
At Fastly, we continue to invest in the security, performance and efficiency of our systems. In addition to migrating from OpenSSL to BoringSSL, this post details the journey of improving the security of TLS private keys and improving the performance and efficiency of TLS handshakes along the way.
TLS Private Keys
The TLS protocol employs a pair of keys, one public and one private to authenticate and secure connections. The private key (known to the server), allows the creation of a digital signature used during the TLS handshake. This signature can be verified using the public key known to the client. This encryption scheme, known as Asymmetric Encryption, is the foundation of establishing the trust and security of a TLS connection.
No surprise, the private keys are meant to stay private. A disclosure of a TLS private key could allow an unauthorized actor to create these digital signatures and impersonate the server. By safeguarding the private key, this establishes trust between the client and the server.
Information disclosure vulnerabilities (CWE-200) threaten this trust and security, as it could lead to leaking the private key to an unauthorized actor. Given that the server holds private keys in process memory to terminate TLS connections, an information disclosure vulnerability in the server could expose process memory and disclose the TLS private key to an attacker. Heartbleed is a great example of this.
Fastly adheres to industry best practices such as regular software updates and patches to protect against attacks. Recent developments to our TLS stack have introduced even stronger protection from this class of vulnerability; Here’s how.
Neverbleed
In Linux, one process's memory address space is fully isolated from another, such that a memory disclosure vulnerability in user-space process A, cannot disclose memory from process B. This is a guarantee upheld by the kernel. Neverbleed takes advantage of this property.
Neverbleed is an OpenSSL engine that stores and runs RSA/ECDSA private key operations in an isolated process, thereby minimizing the risk in the case of a memory disclosure vulnerability in the (public facing) server. The server process communicates with the Neverbleed process via a unix socket using a simple binary request/response protocol.
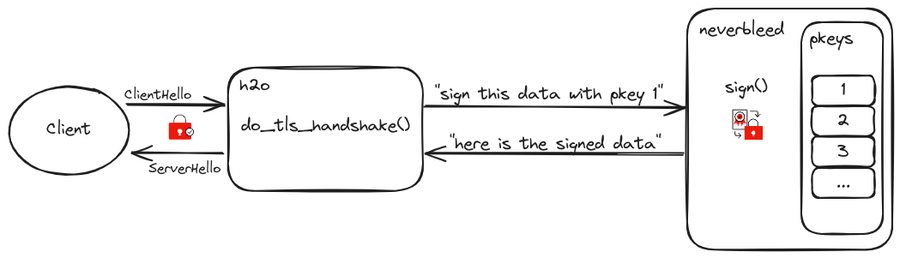
Fastly runs a fork of h2o on every node in the cache fleet, this software is responsible for the TLS termination. Neverbleed is enabled by default in the open-source version of h2o but was not initially enabled on the Fastly fork due to performance issues seen at scale. We decided to revisit this in 2022.
h2o’s threading model is such that there is a static number of worker threads, each handling multiple connections. Each thread has an “event loop” to handle performing work on these connections. This loop is powered by the epoll_wait syscall, when h2o accepts a connection at the edge, it adds the underlying file descriptor to the actively monitored file descriptor set and receives events when data can be read from or written to the file descriptor. All reading/writing of data on connections is executed in a non-blocking manner: asynchronously.
After integrating neverbleed into Fastly’s fork of h2o, we started testing the functionality and analyzing for performance impacts. We quickly noticed there was an impact to the event loop latency (execution time of a single iteration), an increase to the 99.9th percentile (P999). Fun fact, we monitor up to the P999999 for this metric! So an impact in the P999 is significant for us.
An increase of latency in h2o’s event loop may indicate something is preventing it from making progress. Upon investigation, it was determined to be a blocking read(2) syscall on a unix socket file descriptor, yes, the one used to communicate between h2o and neverbleed. h2o write(2)’s a request “sign this piece of data with this private key index” to neverbleed and then immediately calls read(2) to get the response: synchronously. This read call blocks the event loop until neverbleed performs the signing operation (around 1 millisecond) and issues a write to the unix socket with the response. During that time, if the read was non-blocking, h2o could have performed more work on other connections. Let’s address this.
Asynchronous TLS handshakes in h2o
In order to change that synchronous transaction (write/read) with neverbleed to an asynchronous one, we first evaluated if the caller can be made asynchronous. At the time, we used two TLS libraries in h2o for TLS handshaking. h2o uses picotls for TLS 1.3 handshakes and OpenSSL for <1.3 handshakes. We have since migrated to using BoringSSL for <1.3 handshakes.
OpenSSL has an SSL_MODE_ASYNC flag which can be set on the SSL context. This enables the asynchronous processing capabilities of the OpenSSL engine being used. This allows the application to handle the SSL_ERROR_WANT_ASYNC error when the engine starts an asynchronous job (a job is started in SSL_do_handshake). We can resume the operation (handshake) when the job is completed, this is signaled via a ready file descriptor in the case of OpenSSL.
BoringSSL has the ability to set private key methods and they are async capable by returning ssl_private_key_retry. Signaling of job completion is done via a function callback.
Picotls did not have any asynchronous signing capabilities. We added this functionality to picotls in a similar manner to BoringSSL, via application-defined callbacks.
In order to perform asynchronous handshakes at h2o for all TLS handshakes, we modified h2o to handle the new async return types. Moreover, to remove the synchronous read call, we introduced a new API to neverbleed which allows applications to define how data is exchanged between the server process and neverbleed, this allows h2o to re-use internal asynchronous socket APIs to perform the reading/writing of neverbleed transactions in an asynchronous fashion.
The changes we made to support asynchronous handshakes have since been upstreamed to the open-source versions of picotls, neverbleed and h2o for all consumers of these libraries to take advantage of! 🎉
Results
To evaluate the performance of h2o against Fastly’s traffic and workload, we run what we call internally “overload tests''. These tests allow us to target certain hosts in a pop to receive more traffic than others. The goal of these tests is to analyze the performance of our system under heavy load in order to discover bottlenecks and improve the efficiency and performance of the system.
The following graph shows the 99.9th percentile of h2o’s internal event loop latency during an overload test. In yellow is the host running the experiment (asynchronous handshakes) and the others (blue & green) are using the baseline configuration (synchronous handshakes). We observed a decrease in the event loop latency which is what we were seeking.

What came as a bit of a surprise to us, was an impact all the way to the P50. We can also observe that h2o’s internal event loop latency is more stable under load, allowing it to perform more work in the same timeslice. This makes sense, as the expensive TLS signing crypto operations are now removed from the event loop.

This work has allowed Fastly to improve the security of TLS private keys and handshakes, as well as the efficiency of h2o’s event loop. It has also opened the doors to even more efficiency improvements!
Enabling Hardware Acceleration
Finally, an efficiency improvement that can be built on top of asynchronous signature generation is offloading the crypto operations to hardware.
With Intel QAT, we can offload CPU-intensive operations such as RSA to dedicated purpose-built hardware. Given the introduction of asynchronous transactions in neverbleed, we have integrated the Intel QAT Engine at the neverbleed layer. Depending on the TLS workload in a given pop, with QAT hardware acceleration enabled, we can observe up to 5% of h2o CPU savings compared to the baseline. These CPU savings translate to an increase in the traffic capacity of a given host (and pop), making our use of available hardware more efficient.
The graph below is a 24-hour time slice of h2o CPU % showing the difference between h2o with hardware acceleration enabled (orange) and disabled (blue). During this window, around ¼ of the POP had offloading enabled.

Combined, these changes have achieved our goals by making Fastly more secure without reducing performance.