


Summary: In part 1, we discussed how Fastly started down the slippery slope of network software. Our previous experience with routing suggested that avoiding traditional network devices would not only dramatically cut capital expenditure, but also quickly outpace existing solutions. Having already eschewed routers, we turned our attention towards obsoleting load balancers entirely. In this post, we’ll detail our in-house load balancing system which performs seamless failover with minimal processing overhead.
Our previous post detailed how Fastly started down the slippery slope of network software. By implementing a distributed routing system on commodity switches, we were able to maintain complete control over how we forward packets at a fraction of the cost imposed by conventional networking wisdom.
The return on investment of our small collection of hacks was tremendous, and came as we closed our series B round over the summer of 2013. Our focus was shifting towards aggressively expanding our infrastructure whilst maximizing the number of requests we could serve. Our previous experience with routing suggested that avoiding traditional network devices would not only dramatically cut capital expenditure, but also quickly outpace existing solutions. Having already eschewed routers, we turned our attention towards obsoleting load balancers entirely.
In this post, we’ll discuss what we came up with: Faild is our in-house load balancing system that performs seamless failover with minimal processing overhead. Prevailing best practices typically reduce load balancing to being performed single-handedly by the network through hardware load balancers or ECMP routers. More recently, the antithetical approach has gained traction, with services such as MagLev and GLB implementing load balancing in software running on hosts. Faild is a synthesis of both approaches: leveraging hardware processing on commodity switches where possible, and pushing out flow handling towards hosts when necessary.
The result of this division of labor is a virtually stateless, distributed load balancer. Faild is highly efficient and inherently reliable, ensuring that established flows are never spuriously reset. It achieves this by lying compulsively to the hardware it talks to while incurring no additional state than would otherwise be required by TCP. In devising a solution which would cost us less, we ended up with a system that costs us nothing.
Load balancing client requests: walking the tightrope
Consider a set of servers which serve a collection of clients, as shown in figure 1. From a client’s perspective, what server a request is forwarded to is unimportant so long as a response is received in a timely manner. This allows for some degree of freedom in how an operator goes about mapping current demand to available capacity, in what is commonly referred to as load balancing. Load balancing is performed at almost every layer of the network stack. For the purpose of this post, we’ll focus on load balancing inbound client requests in the context of a CDN.
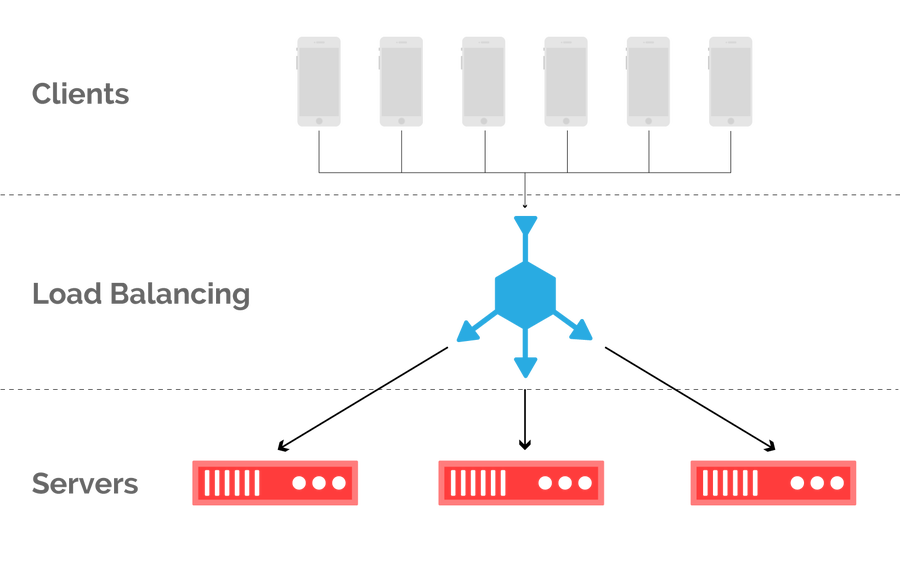
Figure 1: inbound load balancing maps client requests to cache servers within a POP.
The primary challenge of load balancing HTTP requests is derived from an unassailable constraint: if a packet belonging to an established TCP connection is forwarded to an incorrect server, the associated TCP flow will be reset. Unfortunately, the network layer does not understand the concept of a flow any more than applications understand the notion of packets. In the following paragraphs, we’ll outline the three traditional approaches to load balancing requests, all of which are ill-suited for a general-purpose CDN.
Load balancers: application-aware networking
For every problem in computer networking there is a closed-box solution that offers the correct abstraction at the wrong cost. Our previous post highlighted that routers are just appliances that happen to perform routing. Similarly, load balancers are appliances — unnecessary, expensive, and ultimately ineffective solutions for load balancing.
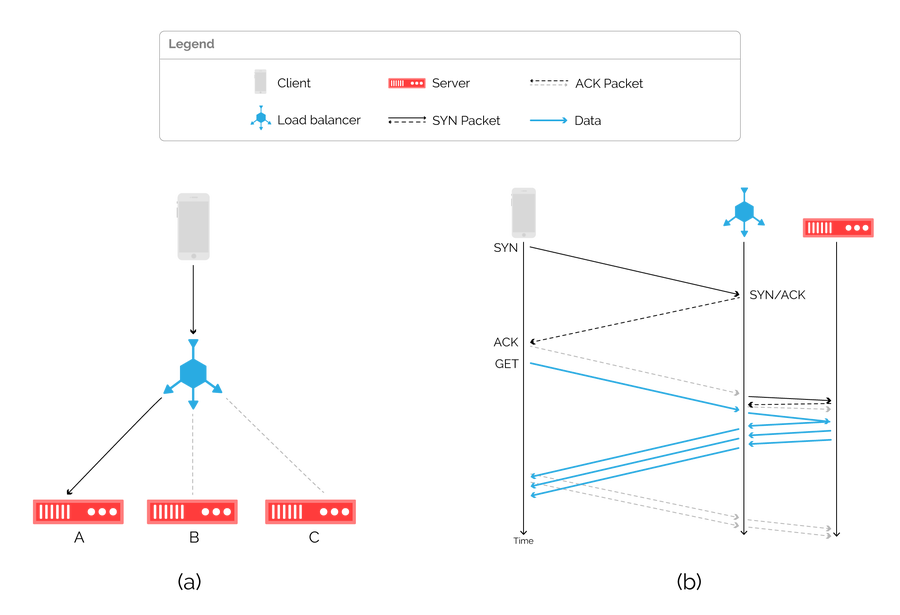
Figure 2: a network topology using a load balancer (a) and associated packet flow diagram (b).
Load balancers typically act as proxies, terminating connections from clients and demultiplexing traffic across backend servers, as shown in figure 2a). They are typically either aware of the transport layer (TCP), or the application layer (HTTP). In either case, load balancers terminate inbound connections, and then relay the data to an available server over a separate connection, as illustrated in figure 2b).
A load balancer can monitor the health of backend servers, and therefore make an informed decision on where to route incoming flows. When implemented correctly, request distribution across backend servers is close to optimal, but at tremendous cost. A load balancer has a perfect view of the network by tracking state for every network connection, which is expensive to maintain and is often offloaded to specialized hardware.
More worryingly, maintaining state is a liability. It’s much cheaper for the sender to create connections than for a receiver to keep track of them, and this asymmetry in TCP is regularly exploited in denial-of-service (DoS) attacks. Most load balancers implement additional measures against SYN floods in particular, but fundamentally become choke points in the network. Even load balancers that are virtualized and run on commodity hardware, such as Google’s MagLev, require maintaining per-flow state and are therefore inherently more vulnerable to DoS attacks.
DNS: a layer of indirection
All problems in computer science can be solved by another level of indirection1. The Domain Name System (DNS) resolves domain names to addresses, and this mapping can be used to balance load across servers by only returning the IP addresses of healthy servers.
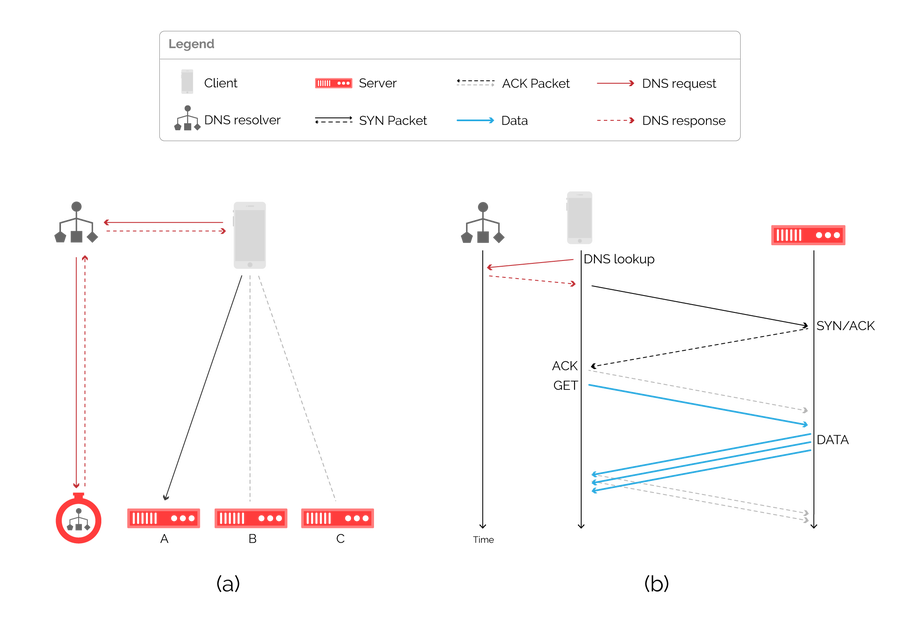
Figure 3: an architecture for server selection using DNS (a) and associated packet flow diagram (b).
This approach does not require per-flow state and therefore scales well, but has a fundamental limitation in how quickly it can perform failover. A DNS response can be cached by downstream resolvers for minutes or even hours. The time a response can be cached is signaled through the time-to-live (TTL) field contained in the response, but this is not always respected by resolvers. As a result, a change can take considerable time to propagate globally, and a client may be resolving to an unavailable server in the interim.
Companies such as Spotify and Netflix control both the end-user application and the edge delivery servers, and can therefore move beyond DNS and embed server selection directly into their applications. CDNs like Fastly don’t have this luxury, since they must encompass a wide range of use cases — from video streaming to API calls. The only assumption we’re afforded is that requests will be made over HTTP.
ECMP: better the devil you know
Our starting observation was that forwarding a packet to the wrong server would cause a connection reset. Load balancers avoid this pitfall at the expense of scalability. DNS load balancing provides a scalable alternative to hardware load balancers, but is less responsive to unexpected changes. In both cases, the remedy is worse than the disease.
A commonly adopted alternative to balance flows in a stateless manner is Equal Cost Multipath (ECMP). ECMP is available on most network devices by which a same destination prefix can have multiple next hops, and next hop selection is based on the result of applying a hash function to fields in the header of the forwarded packet. By computing the hash function over inputs which are immutable over the lifetime of a flow (i.e., source and destination addresses and ports) we can ensure that all packets in a flow are forwarded towards the same next hop.
Servers can announce their availability over BGP to the connected switch, which is in turn responsible for hashing packets accordingly. An excellent article on how to configure such a system using open source software is available here.
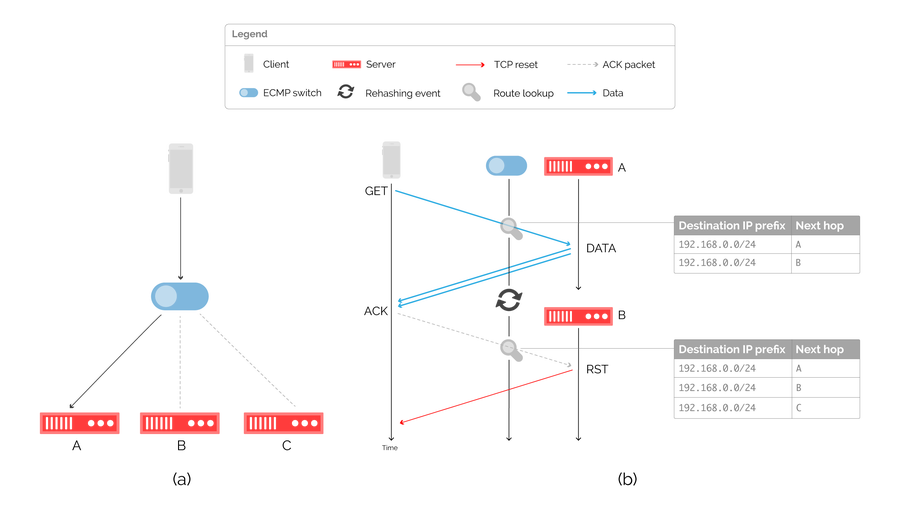
Figure 4: load balancing with (a) an ECMP capable switch and (b) the packet flow diagram and associated routing table during a rehashing event.
The drawback of this approach is that until very recently, device manufacturers did not implement consistent hashing for ECMP. On route changes, triggered by the addition or removal of a server from the available pool, the result computed by the hashing function may change, which can cause packets to be forwarded to the wrong server. This rehashing event is illustrated in figure 4(b), where an ongoing flow towards server A is disrupted by a routing change. By adding a new route towards next hop C, the next hop computed by the hashing function changes, resulting in a connection reset.
Despite this, ECMP remains popular particularly within the CDN industry. By eschewing maintaining per-flow state, it performs well during steady state operation, at the cost of connection failures during transient events. In pursuing scalability, ECMP forsakes correctness. We wanted both.
Resilient ECMP: a first approximation
The lifecycle for supporting features such as consistent hashing in hardware is painfully protracted, so we decided we were better off writing software to do it ourselves. In our previous post, we detailed how to build a distributed routing framework by manipulating standard networking components such as routing tables or ARP entries. Conveniently, we can use many of the same building blocks to approximate the behaviour of consistent hashing.
Rehashing occurs when next hop entries change. In order to avoid rehashing, we need to maintain a fixed set of next hops. Since our primary objective is to dynamically readjust the pool of available servers, we need some other method for steering traffic. A viable alternative is to use the ARP table as a layer of indirection. By pointing the routing table at static, virtual next hops, we can force the switch to perform a lookup in the ARP table. We can then adjust the ARP table rather than the routing table to influence packet forwarding.
Two issues arise in this model, both of which are readily solved:
We can no longer rely on routing protocols such as BGP and OSPF to steer inbound traffic towards servers. Conventional routing protocols ensure reachability by modifying the routing table, but we have pushed the responsibility for steering traffic down to the link layer. Instead, we must write a controller which directly manipulates the ARP table on the switch, as shown in figure 5. The controller exchanges information with agents running on connected caches. Each agent is responsible for health checking the local instance of Varnish, which handles HTTP requests from end clients.
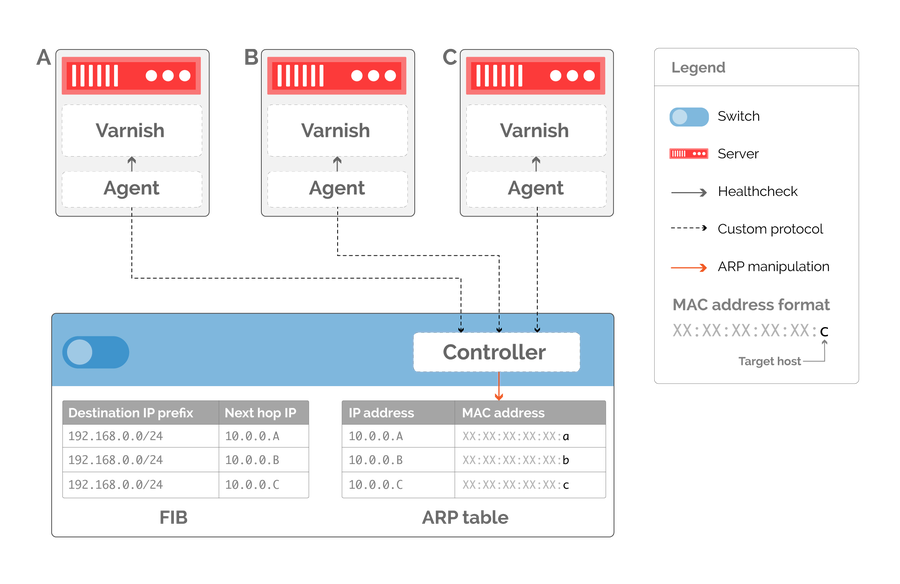
Figure 5: a custom routing protocol based on ARP table manipulation. The routing table remains static while the ARP table is adjusted to point at healthy servers.
The granularity with which we can rebalance traffic is now directly tied to the number of next hops in our routing table. As shown in figure 5, if we removed a server from serving traffic we’d have to rewrite an ARP entry to point at a healthy server, potentially doubling the amount of traffic on the selected target. To avoid this, we can generate more next hops to provide finer-grained control, as illustrated in figure 6. By having two virtual next hops per server, we can ensure that healthy servers in the POP have an equal number of ARP entries directed at them when withdrawing server B from production.
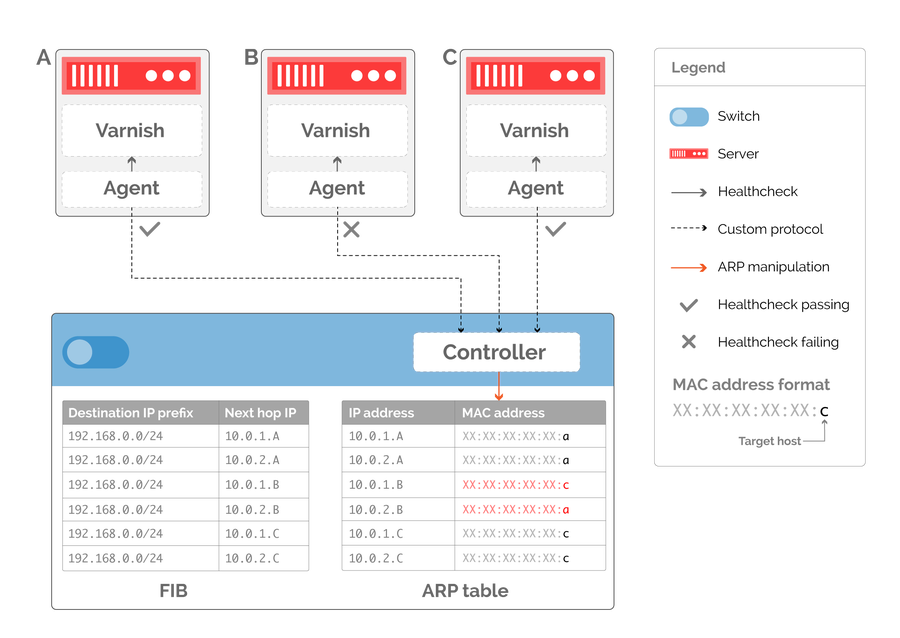
Figure 6: additional next hops ensure even distribution of traffic when server B is removed from service.
In 2013, these hacks alone would have provided us with a software-only implementation of ECMP with consistent hashing, two years before such a feature would become widely supported in hardware by network vendors. But we had no idea where the boundaries were, and so we ended up somewhere else entirely.
Faild: a layer of misdirection
When changing next hops without consistent hashing, TCP connections will be reset in every server. While Resilient ECMP avoids this, it’s still unable to gracefully withdraw a server from production. Revisiting the example in figure 6, removing host B causes the MAC addresses to abruptly transition towards either of the remaining servers in the pool. All ongoing connections towards host B will be terminated.
The commonly held assumption is that such behavior is unavoidable and only triggered on rare events like hardware failures or software crashes. In practice however the primary reason for withdrawing a server from production is for software upgrades. Incurring connection resets on upgrades has ramifications far beyond disrupting production traffic: it provides a disincentive for continuous software deployment.
Graceful failover, or host draining, cannot be implemented on the switch alone, since the switch has no visibility into what flows are in progress at any given time. If a switch were capable of tracking flow state, it would be a hardware load balancer. Our alternate solution was to distribute the responsibility of load balancing across both the controller and hosts. We named the resulting software Faild after the keepalived system it was intended to replace. Had we known it would work, we would have chosen a more impressive name.
The first step towards implementing draining is to be able to signal what host is being drained, which we can encode into the destination MAC address. While our previous examples assumed that the connected host interface has a single MAC address, there is no such limitation in practice. Using this signaling mechanism, we can now program the switch ARP table to embed the identity of a previous target host as well as the current one (figure 7).
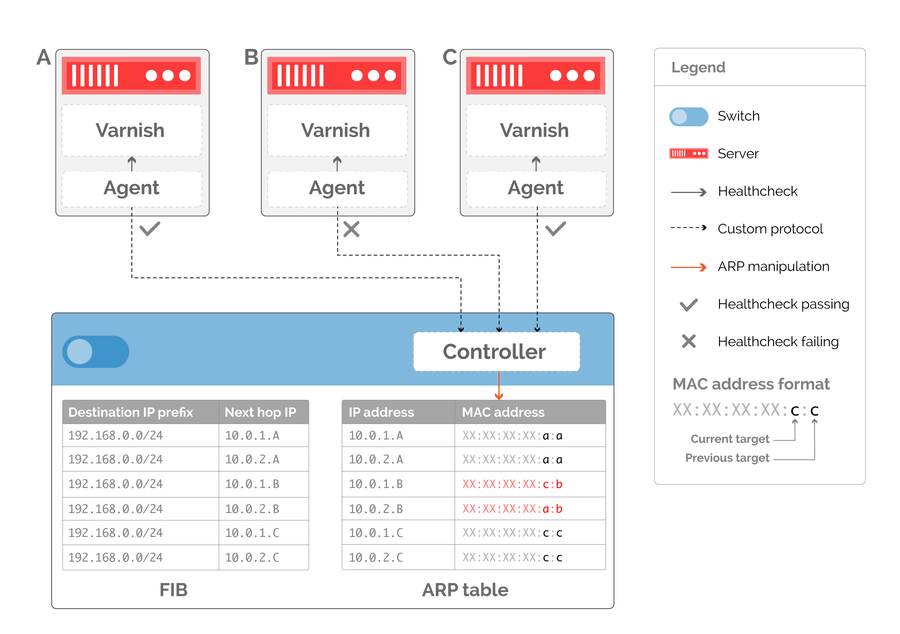
Figure 7: MAC encoding of proxied host alongside target host.
Now that we’ve conveyed availability information down from the switch, we can delegate the load balancing decision towards the servers. This not only removes the need for maintaining flow state within the network, but also distributes the computational cost of load balancing across a larger set of nodes, since there are far more servers than switches in a POP. This computational cost is further reduced by implementing all of the receive-side processing as a single purpose kernel module, which efficiently processes inbound packets according to the destination MAC address, as shown in figure 8:
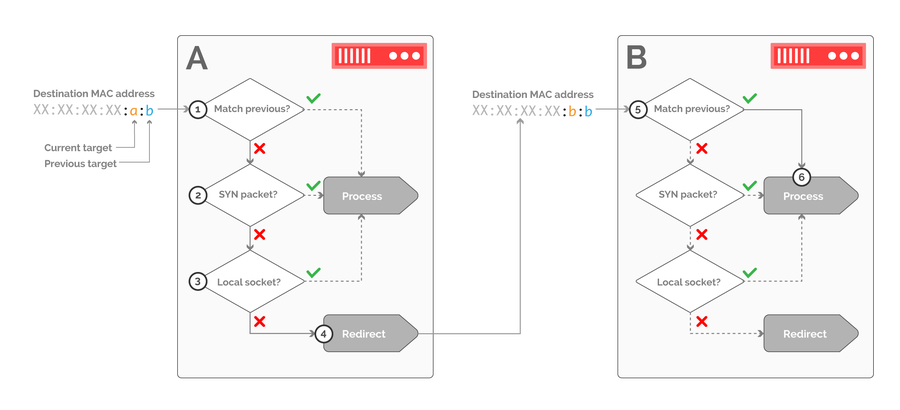
Figure 8: an example of receive-side packet processing for traffic draining from host B towards host A. Packets filtered through host A are only accepted if they belong to a new connection, or if they match a local TCP socket.
The kernel module receive handler must first determine whether the previous target encoded in the ingress packet matches the local host. If so, we hand over processing to the local network stack. Otherwise, we must verify whether the packet belongs to a new connection, as signaled by the SYN flag in the TCP header (step 2), or to an existing connection, which can be verified by doing a lookup against the local socket table (step 3). If neither of these conditions are met, the packet is redirected to the previous target by rewriting the MAC header. The same processing logic is applied at host B (step 5). In this case, the host identified as the previous target matches the local host identifier, so the packet is immediately accepted.
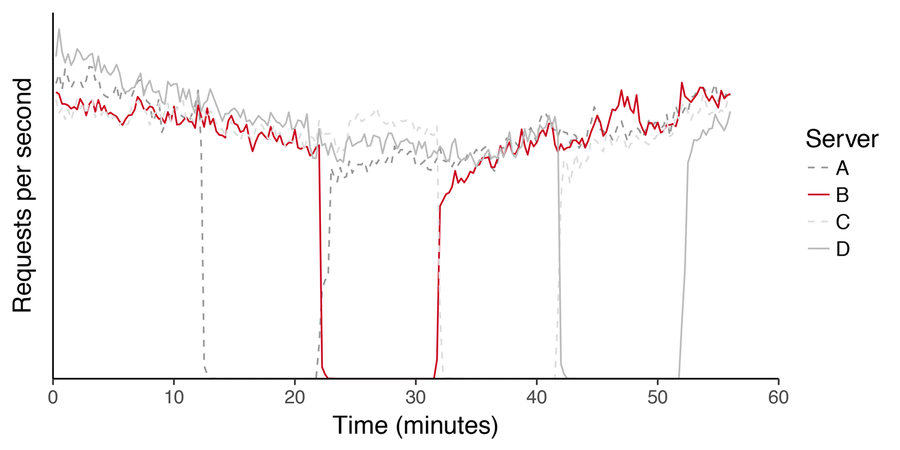
Figure 9: RPS across a cluster of servers during a rolling kernel upgrade. Hosts drop in and out of production without affecting overall service.
An operational perspective on draining (figure 9) plots the request rate across a subset of hosts within a POP during a maintenance event. In this particular case, hosts are sequentially withdrawing themselves from service in order to perform a kernel upgrade. Given all servers behave similarly, we highlighted the behavior of a single host for clarity. Neither the descent during withdrawal or ascent during reintroduction are immediate: the slope in either case indicates that flows are completing gracefully on the server they were originally established on.
The impact of Faild over the past three years in production extends far beyond traffic metrics alone. Reducing the impact of maintenance events has allowed us to deploy software more quickly with no customer impact, subsequently helping us address security vulnerabilities. It also further legitimized a network architecture where networking devices merely play a supporting role for the application they support.
No packet left behind
Fastly has scaled to handling millions of requests per second since Faild was first deployed in 2013. Through a combination of ECMP, ARP rewriting, and kernel hackery, we were able to do so without ever needing to buy anything more complex than a switch. None of the individual components of Faild are particularly challenging, but together they form a distributed load balancer which can perform reliably and efficiently on commodity hardware. While the devil is in the details, the implications are devastating for traditional network vendors.
As with Silverton before it, Faild had no grand design, no singular moment of brilliance, no frenzied sense of urgency. The only guiding principle was a shared belief that scaling should not be about buying a bigger box, or even buying more boxes. Faild is instead the outcome of successive iterations in articulating a problem and paring down the solution until there was nothing left to take. To fit our use case, we kept hacking away at the fringes of networking — the corners we cut were the ones that time would have inevitably eroded anyway.
Our next post will detail the fickle art of optimizing how packets reach our POPs by influencing interdomain routing, and how we went about building our global anycast network. If you prefer building systems rather than waiting years to read about them in someone else's blog post, we're hiring.
1 https://en.wikipedia.org/wiki/Fundamental_theorem_of_software_engineering