

Fastly detects and reroutes traffic away from broken internet paths to ensure minimal downtime using the standard protocols, but we don’t rest there.
We also develop proprietary mechanisms to supplement the standard ones — like the fast path failover technology we created to mitigate the impact of episodic performance degradation events (sometimes called internet weather) by automatically detecting and re-routing underperforming edge connections. Let’s dig in to how it works.
The challenge: internet weather and the border gateway protocol
Fastly PoPs are multi-homed — connected to the internet using multiple peers and transit providers, each of which uses the Border Gateway Protocol (BGP) to advertise to our PoPs a list of all internet destinations reachable through them. Each PoP receives several million of these BGP destination reachability announcements, allowing us to compute a few distinct paths for each destination.
When a link along the path becomes unavailable, BGP withdraws the routes involving that link and signals alternative paths, if available, triggering ISPs to reroute traffic to bypass the issue. However, the mechanisms available to BGP are quite basic, since it has no real way to detect and react to link degradation (even under severe congestion). This can mean:
If a path is heavily degraded but not entirely failed, a BGP route withdrawal might not be triggered at all, making it sometimes necessary for service providers to detect and manually reroute traffic to mitigate the issue. This process can take from several minutes to a few hours depending on the provider.
Even when BGP detects and responds to a path failure, it’s not instantaneous; it can take anywhere from a few seconds to a few minutes to converge after a failure. While that’s happening, the connections experience a poor performance or even complete stall.
In addition, even after these failures are detected, the actions that BGP can perform are very coarse-grained. In fact:
BGP only provides means for moving entire destination prefixes, which can impact healthy connections. A single route could account for many hundreds of thousands of active connections, of which only a small proportion could be experiencing adverse weather.
The volumes of traffic associated with some routes can be substantial. Moving these larger flows to new paths in an automated fashion could produce undesirable behaviors such as oscillations or downstream congestion.
With these shortcomings, the question becomes: How can we respond to early signs of path degradation, instead of falling back on BGP?
The solution: a failure-detection mechanism using transport-layer metrics
Since the internet is a best-effort network, transport protocols like TCP or QUIC are needed to provide a reliable, connection-oriented abstraction on top of the underlying IP network. These protocols present, at the application layer, a stream-oriented API (a socket) that can be used to communicate without having to worry about issues like congestion control or loss recovery. Senders incorporate mechanisms to retransmit segments that were lost in transit and compute the correct volume of data to send at any point in time to avoid creating congestion along the end-to-end path.
To achieve this, these protocols maintain relatively complex models of the end-to-end path performance (e.g., average round trip time, round trip time variation, loss and whether the connection is making progress sending data and for how long). These metrics could be leveraged to infer the health of the network path used and move their traffic to an alternate path if the current path is experiencing performance degradation.
The key insight is that we do not need to wait for peers or transit providers to tell us that a path is broken. We can determine this for ourselves.
By pairing this capability with our routing architecture, it becomes possible for our edge cloud servers to determine if connections are making forward progress, use this information to infer the health of the internet path used, and select an alternate path if the current one is experiencing issues. Our edge servers can then make routing decisions on a per-connection basis, which enables precise failover decisions and rerouting only degraded connections without impacting healthy ones.
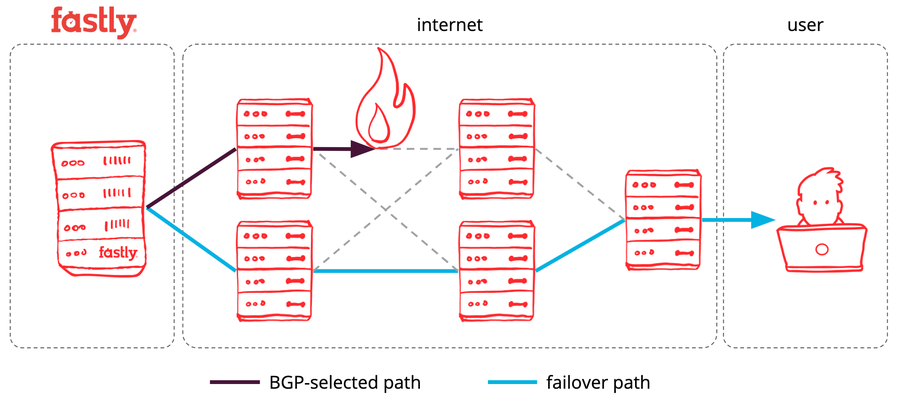
Figure 1: Path failover under a performance degradation scenario
This mechanism is remarkably effective at identifying and mitigating internet weather conditions that are typically too small and too short to be accurately detected and mitigated using standard network monitoring techniques.
Since its release, this technique has allowed us to mitigate an average of around 130 performance degradation events impacting at least one of our PoPs every day, each with a median duration of approximately 9.9 minutes. In these cases, our fast reroute technology provides an improvement of 7% on the probability of connections establishing successfully.
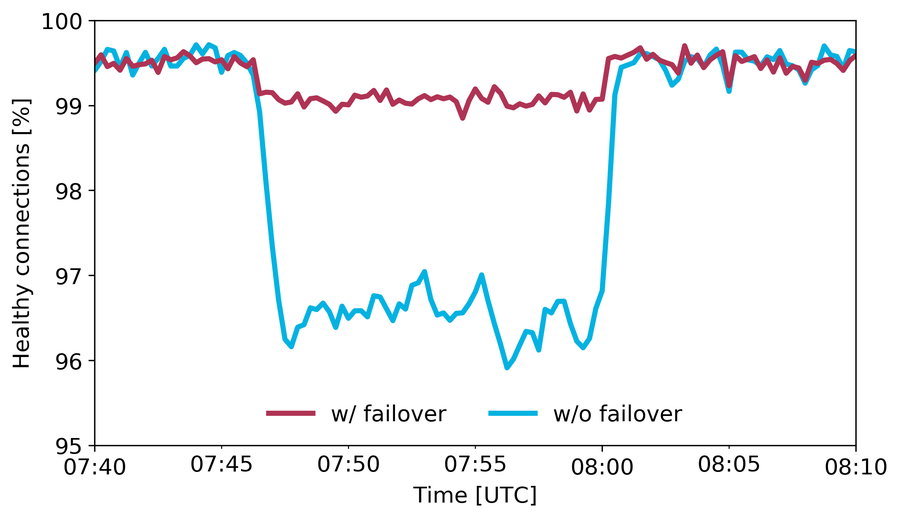
Figure 2: Percentage of healthy connections during a network path performance degradation event with and without our failover mechanisms.
The graph above shows an example of a performance degradation over a path effectively mitigated by our failover mechanism. Both lines represent the percentage of established TCP connections on a specific server that are making forward progress. The red line represents connections with our failover mechanism enabled, while the blue line represents a small control group of connections that rely only on standard BGP mechanisms to select a path.
Up to 7:47 UTC, 99.5% of the connections are making progress. At 7:47 UTC, a path degradation causes connections relying on BGP only to start stalling, and the percentage of healthy connections drops to 96.5%. In contrast, connections using our failover mechanism are quickly re-routed around the failure, resulting in 99% continuing to make forward progress (an improvement of 2.5% over the baseline). The event lasted approximately 13 minutes and terminated at 8:00 UTC, when we observed an increase in BGP route updates received from our peers and transit providers, which is when BGP eventually fixed the issue.
The takeaway: a creative solution leads to high availability and performance
This is only one of the techniques we use under the hood to improve performance and reliability for our customers. By automatically detecting and re-routing underperforming edge connections at the transport layer, in addition to any recovery at the network layer, we can mitigate the impact of issues beyond our own PoPs (i.e., internet weather) and continuously improve the connection quality for traffic between end users and Fastly.
Since this failure resilience capability is included for our entire production cache fleet, it’s available to all customers (at no additional cost). This failover mechanism provides a powerful new way for us to provide our customers with high availability and performance, even where we have no control over the network. As always, you can find the latest updates on Fastly's availability at status.fastly.com.