
One of the keys to a clean, clear live-streaming experience is properly managing network congestion — something our platform performs mostly automatically, around the clock, and with reduced human intervention. As part of Fox Sports’ live event streaming team for Super Bowl LIV, we were able to watch this automation work its magic during one of the internet’s biggest days of the year. Here’s a step-by-step look at how network automation, a small team of engineers, and key learnings from past extreme high-traffic moments allow us to support our customers’ performance at scale.
Automation + expert humans: the dream team
Our live-streaming process begins with our direct connectivity to numerous ISPs across the country. We do everything we can to keep our live video traffic on these direct paths with our interconnect partners to deliver video streams as close to the end-user as possible. But at some point, as traffic demand increases, these interconnection points often start to become congested. Once congestion hits, quality suffers. Live streaming viewers can experience performance issues like video buffering or reduced stream quality as a result of packet loss — with more than half of them abandoning a poor online broadcast experience in 90 seconds or less.
At this point, our built-in network automation — dubbed internally as Auto Peer Slasher, or APS — activates. This orchestration is underpinned by StackStorm, and we hope to share an under-the-hood look at how exactly that is built in a future post.
Recognizing that link utilization is nearing full capacity, APS kicks in, triggered by an alert to our team while automatically diverting a small portion of traffic in order to keep the link under congestion thresholds. This traffic is then automatically rerouted via alternate best paths to the given ISP, typically via IP transit. With big-time live streaming traffic, this can happen multiple times in a matter of minutes, causing the platform to shed traffic from interconnect partners to IP transit again and again. In most cases, the connection state is maintained, eliminating the need for the player to restart a session from scratch.
An example of this process in motion is shown below. Upon receiving an alert, APS executed a specific workflow, taking multiple actions on links to an ISP in the Washington D.C. metro area, while reporting back to our team via Slack.

In the graph below, we can see that each time these links near 90% utilization, APS slices off just enough traffic to keep the links out of the congestion zone.
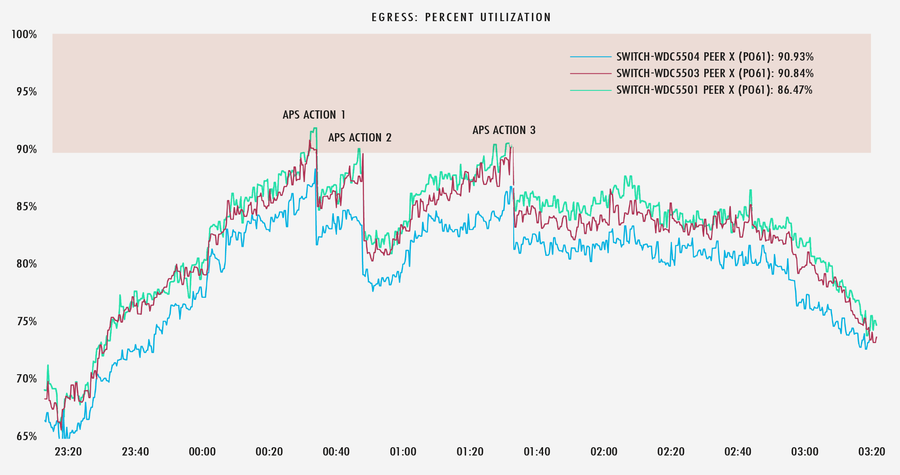
Toward the end of a live event, as peak traffic declines, APS knows to unwind those actions, and we start back at square one, so to say.
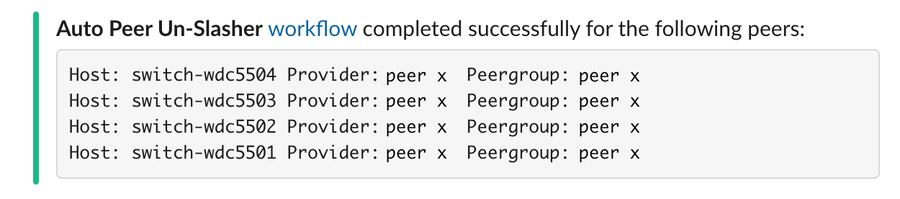
But link utilization is only one measure and doesn’t necessarily speak to any potential congestion deep inside certain backbones or ISP networks. Rates of loss and retransmissions are extremely useful pieces of information, which we observe and take action on in real time with another technique we call Fast Path Failover (FPF). Our edge caches keep tabs on the forward progress of individual end-user TCP flows. If the flow appears to stall via one given path, the cache will trigger an automatic attempt to forward the flow via an alternate path, hoping to maintain a stable state and connection quality.
When the amount of automatically diverted traffic exceeds the available capacity of alternate paths, or if FPF is unable to find uncongested alternate paths, we have to make a decision about how to reroute traffic next. And that’s where our people come into play.
We’ve learned from past major events that additional complexity to traffic engineering is introduced by an “all hands on deck” approach. While the talented network engineering team at Fastly is already an incredibly lean and efficient group, we reduce the number of engineers at the controls even further for major live events — on average, we pare down to about 12 members strong. We break the geography into quadrants and assign a lead engineer to each. Each lead engineer is partnered with a co-pilot engineer who keeps an eye on alerts and thresholds, feeding information to their quadrant leader as necessary while providing secondary validation and verification of changes made by the lead. When our automatic shifting of traffic from direct ISP links begins to reach upper limits of available point of presence (POP) capacity, the engineering pair works together to decide how and where to migrate traffic next, usually by altering our border gateway protocol (BGP) anycast announcements or influencing end-user POP selection via our domain naming system (DNS) management platform. And so goes the process, all going on behind the scenes to ensure a crisp, real-time delivery of any live event.
Putting the process into practice
The automation and systems described above run all day, every day — an enduring improvement that benefits all of our customers during peak-traffic moments. Nevertheless, we always get excited to see how it performs during big traffic surges, and while preparing for major live streaming events.
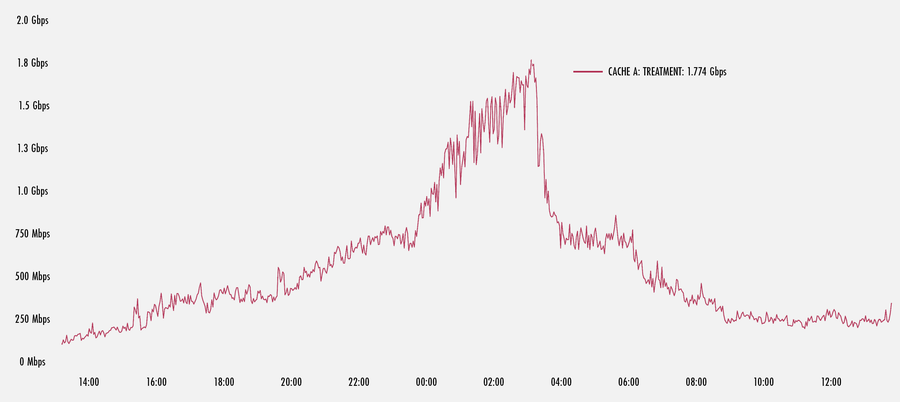
As you can see in the graph below, a major surge in traffic on one of our U.S. POPs caused FPF to kick into gear. Here, we see one cache in the POP pushing FPF flows at nearly a 1.8 Gbps peak until the surge event ends. This is just a small percentage of the total traffic served by this one machine. But if extrapolated across many machines in a POP, the total traffic receiving treatment can be quite high.
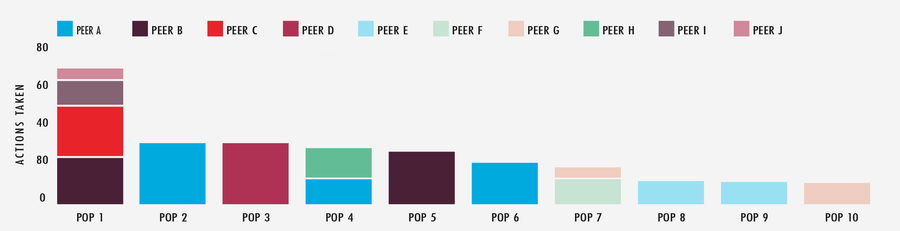
Studying another major multi-day event, we can see the significant impact our APS system has. Looking at a 48-hour period across the 10 most active POPs and interconnect partners, APS performed a total of 349 actions against the network. With APS doing a lot of the heavy lifting, the team spends their energy fine-tuning some of the system’s choices, while focusing their attention on other elements of the edge cloud platform’s performance.
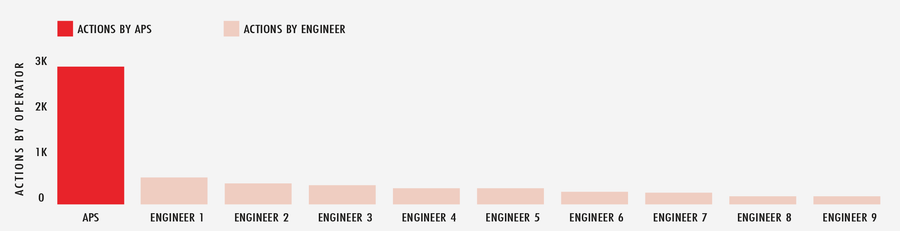
If we look more holistically at the entire month of February, 2020, APS carried out more than 2,900 automated actions across the global network in response to ever-changing internet conditions, while the next closest on-call engineer clocked in just above 500. In short, APS is like having plenty of extra players on the field.
Live-streaming success in 3, 2 ...
Streaming high-traffic live events is a serious undertaking. But with built-in automation, a talented group of engineers, and a powerful network behind it, our platform is designed to handle them just as well as it handles a typical Tuesday. We understand the capacity, technology, and preparation needed so that our customers can embark on each big moment with a sense of excitement, knowing their name, reputation, and quality of experience is in good hands.