
Network Error Logging (NEL) can provide valuable insights into network issues your users may have while connecting to your website, and since it’s a W3C spec supported by some browsers, it also has a lot of potential to help with error detection and reporting. In fact, we’ve been experimenting with NEL with Fastly Insights and discovered that processing NEL reports is a great use case for Compute, Fastly’s new serverless compute environment. With Compute, we can efficiently parse and enrich the data, then re-serialize the JSON before shipping the resulting report to a third-party logging endpoint, such as BigQuery, all without the need for the more complex and error-prone processing pipelines we traditionally used to solve this problem.
We’ve been talking about Compute — how it allows you to upload and deploy complex logic at the edge with the most secure, performant, and scalable approach to serverless computing — for a while now, but this is the first time we’ve shared how we used C@E to solve a problem internally. In this post, we'll walk through how we built a NEL reporting pipeline, discuss where there was potential for optimization, and, ultimately, how Compute helped solve these problems while introducing performance and security improvements along the way.
A typical reporting pipeline
Conceptually, there are only a few requirements to build a NEL reporting endpoint:
Respond to OPTIONS requests with a 204 (No Content) and the appropriate CORS headers to satisfy the pre-flight security requirements.
Respond to the report-carrying POST requests with a "204 No Content" HTTP response.
Collect reports, decorate them with metadata if necessary, and log them to an analysis pipeline.
Convert logged data to a consumable format for analysis as needed, and persist to a database.
NEL reports arrive from a browser as POST body payloads in JSON format. Even though they can be analyzed as-is, Fastly also knows a lot more about the request, and it's useful for us to capture that metadata available at the edge to add some context to each of the reports. For our purposes, we want to add geo IP information and a timestamp to each report before logging it using Fastly’s real-time logging capabilities.
To make things more exciting, browsers can — and in our observations will — batch multiple NEL error reports and send them all at once in a single POST request, most likely to use their resources more efficiently. That means the POST body we see for each request can have one or more reports, sent in as an array of JSON report objects.
Since parsing and construction of complex JSON objects at the edge isn’t trivial, the approach we took was to construct a new JSON object to act as an envelope, specify the metadata as individual properties of the object, add the reports array as another property of the object, then log the envelope object in newline-delimited JSON format to a storage endpoint (in this case, Google Cloud Storage).
At this point, the raw logs are not necessarily consumable for analysis, as each row could still contain many reports; we’d prefer each report to be a single row in a database. To address this, we deployed a common extract, transform, load (ETL) pipeline pattern using Google’s Cloud Functions to process the logs, parse out the individual reports, merge them with the metadata and then insert each as a separate row into BigQuery. This diagram shows the general flow from start to finish:

What we built was functional and served us in production well. But it was easy to see room for improvement: if we could parse the reports at the edge, construct individual JSON objects per report (and add the extra Fastly-supplied metadata to each one), then log the result directly to BigQuery from the edge, we’d reduce the number of moving parts in the process and create a more efficient collection/logging/analysis pipeline that’s also easy to extend in the future.
This is exactly the sort of toolset Compute empowers us with, so this became the main motivation for migrating the current pipeline to the new platform.
NEL report collection with Compute
Compute is language agnostic and allows us to program in familiar programming languages — like Rust — at the edge. Rust has native support for things like parsing JSON into strongly typed data structures, as well as a powerful pattern-matching capability. These capabilities enable us to build and deploy a purpose-built collection endpoint that extracts, transforms, and logs the reports to BigQuery, thus eliminating the need for many of the components in our previous iteration. Let’s have a look at some of the core logic to see how we achieved this (you can also view the entire application on GitHub):
Routing
Like most serverless platforms, Compute programs have an entry point that is a single function that accepts a request and returns a response. So first, we need to define our program’s entry point function, which will contain our HTTP routing logic. Fortunately, Rust’s pattern-matching syntax allows us to easily match against the structure and values of types such as the inbound request, allowing us to say do this if the request is a POST, or that if it isn’t.
#[fastly::main]
fn main(req: Request<Body>) -> Result<Response<Body>, Error> {
// Pattern match on the request method and path.
match (req.method(), req.uri().path()) {
// If a CORS preflight OPTIONS request, return a 204 no content.
(&Method::OPTIONS, "/report") => generate_no_content_response(),
// If a POST request pass to the `handler_reports` request handler.
(&Method::POST, "/report") => handle_reports(req),
// For all other requests return a 404 not found.
_ => Ok(Response::builder()
.status(StatusCode::NOT_FOUND)
.body(Body::from("Not found"))?),
}
}Here we match against the request's method and URL path. If it's an OPTIONS request to the reports path, we instantly return a 204 response; if it's a POST request to the same path, we pass it to a handle_reports function; and otherwise, we return a 404 Not Found response.
JSON parsing
The main purpose of the CloudFunction in our previous pipeline was to parse the JSON, extract each report, transclude the global metadata, and then emit as individual rows to the database. One of the instrumental features of Compute is that we can take advantage of the rich and mature ecosystem of modules designed to solve these problems in safe and efficient ways, such as the amazing serde_json Rust crate.
Serde allows us to read the request body data stream and parse it as JSON to a strongly typed Rust data structure that we’ve predefined. As NEL is a W3C specification, it means the POST payload is also a predefined structure that all user agents must conform to. This gives us a nice side effect that any malformed or malicious reports sent to our endpoint will be dropped by Serde, as they won’t conform to the specification. It also means we don’t need to do any post-processing to clean the data in BigQuery before consuming. Type safety FTW!
/// `Report` models a Network Error Log report.
#[derive(Serialize, Deserialize, Clone)]
pub struct Report {
pub user_agent: String,
pub url: String,
#[serde(rename = "type")]
pub report_type: String,
pub body: ReportBody,
pub age: i64,
}
// Parse the NEL reports from the request JSON body using serde_json.
// If successful, bind the reports to the `reports` variable, transform and log.
if let Ok(reports) = serde_json::from_reader::<Body, Vec<Report>>(body) {
// Processing logic...
}Transform and log
Now we have access to a list of structured NEL reports sent from the client, we can enrich each with our geo IP metadata before finally logging each to our BigQuery endpoint. This is where the true power of having a flexible programming environment at the edge shines.
First, we model the metadata in the form of a ClientData struct and implement its constructor method, which accepts an IP and user agent string. The constructor does a couple of things worth mentioning:
It first truncates the client IP address to a privacy safe prefix, as we don’t need to store the full IP in our database.
Then it calls the geo_lookup function from the imported fastly::geo module, which returns the geographic data associated with a particular IP address, such country code and autonomous system name.
Lastly, it parses the user agent string and normalises it to a family, major, minor, patch version string — as, like the IP, we don’t need all of the information.
use fastly::geo::{geo_lookup, Continent};
/// `ClientData` models information about a client.
///
/// Models information about a client which sent the NEL report request, such as
/// geo IP data and User Agent.
#[derive(Serialize, Deserialize, Clone)]
pub struct ClientData {
client_ip: String,
client_user_agent: String,
client_asn: u32,
client_asname: String,
client_city: String,
client_country_code: String,
client_continent_code: Continent,
client_latitude: f64,
client_longitude: f64,
}
impl ClientData {
/// Returns a `ClientData` using information from the downstream request.
pub fn new(client_ip: IpAddr, client_user_agent: &str) -> Result<ClientData, Error> {
// First, truncate the IP to a privacy safe prefix.
let truncated_ip = truncate_ip_to_prefix(client_ip)?;
// Lookup the geo IP data from the client IP. If no match return an
// error.
match geo_lookup(client_ip) {
Some(geo) => Ok(ClientData {
client_ip: truncated_ip,
client_user_agent: UserAgent::from_str(client_user_agent)?.to_string(), // Parse the User-Agent string to family, major, minor, patch.
client_asn: geo.as_number(),
client_asname: geo.as_name().to_string(),
client_city: geo.city().to_string(),
client_country_code: geo.country_code().to_string(),
client_latitude: geo.latitude(),
client_longitude: geo.longitude(),
client_continent_code: geo.continent(),
}),
None => Err(anyhow!("Unable to lookup geo IP data")),
}
}
}Now that we have our metadata implementation, we can construct a new instance of it and generate our list of reports to be logged. To do this, we map over each of the parsed reports, constructing our LogLine envelope, which merges the report body and client metadata into a single object along with a receive timestamp. With NEL, all we want is to decorate with metadata already present at the edge, but if we wanted to do more fancy stuff like fetch additional data from an origin service, this is where we'd do it.
// Construct a new `ClientData` structure from the IP and User Agent.
let client_data = ClientData::new(client_ip, client_user_agent)?;
// Generate a list of reports to be logged by mapping over each raw NEL
// report, merging it with the `ClientData` from above and transform it
// to a `LogLine`.
let logs: Vec<LogLine> = reports
.into_iter()
.map(|report| LogLine::new(report, client_data.clone()))
.filter_map(Result::ok)
.collect();Finally, we iterate through the list of logs, serialize each back to a JSON string via Serde and emit the line to our BigQuery logging endpoint, thus eliminating the need for our ETL pipeline in a couple of lines of Rust 🎉.
// Create a handle to the upstream logging endpoint that we want to emit
// the reports too.
let mut endpoint = Endpoint::from_name("reports");
// Loop over each log line serializing it back to JSON and write it to
// the logging endpoint.
for log in logs.iter() {
if let Ok(json) = serde_json::to_string(&log) {
// Log to BigQuery by writing the JSON string to our endpoint.
writeln!(endpoint, "{}", json)?;
}
}Here is a sample of the result of the program’s processing, a nicely structured JSON object to match our BigQuery schema:
{
"timestamp": 1597148043,
"client": {
"client_ip": "",
"client_user_agent": "Chrome 84.0.4147",
"client_asn": 5089,
"client_asname": "virgin media limited",
"client_city": "haringey",
"client_country_code": "GB",
"client_continent_code": "EU",
"client_latitude": 51.570,
"client_longitude": -0.120
},
"report": {
"url": "https://www.fastly-insights.com/",
"type": "network-error",
"body": {
"type": "abandoned",
"status_code": "0",
"server_ip": "",
"method": "GET",
"protocol": "http/1.1",
"sampling_fraction": "1",
"phase": "application",
"elapsed_time": "27"
},
"age": "34879"
}
}We now have all the information we need: what type of network error occurred and the network it occurred on, the type of user-agent that produced the report, and a rough indication of where in the world it happened. The data is rich enough that we can now build real-time dashboards and alerting systems to help us understand where and how clients have trouble reaching our network.
Reduce complexity and increase speed and safety
By migrating our NEL reporting pipeline to Compute, we were able to eliminate two moving parts of the system (the temporary storage bucket and the CloudFunction), which, in turn, reduced the operational overhead and overall cost of the system — a big win.
However, I find it's the performance, security, and data integrity benefits that have been the biggest wins:
Reports now appear in BigQuery within seconds of receiving them instead of multiple minutes previously, going back to the real-time logging which we’ve come to expect with Fastly.
By using a strong type system in Rust for JSON parsing, we now only log valid reports. This eliminates the need for post-processing since a single codebase allows us to roll out schema changes with ease instead of lockstep.
And the resulting architecture diagram of our new pipeline now looks much more simple in comparison:
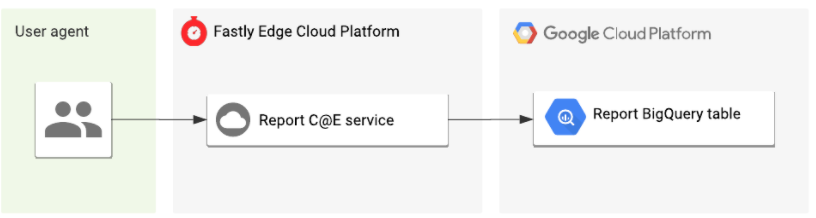
This is just one small example of how we are beginning to take advantage of the platform internally at Fastly, and I can’t wait to share more examples with you in the future.
Try it out yourself
If you’re still not convinced, or you want to see the code for the full application in all its glory, you can view it on GitHub. Even easier, if you’re a Compute beta customer, you can initialise a new project using our NEL starter kit with a single CLI command:
$ fastly compute init --from https://github.com/fastly/fastly-template-rust-nel.gitIf you’re not yet a beta customer, sign up today. We’re excited to see other use cases like this as our customers start to unlock the true potential of the platform, so please share your experiences with us. Go forth, use the platform, and build cool things!