

GraphQL is an open-source query language that can be used as an alternative to REST. Developers are rapidly adopting it to meet the flexibility needed to maintain modern, high-growth APIs. It gives clients the power to ask exactly what they need and makes it easier to evolve APIs over time.
While the benefits are palpable, the security implications of GraphQL are less understood. What functionality can be abused by attackers? What are the unintended consequences of querying flexibility? Which vulnerabilities are easiest for attackers to exploit?
In this article, we'll explore these questions and offer guidance on which defaults and controls can support a safer GraphQL implementation. We’ll discuss these in the context of three categories — risky configurations, nefarious queries, and web API vulnerabilities. Let’s dig in!
Tips for Configuration
GraphQL implementations offer legitimate features that can be abused by attackers — including introspection, field suggestions, and debug mode – and therefore should only be made available carefully.
1. Avoid Introspection
The challenge: GraphQL is introspective. This means you can query a GraphQL schema for details that completely reveal information about its data structures, including arguments, fields, types, descriptions, and deprecated status of types. Leaking this information can potentially expose additional attack surfaces, which may contain other interesting vulnerabilities for attackers to leverage.
For example, if you want to list all types in a schema and get details about each, you can use an introspection query to ask:
{
__schema {
types {
name
kind
description
fields {
name
}
}
}
}By the same token, GraphQL offers an Integrated Development Environment (IDE) named GraphiQL (note the i) that allows users to construct queries by clicking through fields and inputs in a user-friendly interface. GraphiQL is another avenue used to understand the supported schema and subsequently expose additional attack surfaces, such as what queries or mutations exist.
Interrogating the server in this way could provide the missing piece when trying to construct a complex, high-severity attack. Let’s suppose, through the use of introspection, we uncover an object called UploadFile:
{
"name": "UploadFile",
"kind": "OBJECT",
"description": null,
"fields": [
{
"name": "content"
},
{
"name": "filename"
},
{
"name": "result"
}
]
}An attack method that might come to mind to exploit this discovery is a traversal attack, which aims to access or modify files and directories that are stored outside the web root folder. For the sake of this example, let’s just assume the filename argument allows any string and provides the ability to write to any location on the server’s filesystem. Then, we craft a query in an attempt to write a file called poc.php as follows:
mutation {
uploadFile(filename:”../../../../var/www/html/app/poc/poc.php”, content: “<?php
phpinfo(); ?>”){
result
}
}After making this call through our attack vector, we’re able to see that we have arbitrary code execution. And from there, we could try to gain a reverse shell to interact with the underlying server environment.
The solution: Introspection is useful in development, but avoid it when you're providing access to protected sensitive information.
It might be tempting to use introspection to help users learn how to query the API, but separate documentation (such as readthedocs) is safer. Disabling introspection doesn't actually fix any vulnerabilities, but at least you won’t be making the attacker's life easier.
Many implementations of GraphQL enable introspection by default. The safest approach is to disable introspection system-wide. Luckily, there are helpful resources on restricting introspection in popular frameworks and programming languages, including Ruby, NodeJS, Java, Python, and PHP. Nuclei also offers a template that can be used to test introspection of your GraphQL implementations.
2. Disable Field suggestions
The challenge: If introspection is disabled, attackers may attempt to brute force GraphQL schema using a feature commonly referred to as field suggestions. Field suggestions are triggered by supplying an incorrect field name in a query, resulting in an error response that discloses fields with similar names.
For instance, sending a query for name (query { name }) results in the following response:
{
"errors": [
{
"message": "Cannot query field \"name\" on type \"Query\". Did you mean \"node\"?",
"locations": [
{
"line": 2,
"column": 3
}
]
}
]
}The solution: Field suggestions can be a handy feature when a developer is trying to integrate an API with GraphQL or against public APIs. But even so, the field suggestions feature should be handled with caution. You should consider disabling this feature in any environment that provides access to protected sensitive information.
3. Disable "Debug" Mode
The challenge: Errors are meant to be helpful; they help give us some insight as to what’s happening when something goes wrong. However, improperly handling errors can introduce a variety of security issues in GraphQL.
GraphQL can be run in “debug” mode. The main feature of debug is to display detailed errors of request to aid with development. This is extremely problematic if you run your GraphQL implementation in production with debug enabled. Doing so will result in excessive errors, such as stack traces, and it exposes other sensitive information in the response, which jeopardizes not just security, but compliance adherence, too.
Example stack trace
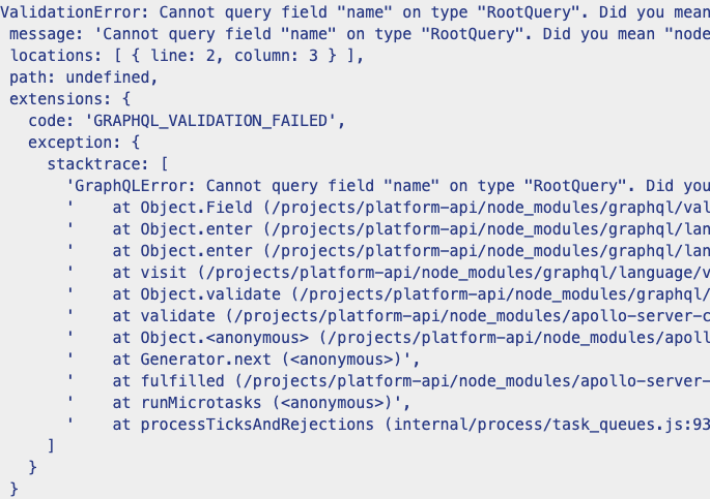
The solution: Ensure “debug” mode is disabled in production and omit stack traces before details are passed back to clients.
If you want to log stack traces, there are ways to do it without returning it to the user and making it only available to the developers. One popular way to have better control over errors is by implementing a middleware, in which you can inspect and modify a request allowing you to enforce error masking or redaction.
Tips for Nefarious Attacks
Attackers can craft nefarious GraphQL queries that can lead to opportunities for denial of service (DoS), brute force, and enumeration.
4. Set Max Depth
The challenge: Each query in GraphQL has a query depth expressed in terms of the number of nested fields and the amount of objects within the nested fields. Instead of sending normal requests, attackers could create a query that can become exponentially more complex with almost no effort, thereby overloading the system and leading to a denial of service (DoS). This could also happen by mistake if a normal user doesn’t know how to appropriately craft a query.
When types reference each other in GraphQL, it opens the server to the possibility of a cyclical query that could grow exponentially, pin resources, and bring the server down.
For example, a GraphQL implementation could have a circular relationship defined as follows:
type Blog {
comments(first: Int, after: String)
}
Type Comment {
blog: Comment
}
Type Query {
blog(id: ID!): Blog
}Inasmuch, you can query both the comments in a blog or a blog of comments, allowing a bad actor to construct an expensive nested query that can exponentially increase the amount of objects loaded. For example:
query nefariousQuery {
blog(id: “some-id”) {
comments(first: 9999) {
blog {
comments(first: 9999) {
blog {
# ... repeat
}
}
}
}
}
}The solution: Setting max depth can mitigate GraphQL attacks leveraging depth and complexity. With that said, the query depth is not enough to know how expensive a query will be in some cases. A query may include a certain field that takes longer to resolve, making its computation more expensive.
A technique known as query cost analysis can prevent this by assigning costs to fields, which ensures the server can reject fields if they’re too expensive. However, before you spend time on implementing this mitigation, make sure you really need it. If your service doesn’t have expensive nested relationships or can likely handle the load, prevention may not be necessary.
5. Refine Your Batching
The challenge: A key benefit of GraphQL is query batching, the ability to combine a group of requests into a single request. But without preemptively establishing secure constraints, query batching in GraphQL can lead to profitable opportunities for attackers.
For instance, the following code snippet is a batched query used to request multiple instances of a user object, which could facilitate a brute force attack:
query {
user(id: "101") {
name
}
second:user(id: "102") {
name
}
third:user(id: "103") {
name
}
}Attackers could expand this to enumerate every possible user over a single request. This is a type of brute force attack, specific to GraphQL, that usually allows for a less detectable exploit because you can request multiple object instances in a single request. In contrast, a REST API would require an attacker to send a different request for each object instance.
Because query batching appears as a single request, abuse of it could bypass common appsec tools like web application firewalls (WAF), runtime application self protection (RASP), intrusion detection and preventions systems (IDS/IPS), or security information and event management systems (SIEMs).
The solution: In order to adequately mitigate GraphQL query batching attacks, one option is to add rate limiting on objects. For example, you could track how many different object instances the caller requested and block them after requesting too many objects.
Another option to prevent this type of attack is to exclude sensitive objects from batching. Attackers would be required to try another route to accessing them like a REST API, which would make one request per object.
Alongside both of these methods, limiting the number of operations that can be batched and run at once can also help.
6. Have Input Validation Done Early
The challenge: GraphQL is not that different from other API architectures. Applications using GraphQL are still prone to the same common vulnerabilities we all know and dread. It’s up to the developer to properly validate and sanitize input to prevent malicious requests.
For example, let’s look at how we might exploit an OS command injection vulnerability via GraphQL.
Consider an online retail store that has an operation to check the inventory count of a particular item. For historical reasons, the server queries a legacy system using a shell script with itemId, vendorId, and color as arguments:
inventorycount.sh 80 200 redThis script outputs the inventory count of the item, which is returned in the request. Since the application does not implement any defenses, an attacker can input an arbitrary command as follows:
red ; env ;The resulting GraphQL query would look like this:
query {
inventoryCount(itemId:80, vendorId:200 color:”red; env ;”,)
}This query subsequently returns the contents of environment variables, which could contain secrets and other sensitive information.
Example response
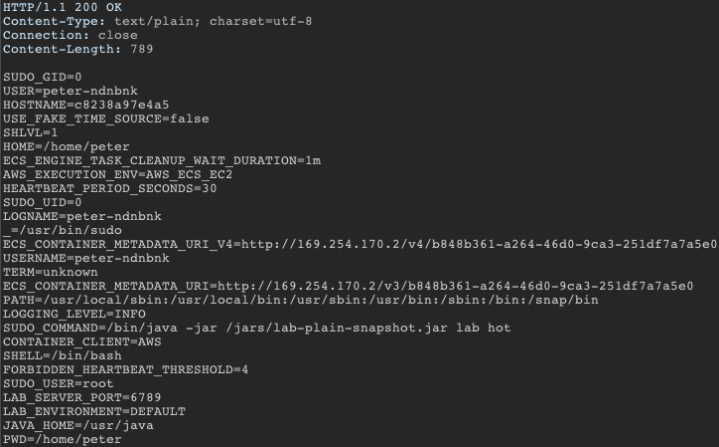
The solution: As a general rule, input validation should happen as early as possible in the data flow. Even if input is sanitized and validated, it shouldn’t be used to give a user control over data flow. All incoming data should be validated using GraphQL scalar and enum data types.
You can also write custom GraphQL validators for more complex validations. GraphQL query allowlisting can also reduce potential impact by telling the server not to let any query pass that isn’t pre-approved. But if you find yourself still losing sleep or descending into a complexity spiral, we naturally recommend using our next-gen WAF (formerly Signal Sciences).
Moving forward
GraphQL is a new standard for interacting with APIs — which means we need to be mindful of the security implications and attack surface it brings along with it.
Fundamentally, building secure software requires an understanding of underlying security principles of whatever technology you’re building upon. An awareness of the security flaws that can be introduced at any stage of the development cycle can significantly reduce headaches and incidents in the future, whether for projects using GraphQL or otherwise.
We know that security is best practiced using defense in depth. In the event that a security control fails or a vulnerability is introduced, GraphQL support is now in beta for our next-gen WAF (formerly Signal Sciences).
Global Security Research Report
Prepare your team for the future of security, Fastly’s global research survey of more than 1,400 key IT decision makers in large organizations spanning multiple industries globally finds that despite the news of ever-evolving, advanced threats, organizations are most concerned about straightforward attacks like data breaches, malware and phishing. Download the report