
Altitude SF 2017 brought together technical leaders from Reddit, the ACLU, TED, Slack, and more to explore the future of edge delivery, emerging web trends, and the challenges of cloud infrastructure and security. In this post, we’ll share Daniel Ellis’ talk on how Reddit built and scaled r/place, their real-time April Fools’ project.

Daniel Ellis, Senior Software Engineer, Relevance, Reddit
At its core, r/place’s motto was: “Individually you can create something, together you can create something more.”
r/place was a globally shared, 1,000 x 1,000 pixel canvas on which each user could paint a pixel at time:
Everyone painted on the same grid together, with one catch: you only got one pixel every five minutes. You couldn’t draw anything on your own — you had to draw with other communities. (“When you joined with other people you could make something a lot better.”)
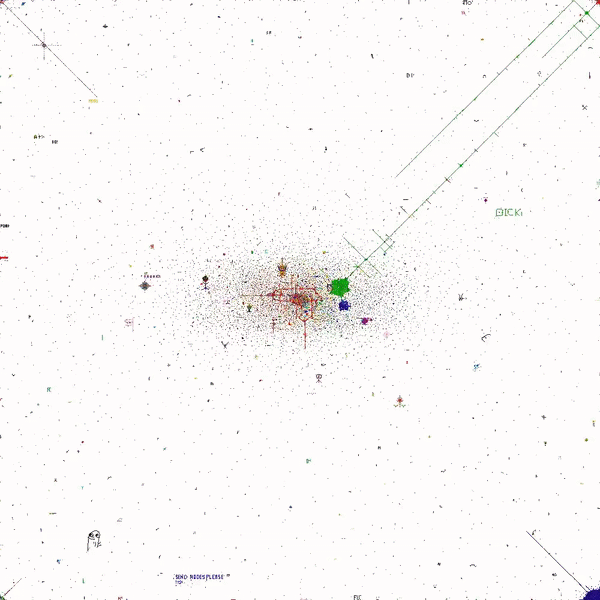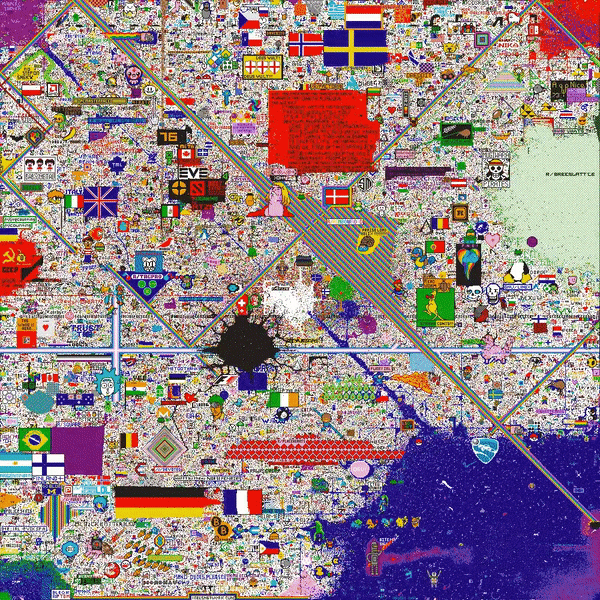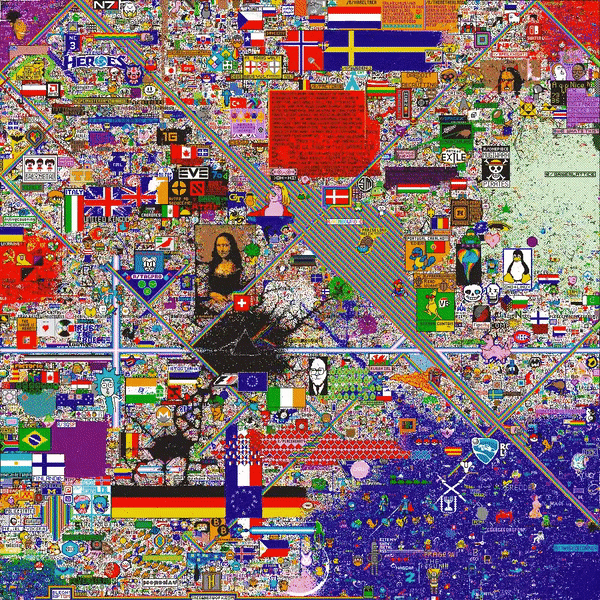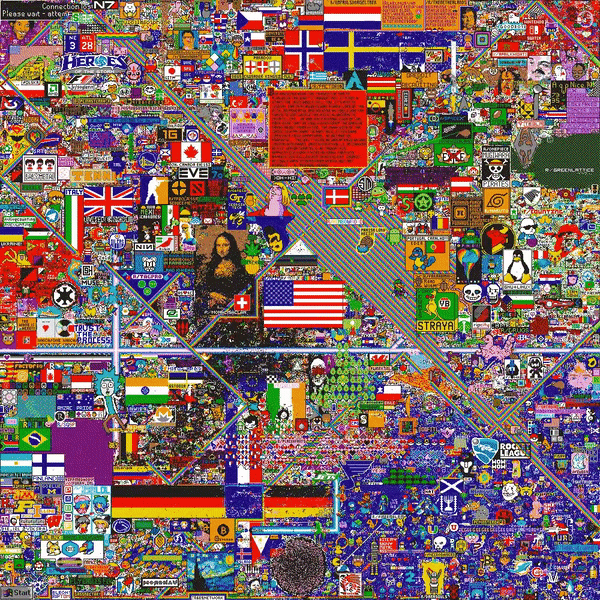
A lot of subreddits came together, resulting in a richly populated final canvas filled with country flags, memes, and the Mona Lisa:

In total, the project had 1.1 M unique users, 150,000 concurrent users, 16.5 M tiles placed (enough to cover the board 16 times over), and was finished in 72 hours.
Challenges for building r/place
There were numerous challenges to take into account when approaching this project:
There was only one shot to launch, and the project only lasted a few days. With a set deadline of April 1, there was no pushing the launch back. And, the project had to be ready to scale and in good working order immediately, or else no one would use it.
Keeping the main site unaffected. The team had to ensure the rest of reddit.com remained in good shape.
A small team (3-4 engineers), with the rest of reddit.com to work on.
They had no idea what users would do with it, which was more of an ideological challenge than a technical one; they were offering up an entirely blank canvas for users to draw on: “The idea of giving the internet free rein over that can be scary.”
With those challenges in mind, the team tracked their stress levels over time:
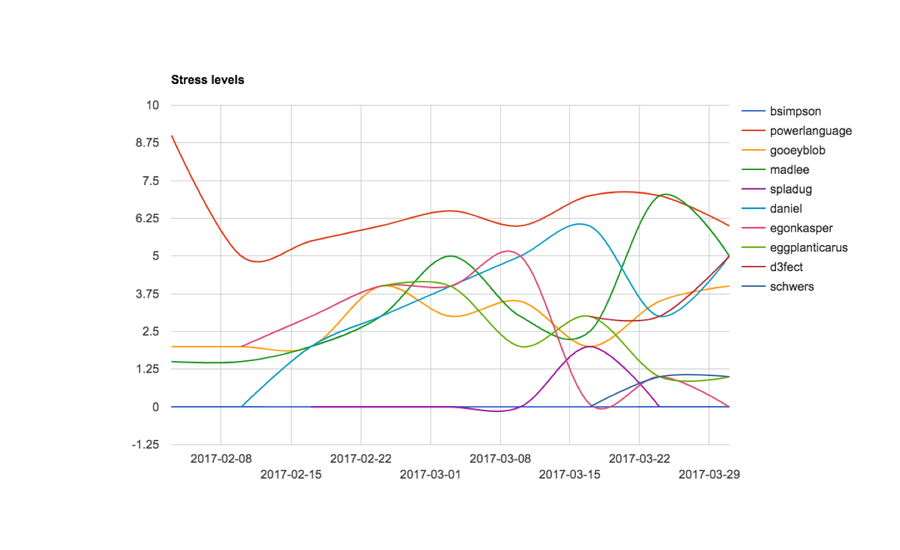
The chart gave the team a sense of where to put more focus or get more people on board, i.e., “The backend people were a little more stressed.”
How it worked
Reading the board was “the simplest” part of implementing r/place: they cached the board on Fastly’s CDN with a time to live (TTL) of one second (this was to reduce load on the data store as much as possible — a little bit of latency was fine because updates were also streamed via websockets to the user).
The second major part was drawing a pixel: a request came in and passed through the CDN and load balancer untouched, and the application server would check to make sure the user was logged in, the account was of the right age, and that they hadn’t placed a pixel in the required amount of time. If all that checked out, an update was sent to a few places:
A websockets cluster (a fan-out exchange from RabbitMQ) that let people’s clients get that message back and display it onto the board for real-time updates.
The event collector (a kafka pipeline), allowed the team to do an analysis as well as release the data to the community (who created heatmaps, among other creative endeavours) once the game was finished.
Redis, where a bitmap of the board was stored in one key (more on this later).
Cassandra, where the actual data about the user who drew the pixel was stored, which allowed users to click a pixel to see when it was placed and by whom.
Backend choice: Cassandra v Redis
There was some back and forth over whether to use Cassandra or Redis for the actual storage of the board; each choice had its pros and cons:
Cassandra was the initial choice — it serves a significant portion of reddit.com, therefore having the benefit of being a familiar technology which had plenty of in-house expertise — and offered a 36 node cluster, about 96 TB of data, 90,000 reads/sec, and 30,000 writes/sec.
However, Cassandra did not fit this project’s data model very well: the team needed to have one million records of individually addressable pixels, and then needed to be able to return all of those pixels when someone loaded the board; with Cassandra, this took the form of a million columns in a row. Further, the use of Cassandra presented a “double-edged sword:” they knew it’s a good data store because it’s used all the time, but if something happened with the project it was potentially a way to hurt the main site (by using the same Cassandra instance to run r/place and reddit.com, they risked bringing down both).
Redis, on the other hand, fit the data model well — it was “exactly what they needed.” It’s not used much for the main site (Redis is used for counting, so active users can be seen in the sidebar), so didn’t carry the potential of affecting reddit.com if something went awry with r/place. However, since it’s not used a lot, it was more unfamiliar than Cassandra.
Board format
For efficiency's sake, the team cut the palette down to 16 colors, storing them in a four-bit unsigned integer — a bitmap that the front end could interpret as red, green, and blue.
Here’s a scaled-down example:

On the left you see the data as stored and transmitted, and on the right how it “wraps around” when placed on the grid. After a write, a particular place in the bitmap was addressed based on the coordinates (x + y * canvas_size), which meant they could store pixel information for one million pixels in 500 kilobytes of data. This value could be made even lower by gzipping when downloading the data in the browser.
Setting a pixel: SETBIT v. bitfield
Initially they looked at SETBIT, a Redis command that lets you set individual bits, for enabling users to set pixels on the board. They’d run SETBIT, the name of the key, the offset they’d want to write into the key, and the value. In action, it would look something like this:
SETBIT canvas 100 1
SETBIT canvas 101 1
SETBIT canvas 102 1
SETBIT canvas 103 1Repeating the command four times wasn’t ideal — another downside was that if users tried to set their same pixels in the same spot, a random mix of colors might result, something that could be addressed by making it atomic, like the concept of transactions in SQL.
The team eventually settled on BITFIELD, which is able to operate with multiple bit fields in the same command call. BITFIELD also shortened the command to two lines — when the pound sign was added, Redis automatically calculated the bit position — as seen in the following example:
BITFIELD key SET TYPE OFFSET VALUE
BITFIELD canvas SET u4 #25 15Getting the pixel
The team didn’t need to use BITFIELD at all for the GET, instead using a simple GET, and letting the client handle parsing the pixels. The code was a bit more complicated since there are no unsigned four-bit integer arrays in JavaScript, so they had to parse it as an eight-bit integer array and do their own bit shifting, but overall this was small in the grand scheme of r/place implementation. (Check out the slides to see the command in full.)
Load testing for the real world
To make sure everything would work, the team set up load testing; they scaled up their network so r/place could handle 180,000 writes per second, which was more than they’d need (for context, all of reddit.com gets about 30,000 requests per second).
They also load tested with a mixed workflow more conducive to the real world. Initially load testing had been done with SETs only, but adding one GET of the key per second caused a huge hit in the capacity for SET operations, which made sense: “A SET is pretty small — setting a single pixel value — but a GET is getting them all!” 10 reads/second were added to the mix, which resulted in a drop of 20,000 writes a second (i.e., adding 1 read/sec meant a loss of 2,000 writes/sec).
At this point caching seemed like a good idea, but they also tested board load time, which had only been tested internally at a small scale. The board was loaded with “a million random pixels,” immediately resulting in what had been a sub-second load time in Cassandra jumping to over 30 seconds. For Redis, loading the board translated to getting a single key, which was more like 10ms. This load test was the final deciding factor for Redis, and also illustrated how it’s important to incorporate real-world data when testing.
Caching: a multi-tiered approach
Fastly’s CDN was the “first line of defense,” and adding it was as simple as adding a Cache-Control header with max-age=1 — they wanted to keep a low TTL to ensure fresh content while still limiting the traffic back to Redis to just one request a second.
If data in Fastly was stale, they’d fall back to the server-side cache — each application server had a local memcache instance for this purpose. Finally, if neither of those caches had the data, they’d fall back to Redis. Changing caching was controlled with GET parameters (though they ended up not needing to). Everything took “very little” actual code but paid off in terms of reducing load to the system.
Takeaways
Building and scaling r/place inspired the following sage advice:
Have knobs you can tune, like cooldown timers — they ended up running into trouble with the RabbitMQ cluster, so they changed rate of throughput for updates while diagnosing.
Have switches you can flip — it’s nice to have things you can turn to without shutting everything off (they wouldn’t have wanted to shut down the entire game because a piece of the infrastructure wasn’t working properly).
Load test everything with real-world data — in Reddit’s case, this showed the need for caching and another backend store — had they just tested simple reads and writes they might have missed problems arising from disparity in sizes for GETs vs SETs.
Use power principles — there wasn’t much time to execute the project, so anything they chose to implement needed to have a disproportionate payoff (e.g., there was a bug that “stayed until the end” but at the end of the day, it wasn’t a big enough deal to delve into).
Watch the talk below, and stay tuned — we’ll continue to share customer stories from Altitude (and beyond).