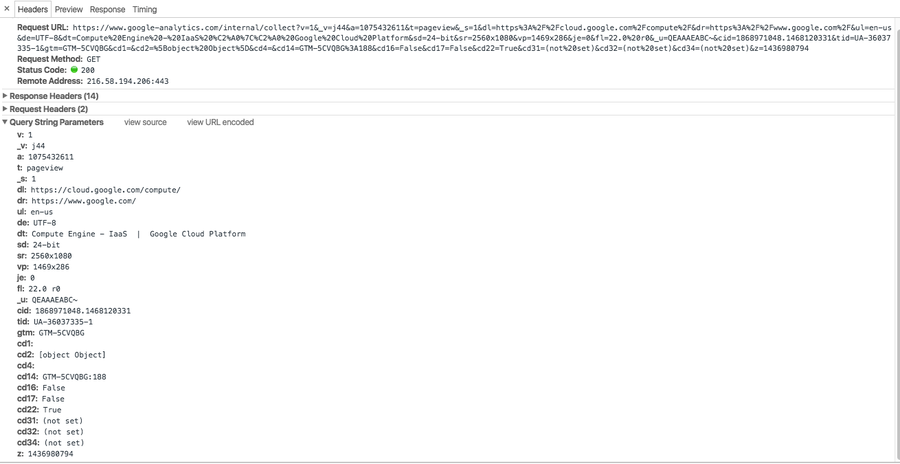
Beacons are extremely common these days and many services use them to collect and report data. Likewise, many application owners develop their own javascript and collect data about their site visitors through beacons. Their prevalence is one of the reasons the W3C is working on a standards beacon API for browsers, already supported by some major ones.
Typical data collection
Beacons are HTTP requests that carry valuable data; browsers use them to report this data to a collector of some sort. Since an HTTP request needs to be sent to a web server, typical data collection involves a web server that receives the requests and logs them. In fact, logging HTTP requests is the most important thing these collectors do. Log files are then post-processed and the data from the logs is inserted into a data warehouse.
Most often, the response to a beacon is a single 1x1 transparent image that never visually renders on the page. But recently, the HTTP status code 204 (No Content) has been seeing more airtime as a legitimate response to beacons since the browser usually doesn't actually need to do anything with the response. But we live in an HTTP world where when you send a request, it'd be nice to hear something back from the server; HTTP is a needy protocol that way!
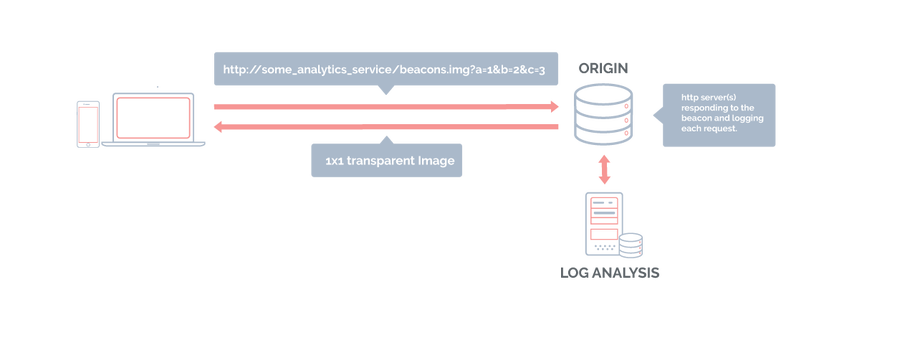
In high-volume applications, there may be many collectors to handle the large number of beacons — just fielding requests, logging them, and responding with tiny images or empty responses.
Traditionally with a CDN, beacons pass right through to the origin because the data they carry needs to be seen and logged by a collector. So, with beaconing applications, CDNs have typically just been deliver-to-origin mechanisms. They'd terminate TCP/TLS connections somewhere near the client, send beacons to the origin, and then deliver the response back to the client, maybe using mechanisms like DSA (dynamic site acceleration) in the process to optimize that delivery.
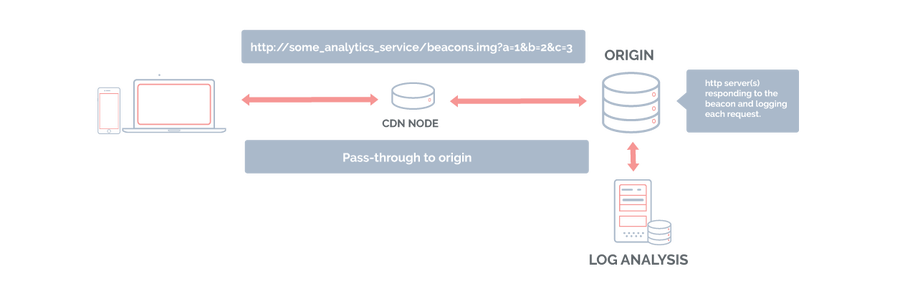
Terminating beacons at the edge
There are two important attributes to remember about most beacons:
Each beacon carries crucial data that needs to be logged.
The response to the browser is typically not at all important (many think of beacons as send-it-and-forget-it requests, hence the use of 204s).
Taking these into consideration, we can use a couple of Fastly features to build termination and collection mechanisms entirely at the edge.
First, instead of sending the beacon all the way to origin, we can simply terminate it at the edge and respond to the browser from the cache it connected to. If, for some reason, the application requires an actual response, like a 1x1 image (some browsers, for example, may have issues with 204 responses to POST requests), we can respond with one from the cache (after making sure the request is cacheable by having the cache key ignore the query parameters). Or, better yet, we can use synthetic responses to construct a 204 response at the edge. Here’s some Custom VCL that does that, but you can also do this in the Fastly control panel:
For collection, real-time log streaming allows us to collect the information contained in the beacon and send it to a logging destination of our choice (like Amazon S3, Google Cloud Storage, syslog, etc). Log streaming lets us define the format of each log line to be collected. So, we can log req.url for beacons that carry data as a query string and req.postbody to handle beacons with POST bodies (up to 2K body size, and assign req.postbody to a header in vcl_recv first and then log that header). In the case of the former, we can also use some of the cool query string manipulation features that Fastly offers to further clean up the parameters if necessary.
Log streaming also lets us include VCL variables in the log entry. So, for example, we can log client IP addresses (client.ip), geo information, or anything else available in VCL along with the data being reported via the beacons themselves.
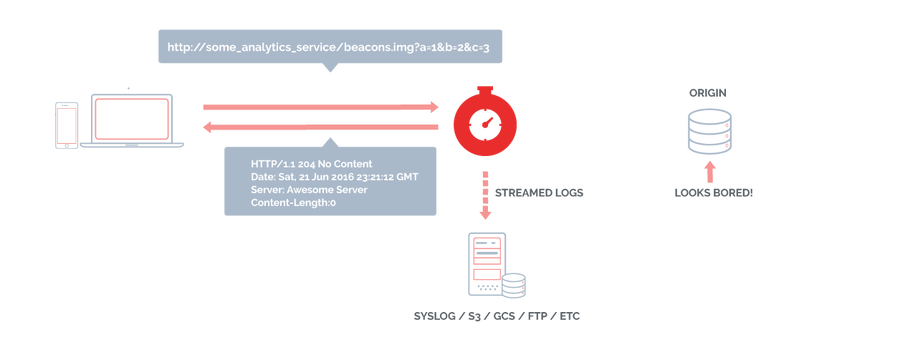
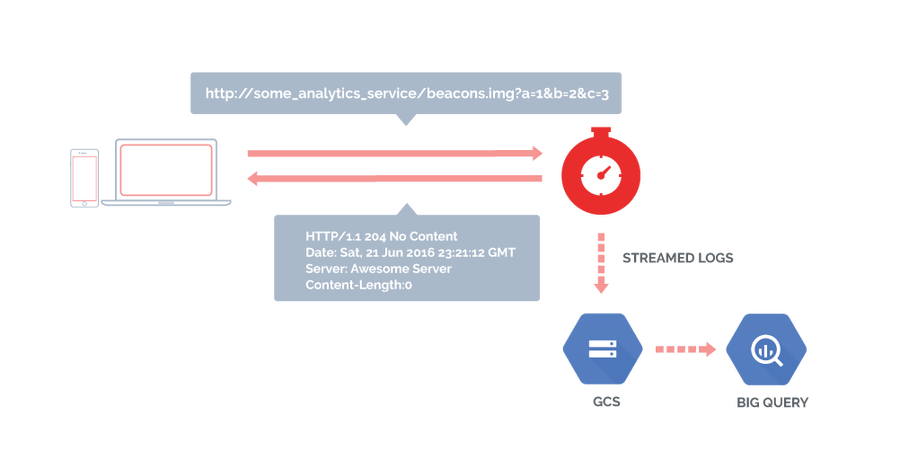
As the diagram above shows, with Fastly, things have become simpler. Here's the flow:
The browser sends beacon to Fastly.
The edge cache responds with a 204 No Content HTTP response.
The request is logged to a log destination.
The logs are later processed for data extraction and warehousing.
Let's not forget that Fastly's log streaming is real time. So, if the data from the beacons needs to be processed quickly, the log destination has it right away.
There are many ways to use log streaming to collect and store the data being reported by beacons. My personal favorite recently has been logging to Google Cloud Storage (GCS) and then directly exporting that data into BigQuery. Here's a sample VCL:
Here are some key points from this VCL snippet:
We construct a log line in CSV format.
Along with the URL, we're also logging the timestamp, the /24 of the client IP and some basic geo info.
The beacon is responded to by a synthetic HTTP response with a 204 status code.
The logging configuration causes CSV files to be written to GCS. Note that "Google GCS" is the name of the log destination we've configured separately in the Fastly control panel. It’s also a good idea to attach an always-false condition to this log destination in the control panel (e.g.
!req.url) to prevent duplicate log entries. You can also set up logging entirely in the control panel.BigQuery allows data import from GCS, so the CSV is directly imported to BigQuery and data is ready to be analyzed from that point.
Depending on how quickly we need the data, we would just adjust logging frequency in the Fastly configuration and import into BigQuery at a higher frequency.
This is just one example with BigQuery, but the same is possible with S3 and Amazon RedShift. And I'm sure other log destinations and data warehouses can easily be integrated by people much smarter than me.
Going forward: building an origin-less application
Terminating beacons at the edge removes the need for a web server, or a farm of web servers, that act as logging collectors, making data collection much easier. In fact, we're capable of using Fastly to build an entirely origin-less application — or in the case of our GCS/BigQuery example, a completely server-less one! This is extremely powerful and is a perfect example of using Fastly as a platform to build applications with. In this case, we terminate beacons and collect data. But, the mechanisms are in place to be more creative and construct other applications as well. This is what we mean when we talk about extending your applications to the edge and using Fastly as part of your stack.
Neat, huh?!