

This is part two of a series on DDoS attacks. Check out part one here.
Last fall, we took a look at the evolving DDoS landscape, offering a sense of what attack sizes and types are out there to help better inform decisions when it comes to securing your infrastructure. At Fastly, we combine security research with network engineering best practices to give us unique insight into both attack trends and the most effective mitigation tactics.
In this post, we’ll share:
An inside look at how we protect our customers from attacks
Lessons learned from a real-live DDoS
Our recommended checklist for mitigating attacks
Keeping an eye on DDoS: research + network
At Fastly, we keep track of DDoS activity and methodology both by observing traffic patterns on our network as well as conducting research. This two-fold method keeps us apprised of new methods as they arise, helping us contribute to the larger security community while protecting our customers.
Research: the anatomy of an attack
Our security research team uses honeypots — a mechanism set to detect, deflect, or counteract attempts of unauthorized use of information systems, and specifically in this case a modified version of open source tool Cowrie — to keep track of who’s probing our systems, and what they’re trying to do. We tested how an array of unsecured IoT devices would perform on the open web, with some alarming results:
On average, an IoT device was infected with malware and had launched an attack within 6 minutes of being exposed to the internet.
Over the span of a day, IoT devices were probed for vulnerabilities 800 times per hour by attackers from across the globe.
Over one day, we saw an average of over 400 login attempts per device, an average of one attempt every 5 minutes; 66 percent of them on average were successful.
These are not sophisticated attacks, but they’re effective — especially when you have 20,000 different bots at your disposal, trying to brute force their way in. Unless you change devices passwords and get them off the network, attackers are going to use them to break in and take over. It’s like the 90s all over again — this is a huge backslide in terms of securing the internet.
Using honeypots to identify botnets is nothing new, and remains a valuable method to identify attack capabilities used in the wild. By studying the malware used in these attack tools, defenders can identify attack traffic characteristics and apply that in remediation. For example, knowing the random query strings that a bot could use during an HTTP flood can be useful to selectively filter those attack bots from legitimate traffic.
At 665 Gbps, the aforementioned Mirai attack on Brian Krebs was one of the largest-known DDoSes at the time (it was surpassed by the 1 Tbps DDoS attack on hosting company OVH later that same week). Krebs, a former Washington Post reporter, created his “Krebs on Security” blog to explore stories on cybercrime. He began covering the Mirai attacks, which at the time were under the radar — his reporting efforts revealed who was behind the attacks, and in retaliation they started attacking his blog, ultimately taking it offline. A few days later he wrote about the democratization of censorship: this isn’t the first time people have used denial of service attacks to try to silence someone they disagreed with. The sheer scale of the attack led to dialogue that wasn’t happening before, including asking questions like, “Are we thinking about these things in the right way?” The Krebs attacks forced the discussion.
NetEng: protecting the network
For a real-world look at DDoS, we’ll take as an example a March 2016 attack on our network. At 150 million packets per second (PPS) and over 200 Gbps, the shape-shifting attack was a mix of UDP, TCP ACK, and TCP SYN floods, with internet-wide effects. We saw upstream provider backbone congestion as well as elevated TCP retransmissions to far-end clients. When you see this egressing your network without actually saturating your provider interconnects, several possible causes may be responsible: that backbone provider may be experiencing issues, or the source of the congestion could be even further upstream towards the source of the attack. During the attack we saw significant retransmits and our network wasn’t congested, suggesting the upstream link was congested and not all the attack traffic was reaching us. So, in all reality, the attack was quite likely more than 200 Gbps.
Minutes after the attack started, we engaged our incident command process, as well as our security response team to observe the attack characteristics we highlighted above. Both external and internal communications are critical: our next step was to post a customer-facing status, which we continued to update throughout the event. This particular attack was uniquely long-running, even expanding into our Asia POPs the next day. Our Incident Command (IC) team used bifurcation and isolation techniques to absorb the attack. We left the mitigations in place, and eventually the attackers gave up.
In an ongoing effort to monitor attack trends and patterns, we pull data from Arbor Networks to track peak attack size by month. As you can see, the March 2016 attack — with a huge jump to about 600 Gbps — didn’t exactly follow the trend:
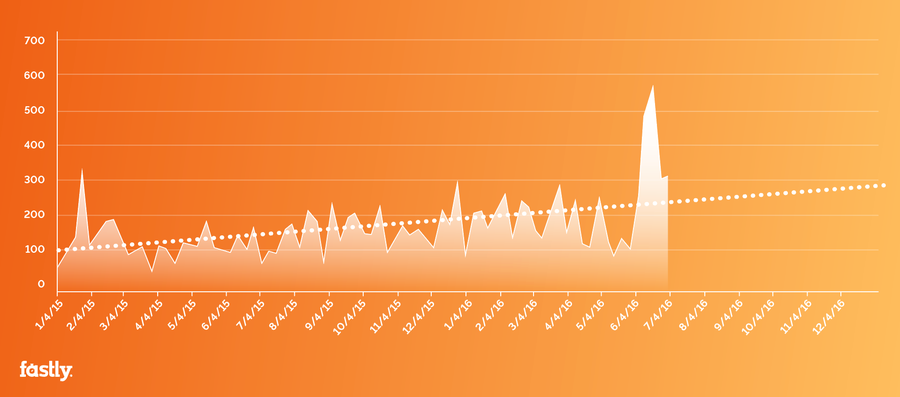
Source: Arbor Networks’ Worldwide Infrastructure Security Report
The dotted trend line is what you’re expecting and planning for. Because that attack was far bigger than we expected, it forced the botnet tracking and DDoS countermeasure community to start talking in different terms: we had to re-evaluate mitigation bandwidth capacity, and think about multiple, concurrent large-scale (500+ Gbps) attacks. The conversation became global, spanning between providers, CERTs, and other members of the cyber defense community all around the world.
A DDoS retrospective + lessons learned
Our processes during the March 2016 attack were two-fold:
Incident Command ensured business continuity — ongoing CDN reliability and availability.
Meanwhile, our security response team engaged the security community to identify flow sources, bad actors, malware, and attack methods and capabilities that might be coming at us in the future.
We learned some valuable lessons, both in terms of what went well and future areas to work on. The following takeaways from the March 2016 attack now form a checklist for preparing for future attacks:
Have pre-planned bifurcation techniques, which proved invaluable in time to mitigate, empowering us to react quickly, giving us the agility to split traffic to give us room to maneuver and empowering our teams to know when to invoke those techniques (and what the consequences are).
Enhance mitigation options with a well-designed IP addressing architecture.
Separate infrastructure and customer IP addressing, as well as DNS-based dependencies. This is a best practice for any provider: you want to be able to keep your infrastructure distinct from customer addresses and be able to reach your equipment if you need to make changes.
Continued threat intelligence gathering to understand future TTP vectors.
An emphasis on team health for long-running events: given the duration of the March 2016 incident, it was critical to consider shift rotations and food. No one can work for 24 hours straight.
Keep in mind — a DDoS can often mask other system availability events. Since they’re so noisy and all-consuming, your team might be entirely focused on the DDoS while there’s something else going on.
Keep calm + mitigate
As outlined in part one, the reason for a DDoS can be ideological or economical. Sometimes someone wants to prove that they can take you offline. You don’t actually know — you have no idea why you’re being DDoS’ed. So don’t guess; there’s no point. Similarly, you can’t afford to take the time to perform attack tool forensics beyond a rudimentary stage, that takes too much time, a precious commodity during an availability attack. You should also look for a provider who can act quickly during your time of need. At Fastly, our philosophy is to offer help when our customers need it, without price gouging or wasting valuable time negotiating contracts. Finally, as Fastly CEO Artur Bergman wisely notes: don’t panic. Help is out there. Create a plan and stick to it. With the right systems, checklists, and partners in place, you absolutely can weather a DDoS attack.
Stay tuned — in the next post we’ll take a look at how our customers are defending against DDoS attacks and other nefarious activities. And, for more on how to mitigate DDoS attacks, watch the video of last year’s Altitude NYC talk, below.