
We hosted our first-ever customer summit in June of last year, with the goal of bringing together our customers and the people who build our products to discuss web performance, Varnish, and the future of Fastly. There were a variety of interesting presentations, including GitHub’s Joe Williams on mitigating security threats and Network Engineer João Taveira on building and scaling the Fastly network.
Systems Engineer Ines Sombra’s Altitude 2015 talk, “The fallacy of fast,” reflects on the shortcuts we tend to take when we iterate quickly, both within our organization and our own codebases.
Ines summed up her talk with a tl;dr (too long; didn’t read):
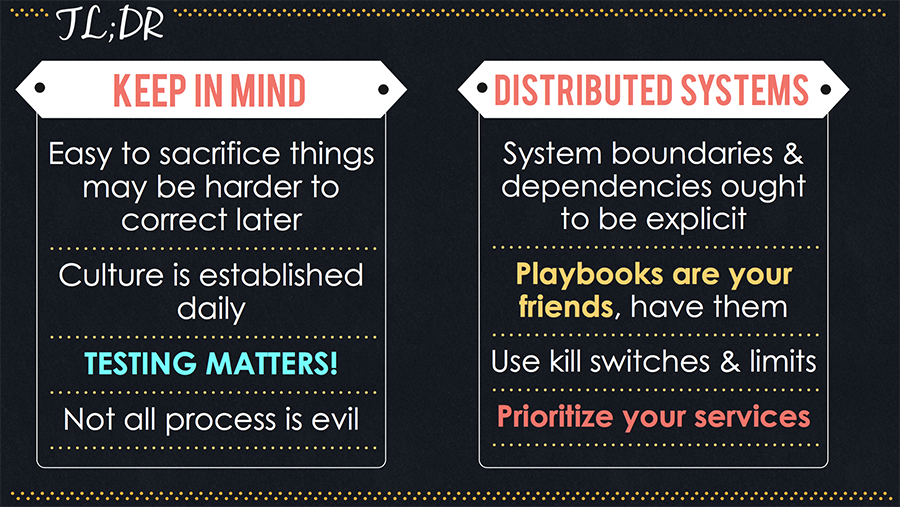
The talk focuses on two main areas: common mistakes and what really matters.
Common mistakes
Some mistakes made during the development process can accidentally de-emphasize the stability of your system. In an effort to get something done quickly, we tend to unknowingly sacrifice overall quality and this can happen with both large and small organizational decisions.
Below are some common mistakes:
De-prioritizing areas, such as:
Testing
Cutting corners on testing carries a hidden cost. If you don’t prioritize testing, you may be sending the message that quality is not that important to your organization.
Test the full system, including client, code, provisioning code, etc. E.g., if you have a system set up with Chef, the cookbook that sets up your application needs to be tested.
Code reviews are important but they aren’t a substitute for tests.
Monitor how tests perform over time — the quality and breadth of your tests tend to correlate to application stability.
Operations. Every system has operational tasks associated with it. As Ines noted, “When you cut corners, everything will screw you over at the worst possible moment and you will have to fix it on the spot.”
Taking automation shortcuts will come back to haunt you.
Playbooks are a must, and we emphasize them within Fastly as well. Make sure your applications are self-documented and carry good playbooks, which explain how your system gets configured, where things are, inter-system dependencies, and how the system looks when it’s operating correctly (and when it’s not).
Release stability is often tied to system stability. Ines cautioned: “Iron out your deploy process!” A lot of manual steps are not going to be as stable as a mechanized process.
Insight / Observability
Prioritize monitoring. Your system is not production-ready if you punt on monitoring. It shouldn’t be in production if you don’t have a way to track it over time.
Alert fatigue has a cost — when you get used to alerts popping up you get desensitized and start ignoring them. This can be dangerous; don’t let it get that far.
Link alerts to playbooks to make sure remediation steps are documented. This is especially helpful for new hires on call.
Don’t ignore error handling and security. You can have catastrophic failures because errors don’t get bubbled up effectively.
Knowledge
The inner workings of data components matter. Learn about them.
System boundaries ought to be made explicit. The dependencies of your system should be made clear, e.g. if your system depends on a database you need to have an idea of how this database works.
Deprecate your go-to person. Having a person with certain knowledge is dangerous. Use playbooks to share knowledge among people in your organization.
What we’ve learned:
Don’t sacrifice tests. Test the full system, including the provisioning code.
Service ownership implies leveling-up operationally, especially with microservices: you have responsibility over the services you own.
Architectural choices made in a rush have a long life, and could lead to increased difficulty to change things when you actually need it.
What matters
Mind your system design.
Simple and utilitarian design takes you a long way.
Use well-understood components. They’re well-understood and boring for a reason — you can trust them.
Use feature flags and on/off switches (test them!). These let you do graceful degradation.
Mind your system limits.
Rate-limit your API calls (especially if they are public or expensive to run).
Instrument / add metrics to track them.
Rank your services and data. What is critical to the functioning of your system, and what can you drop? E.g., shutting off expensive / noncritical services can provide some stability during an attack.
Capacity analysis is not dead, and offers value even if your app lives on the cloud. The exercise of thinking about resources, limits, and how they tie to customer value is a worthwhile activity.
Mind your system configuration.
System assumptions are dangerous. E.g., if you expect your system to always be colocated with another system, that dependency must be undone when you want to separate them (and most times you’ll forget it’s there).
Standardize the way you do system configuration (for example: using data bags vs config files to do a similar job is confusing).
“Hardcoding is the devil.” Something that makes a hardcoded assumption will come back to bite you later, especially when it comes to localhost.
Distrust is healthy.
Distrust client behavior. “It’s not like everyone is out to get you and you should be paranoid,” Ines said. “But sometimes your clients, even if they are internal, can actually hurt your application.” Consider the possibility of unexpected behaviors so you can guard your application while in design.
Decisions have an expiration date. Periodically re-evaluate them, because “past you was much dumber.” Just because you decided on a solution years ago it doesn’t mean you shouldn’t re-evaluate it.
A revisionist culture produces more robust systems. Resisting means you have a problem.
What we’ve learned:
Keep track of your technical debt and regularly repay it.
Actively lower the risk of change with tools and culture. Tests and continuous integration allow you to iterate quickly and safely. System quality is our goal, and we need tools and processes that allow us to iterate towards it.
You can watch the video of Ines’ talk here, and read the full recap of Altitude 2015 for more information about the event. We invite all of our customers to join us for this year’s Altitude summit on July 21 in San Francisco — RSVP to reserve your spot.