A few months ago, we launched the beta of Compute, our new serverless environment designed as the most secure, performant approach to building sites and apps at the edge. You hear us talk about the edge a lot — and while Compute allows us to take edge computing further, it also exposes fundamentally new ways to build there. Ways that developers more commonly associate with serverless.
One reason we wanted to roll this out in beta was to learn about serverless with our community: our customers and developers have tons of unique use cases, brilliant new ideas we hadn’t thought of, and some really fascinating questions about how they could put Compute and serverless more generally to use.
That’s why we asked our beta community to respond to a survey, probing into some of these plans and challenges, and soliciting a variety of industries and perspectives. Below, we’re sharing the most valuable takeaways and trends, and unpacking the areas where our community asked for more information.
Trends
Interest in serverless is high
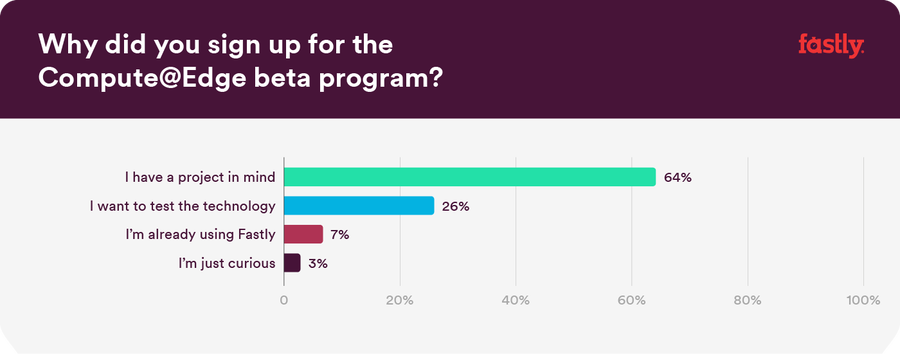
We learned that our community is not coming to the table empty-handed. Discovery and usage of serverless technology is on the rise, and it’s sparking some big ideas. Although many people expressed a sheer curiosity to test new serverless technology, 64% of respondents already have a project or initiative top of mind for Compute.
Many organizations are already using serverless
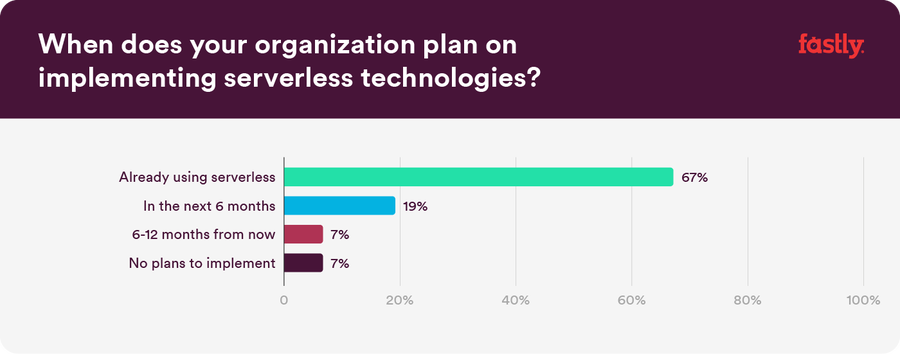
Although serverless is a relatively new technology, it’s growth and increase in usage is undeniable. A whopping 67% of respondents claim that they are already using serverless — and nearly 19% have plans to implement in the next six months.
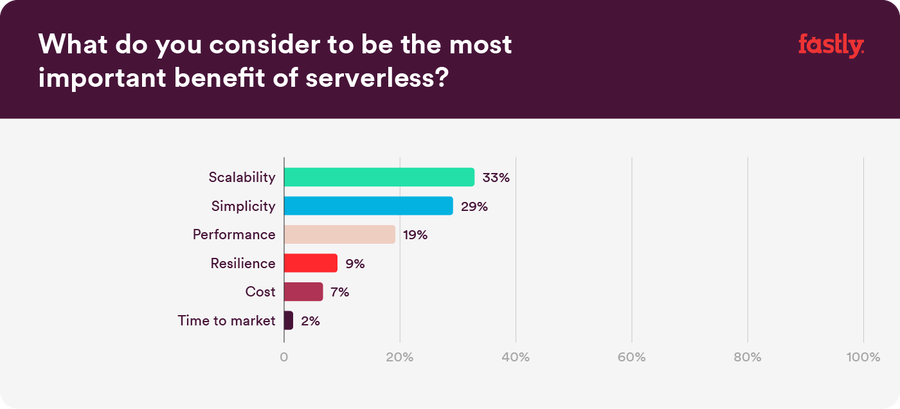
It’s all about scalability, performance, and simplicity
It should come as no surprise that most of our beta members care about scalability, improved performance, and simplicity. Why? These are some of the biggest perceived benefits around serverless technology as a whole.
With serverless edge computing, you can execute code at the edge of a distributed infrastructure without having to manage the underlying servers. This means simply uploading and deploying code, and letting the provider take care of everything required to operate and scale it. Compute aims to take it a step further: getting you even closer to end users, where code runs simultaneously across thousands of servers and reduces latency.
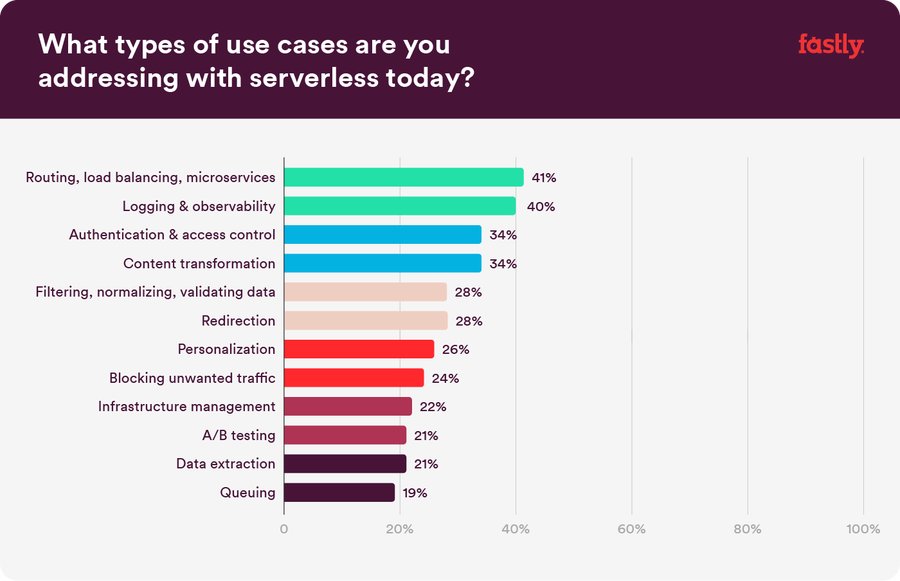
Serverless use cases abound
Like our community, we see a whole suite of use cases for serverless — many of which are easy to test out and try by moving small bits of logic to the edge. And as more and more people use serverless, we’ll see which use cases grow in popularity and demand, and we know our community will continue to be at the forefront of edge compute and its future.
Challenges
The perceived limitations of serverless
Because serverless is still relatively nascent and can even feel like a buzzword, we know it’s not easy to just hop on board. As the community explores serverless at large, we’ve seen some common concerns and preconceptions around using serverless. In our findings, cold start times and observability were to the top two perceived limitations of serverless computing.
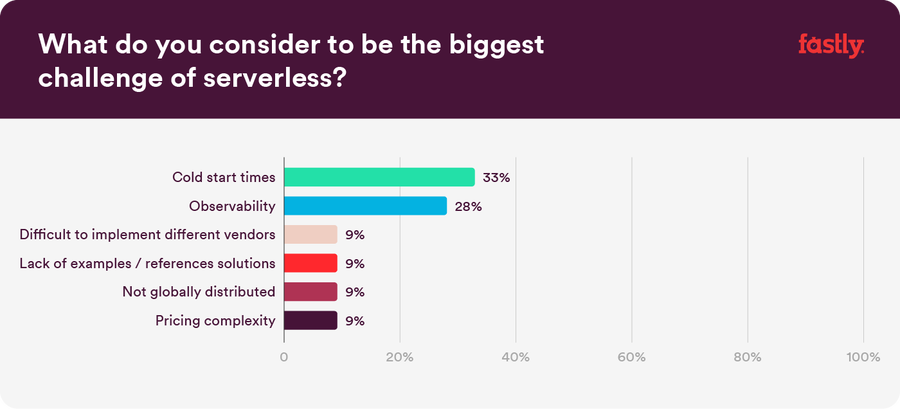
So, what does this mean?
Cold start times
Cold start times, or “slow startup times,” are often considered a consequence of serverless computing. Typically, this occurs when a serverless provider has to spin up a new serverless instance to run code. When logic is triggered for the first time (or for the first time in a while), the cloud provider must spin up new infrastructure to fulfill the request — and the process is commonly referred to as a cold start. This typically adds several hundred milliseconds to start times, and results in high latency.
We know just how painful the cold start experience can be and how much of a concern this is, which is why we're laser-focused on building low-latency solutions at the edge. Our goal with Compute is to deliver a serverless edge computing platform with no cold start times and one that puts you and your code as close to your end users as possible.
Observability
Observability is another capability that people perceive as suffering in a serverless computing environment. Since serverless computing is often used as a part of an overall app development strategy — alongside a mix of other technologies — it’s no small feat to create an end-to-end view of performance. An entire category of enterprise software is devoted to addressing this problem, but serverless computing platforms don’t provide the same breadth and depth of analytics that many developers are used to, which makes it harder to debug and monitor serverless code.
Not having instant or granular access to analytics, which can help you find and fix operational issues fast, is a scary obstacle for many organizations evaluating serverless computing. Losing visibility into what is happening with code after deployment can put development processes and even entire applications at risk. Observability is top of mind for Compute beta registrants, as well as the overall community of organizations considering serverless, which is why we’re dedicated to bringing a whole-new level of serverless visibility to market, and have more developments to come on this front.
Tying it all together
Connecting with our community over their visions for serverless and the ways it can make their lives better has been one of the most exciting parts of our Compute release. We’ve seen that serverless is growing, and that our community is ready to implement, learn, and scale as the technology continues maturing. While cold start times and observability seem like barriers to entry with serverless as a whole — know that we hear you on these concerns, and are actively working on solutions to mitigate them.
Lastly, we know that serverless technology at the edge is complex: it can take some time to really sink your teeth into and understand how you can incorporate the technology into the future of your own teams and companies. Our beta is still open so we can hear from you more directly and keep learning together, and we’ll continue sharing our insights along the way to help open those doors. We’re already seeing some incredible things from our community, and can’t wait for what’s ahead.