
In December we blogged about why speed matters and Fastly’s milestone of serving 1 terabit per second of content to the internet. As we continue to scale our network, we regularly evaluate technology advancements that keep us on the leading edge. One of these advancements is 100 Gigabit Ethernet (GbE) switches in single rack-unit formats, and we’ve recently lit our first 100GbE ports at the Amsterdam Internet Exchange (AMS-IX) using them. There were many questions that had to be answered before we knew that 100GbE was a good fit for our wider environment, and we want to share our experience with the decision-making process.
When weighing the cost of 100GbE hardware against the complete data center connectivity picture, along with our current growth rate, the economies of scale kicked in to make 100GbE an effective addition to our deployment model. We’re getting really good at maximizing our network capacity, as well as taking full advantage of our hardware resources, so the need for 100GbE had to be more of an economical choice as opposed to being the cool kid on the block.
But let’s not fool ourselves — speaking as a network engineer who gets a kick out of big pipes and big bandwidth, 100GbE is still pretty cool.
Let’s have a look at three major design considerations we took into account for our 100GbE decision.
Cross connects
While the cost of a 100GbE switch and associated optics is still higher than the common 10GbE switch you’d see in many data centers, there’s a hidden cost that sometimes gets overlooked — cross connects. At Fastly, we burn up a lot of data center cross connects.
In any typical data center, you somehow need to attach your networking equipment to another entity’s networking equipment. Whether it’s an on-premise or off-premise connection, a cross connect is a leased fiber connection between two points, such as Fastly’s equipment and another network’s equipment. When you start counting all the cross connects needed for something like a Fastly POP, these fees really start adding up. Cross connect prices are often treated like real estate in the data center, and therefore don’t reduce year over year the same way other parts of the industry do (like network hardware or IP transit rates).
In the figure below, you’ll see just one of many switches in a single Fastly POP, with multiple 10GbE connections to each transit provider. Each one of these end-to-end connections constitutes a single monthly recurring cross connect fee paid to the data center, not to mention the fixed cost of fiber and optical transceivers required to make the physical connection.
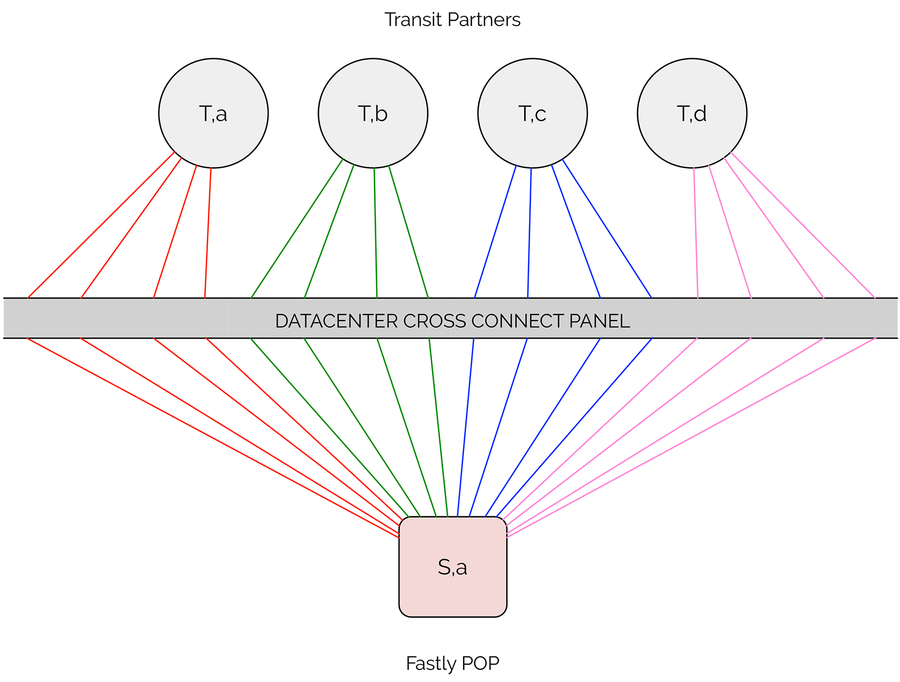
One switch with 16 cross connects to various transit partners
With the advent of 100GbE-capable switches, we can compress our northbound connectivity needs into a handful of 100GbE rather than dozens of 10GbE. This means significantly less cross connects, less fiber, and less optics. In fact, for us it’s about a 6x savings in some of our busier POPs.
It also makes our Data Center Infrastructure team very happy, as you can imagine from the pictures below.

Collapsing multi-10GbE into 2x100GbE

One of two cross connect panels at a Fastly POP
Buffering
Not all 100GbE switches are equal, and we needed to understand buffer capacities and the effect of rate conversion. If you consider the serialization of an Ethernet frame moving from one 10GbE interface of a switch to another 10GbE interface on the same switch, there’s typically no buffering required. In this case the frame is forwarded as soon as the destination MAC address is known, usually within the first six bytes. This is typically referred to as cut-through switching and doesn’t require buffering. Similarly, if you are moving from a 100GbE interface of a switch to another 100GbE interface on the same switch, this packet is not only cut-through, but an order of magnitude faster in terms of serialization delay when compared to 10GbE.
A potential problem is when a packet is entering the switch from one 10GbE interface and destined to a 100GbE interface on the same switch. In this case, a rate conversion function needs to happen. This causes the switch to store the whole frame in buffer before forwarding it, and could potentially cause added latency. More concerning, perhaps, is a large traffic surge event which can exhaust small buffers, in turn triggering frames to be dropped during the rate conversion. It’s therefore important to consider buffering capabilities based on the network design and expected traffic profile. For Fastly’s relatively flat topology and diverse traffic patterns, we leaned towards the larger buffer options made available by Arista’s 7280E and 7280R 100GbE switches.
Cost of bandwidth
There’s also the cost of bandwidth to consider. Typically when you buy wholesale bandwidth from a Tier 1 transit provider, you are committed to paying a minimum dollar amount based on a minimum port usage percentage, regardless if you actually fill that quota. For the sake of argument, let’s say your contracted minimum commitment is 10% usage. That’s a lot easier to fill on a 10GbE port than it is on a 100GbE port. If you can’t fill the quota, you’re burning money. It’s like paying for your monthly gym pass and only using it once.
Other design considerations
With our current large POP design, we land every transit partner on four switches, and then scale up the capacity with multiple 10GbE link-aggregation (LAG) bundles as necessary. If you are swapping out 200 Gbps of transit bandwidth provided by 4x 50 Gbps bundles with 2x 100 GbE ports, you have cut your switch fault tolerance in half. We had to carefully consider what this looks like in a failure or maintenance scenario, where effective capacity of any given transit provider can be reduced by 50% with just one link being lost. In previous multi-10GbE designs, the effective capacity loss could range anywhere from 6-12% on link failure depending on LAG bundle counts. That’s a big difference.
Here’s a visualization of a link failure in a pure 100GbE deployment. Assume 120 Gbps is being sent to Transit A in an equal distribution from Switch A and B. Failure of an upstream link somewhere between Switch A towards Transit A would cause congestion between Switch B and Transit A.
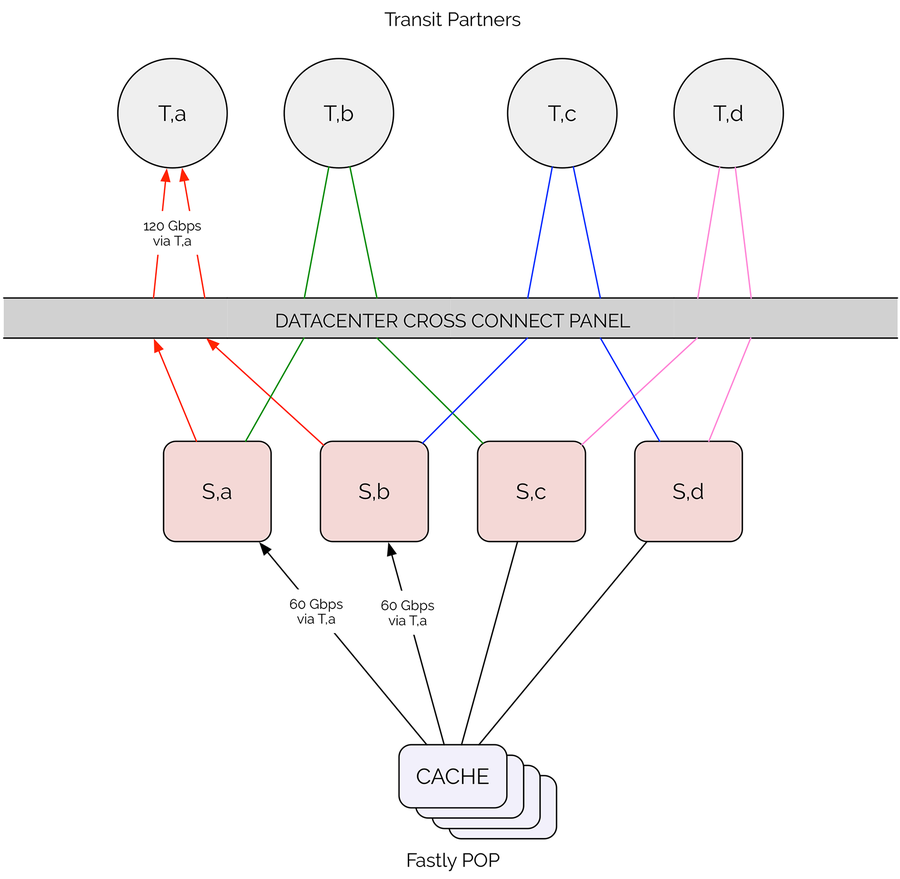
100GbE oversubscription risk to Transit A
An obvious solution would be to consider striping each transit provider across all switches for complete fault tolerance, much like the 10GbE model I described previously. Super easy, problem solved, but the potential for wasted capacity in a pure 100GbE design is far too great. Further, some 100GbE switches like the 7280E only have two 100GbE ports available. We definitely don’t like throwing money at problems, and we have a smart team that saw a better solution. Soon we’ll be able to extend some of our existing systems to detect upstream congestion and failures, triggering the POP to automatically reroute traffic onto underutilized links and eliminating this particular design constraint.
What’s next?
The need for POPs that can support many terabits of egress capacity is a very real thing. Someday we’ll see the next generation of interfaces such as 400GbE, and we’ll hit another inflection point where we go through this whole exercise all over again. While this blog focuses on our considerations for 100GbE switches, there are interesting advances being made for server connectivity as well. As server technology matures, our caches will eventually scale beyond existing 10GbE interfaces. Considering this, switch platforms based on the Jericho chipset which provide incredible 100GbE density in a small footprint become increasingly interesting for our ever-evolving designs.
As a network engineer at Fastly, the future is pretty exciting. The next celebratory milestone for our team will likely be when we hit 2 terabits per second. But what we serve is just a fraction of the overall capacity we build for our customers in order to support high-traffic events (like the Super Bowl), protect them from DDoS attacks, and so on. Network engineers get a kick out of big bandwidth, but our team is far more fired up by finding creative solutions to implement, abstract, and efficiently utilize that capacity for the benefit of our customers. We’ve got some seriously brilliant people here solving those problems, and we’re hiring. I’d love to hear from you.