
As our lives have shifted to COVID-19 driven social distancing, many of us are working from home, doing remote learning, or spending our social time connecting via the internet rather than face to face. It has become obvious that the internet is an essential service that helps hold together our new reality. I marvel at how the internet has grown from a 1990s network that was underpinned by a handful of 45 megabit/second (or worse!) backbone connections to one that serves over a billion individual endpoints each, often at much higher speeds.
We arrived at where we are today thanks to evolution driven by many technologies such as better fiber optics, the rise of cloud computing data centers, Content Delivery Networks, standards that coordinate strong security, better end user hardware, and improved networking protocol implementations. However, that growth has not been uniform for every user. While some locales have fiber to the home with multi-gigabit speeds available, others have wireless bandwidth with unpredictable performance due to local congestion, and still others must rely on aging cable or DSL technologies introduced a decade or more ago
Right now, the advent of HTTP/3 and QUIC serves as another milestone in the growth of the internet. These technologies will address some of the weak spots of their predecessors and allow us to gracefully handle ever more diverse levels of connection quality and on-board more people to the modern internet.
As the internet grew, what was left behind?
This post focuses on these so-called long tail scenarios and the role HTTP/3 could play in making them better. Throughout the post, we’re defining long-tail scenarios as the situations where performance is dramatically worse than the average case. Environments with long tails experience what feel like outlier events surprisingly often. The dinner menu has a 2x cost differential between the most and least expensive entree. This is a short tail. The wine list, however, offers just a few super premium bottles of wine, but they're 100x more expensive than the lowest-cost offering. They are a long tail. Due to the extreme nature of long-tail events they are worth thinking about even when they don’t represent a large fraction of the overall traffic.
It is important to note that the tail is not made up of randomly occurring connections. Some people (or their connections) are more likely to be in the long tail than others. A platform that operates with a long tail is systematically disadvantaging those people. While these connections are loosely correlated with particular people and their environments, it isn’t easy to identify in detail what is causing the problem because the performance obstacles are caused by a variety of local issues. Among many possible root causes, the problems are associated with specific internet paths, congested urban radio spectrum, expensive rural links that are too small, and physical obstructions like trees, buildings, or even having a desk next to the microwave oven.
While tail events are, by definition, relatively uncommon, improving them has a positive disproportionate impact on performance because shortening the tail makes the marginal difference between a usable internet and an unusable one. Such changes make a bigger impact than small improvements to the average user of a service. This is where HTTP/3 is focused.
The connections that HTTP/2 left behind
HTTP/3 is primarily aimed at addressing the use cases HTTP/2 did not adequately address when it superseded HTTP/1. These cases are the tail of HTTP/2 performance.
A brief recap of HTTP/2 design principles is in order. For all of its bells and whistles, HTTP/2’s primary contribution was the introduction of multiplexing concurrent HTTP exchanges onto a single TCP stream. This property allowed more efficient use of TCP congestion control while reaching effectively unlimited parallelism. It also eliminated the previously common phenomenon of important resources being “head of line” blocked by the transfer of less important resources. Put simply, HTTP/2 uses one easy-to-manage TCP connection to replace the work and overhead of many HTTP/1 connections.
The problems with coordinating a fixed number of parallel TCP sessions were the primary limitations of HTTP/1. HTTP/2 is indeed effective at addressing them. My colleague Patrick Hamann made a presentation in 2016 that was characteristic of many HTTP/2 evaluations at that time. It showed page load times at his organization to have improved by 29% on mobile and a more modest 5% on desktop when transitioned to HTTP/2.
Both the desktop and mobile metrics were welcome news, but the discrepancy between them is a good illustration of targeted optimization. Mobile networks are less consistent than desktop networks and, at that time, had a higher fraction of long round trip times. HTTP/2 had a greater impact on the poorer conditions. A perfect network (perhaps a connection between two virtual machines on the same physical host) will probably do just fine with HTTP/1 because bandwidth is high, packet loss is low, and latency is trivial. In truth, many real world conditions were also good enough, which is why Patrick’s data showed modest gains for desktop but better gains for mobile, which was an under performer. HTTP/2 was meant to address the long-tail that had limited bandwidth, demand for parallelism, and higher latency.
Another one of my colleagues, Hooman Beheshti, took this analysis further in his 2016 study. Among the many insightful contributions in this work is a characterization of HTTP/2’s performance under packet loss. Hooman illustrates that the higher the packet loss the worse HTTP/2 performs in comparison to HTTP/1. This is mostly because of HTTP/2’s use of just one TCP connection for all exchanges compared to HTTP/1’s use of one connection per concurrent exchange and the interaction of packet loss with TCP’s congestion control and in-order delivery guarantee. The in-order guarantee requires all of the data to be delivered to the TCP connection in the order it was sent, so if there is a packet loss, all of the data on the connection after that loss must wait for the loss to be repaired before HTTP can see it. The multiple TCP sessions of HTTP/1 are generally able to proceed in face of the loss as the impact of recovery is limited to a single HTTP transaction, but HTTP/2 has only one connection and all of the HTTP transactions multiplexed on it are impacted by the recovery and therefore the effect of the same amount of loss is felt more widely in HTTP/2.
The dynamic between HTTP/2 performance and packet loss was understood during the development of HTTP/2, but high packet loss conditions were thought to be a bigger and harder problem to solve and was ultimately left for later. HTTP/2 had effectively set the table for HTTP/3 to address the connections of lowest quality.
Hooman provides us some additional data to start thinking about the size of the problem. Specific conditions are going to matter a lot (indeed inside the tail of any distribution lives another distribution with its own tail - as they say, even the 1% have their own 1%), but as a rough rule of thumb, connections with less than 0.5% packet loss benefited from HTTP/2, those with between 0.5% and 1.5% loss benefited roughly as much as they sacrificed by using HTTP/2, and those with more than 1.5% loss were harmed by the upgrade.
Optimizing the HTTP/2 tail, these high packet loss scenarios became the design goal of HTTP/3. This is the unfinished work of HTTP/2.
Hooman goes on to illustrate that 75% of Fastly edge connections at that time fell into the “improved by HTTP/2” range of packet loss and the remainders were split roughly evenly between hurt and unchanged. This was definitely a net win with 6 times as many HTTP transactions improved as harmed by the transition - but an obvious set of connections still requires attention.
HTTP/3, QUIC, and In-Order Delivery
A thorough analysis of HTTP/3 performance will need to wait for a variety of robust implementations to be deployed in diverse environments. But for now, let’s look at the theory of operations of how HTTP/3 intends to make an impact.
HTTP/3’s goal is to restore one desirable property of HTTP/1 without bringing back the other undesirable attributes of that protocol. Specifically, that the scope of a single packet loss-driven repair delay should only apply to a single HTTP transaction. It needs to do so in a way that all the transactions coordinate their aggregate transmission rate. This effectively blends the best property of HTTP/1 with the successful properties of HTTP/2.
In order to achieve this goal, we need a little help. That’s where QUIC comes in. HTTP/3 uses QUIC similarly to how HTTP/2 frames itself on TCP, but without the restrictions of TCP’s in-order delivery. For HTTP/2, a header is periodically emitted with a stream ID and a length which indicates that the next few bytes, indicated by the length, belong to a particular HTTP transaction. In HTTP/3, instead of placing headers within the data stream, each QUIC packet contains a similar stream ID at the packet layer. The difference is that TCP enforces the “in-order delivery” property on all the streams within the TCP session, while QUIC only enforces it within one stream at a time.
This figure illustrates the delivery pattern for both an HTTP/2 and an HTTP/3 connection. In each case the connection is made up of 5 mostly parallel HTTP transactions. Longer arrows indicate slower delivery times. Shortly after starting, each connection suffers a single packet loss to the second HTTP transaction in the connection. HTTP needs to suspend some data delivery to ensure the in-order property of the HTTP transaction. Transactions that continue uninterrupted during recovery are represented by solid lines, while dotted lines represent time spent recovering instead of sending data.
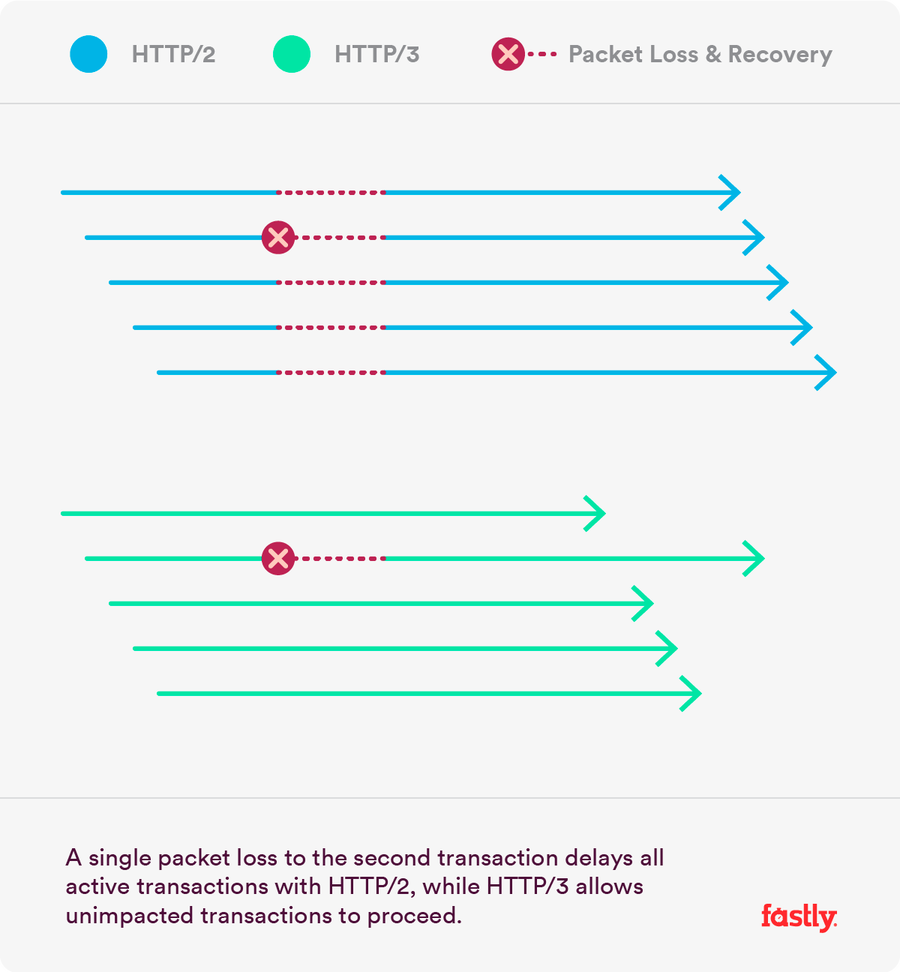
Logically, refining the scope of in-order delivery to be limited to just the stream rather than the whole connection is a simple distinction to articulate. Implementation requires the creation of QUIC, a entirely new transport protocol, to achieve the desired refinement. Happily, a number of other useful properties like full transport layer authentication and faster startup have also been introduced along the way to further improve the return on investment in a new protocol.
The tail matters independent of the median
Using HTTP/3 and QUIC to target packet loss performance isn’t a scenario where a “rising tide lifts all boats.” While it is targeted at the worst performing connections, HTTP/3 might not significantly affect performance for the average connection — or even affect it at all. This is especially true if the comparison HTTP/2 session has almost no packet loss and is already using best practice recommendations for TLS and TCP configurations. However, even those connections will benefit from improved startup times, better security, and an ecosystem that should be easier to evolve from than our current state of TCP.
Focusing effort on protocols that create even a marginal improvement for the tail of connections may mean the difference between a person using video on a conference call, supporting HD video, or even, in the case of managing audio dropouts, making a workable phone call. While some internet functions such as file download times degrade gracefully, these are scenarios where the improvement for the lowest performing clients determines viability — you either have the ability to use these functions or you do not.
Future internet optimizations are likely to be similarly targeted at making the internet good enough in more situations, rather than making it run just a little bit faster for the majority of connections that are already good enough.